






在科技飞速发展的今天,人工智能(AI)已经成为一个热门话题。其中,ChatGPT 以其强大的自然语言处理能力,吸引了全球范围的关注。它从大型数据集中学习模式和示例,创建或生成新的内容,例如文本、图像,甚至音乐和视频。
然而,在追捧 ChatGPT 的同时,我们也需要保持冷静,理性看待这一技术,避免成为盲目跟风的“韭菜”。
那么,ChatGPT 能否显著提高人类的生产力呢?程序员张无剑使用 ChatGPT 来解决他遇到的一些问题的经历或许可以给我们一些启发……
1ChatGPT 能提高人类生产力?
嗷嗷喜欢熬夜,夜夜夜夜,夜夜辗转难眠的程序员张无剑躺在床上,准备再刷 5 分钟手机就睡觉,一打开手机就看到了小红书要裁员的热搜消息。
张无剑居安思危,想系统化地学习 Redis 技术,提高自己的竞争力。网络上铺天盖地地宣传 ChatGPT 强大,就计划用 ChatGPT 来搞一把。
在询问之前,张无剑花了很多时间研究如何更好地给出提示语,因为没有好的提示语,ChatGPT 给出的答案可能有点“智障”。

张无剑绞尽脑汁想了一个提示语喂给 ChatGPT。
假如你是一个资深 Redis 7.0 技术培训老师,我是你的学生,学习内容为“Redis 数据类型 List 底层实现原理和实战技巧” ,我的目标是掌握这些数据类型的底层实现原理和实战技巧,原理讲解要深入一些,我的目标是成为 Redis 高手。
ChatGPT 的回复如下。

张无剑内心嘀咕道:这也太简单了,看起来好像说明了底层原理,但总觉得还不够深入,只能大概了解 Redis 的 List 数据类型,根本成不了 Redis 高手,花了这么多时间,就这???
“人工智能教父”杨立昆说过:ChatGPT 没那么厉害!果然是真的。

张无剑遇到的问题在于以下几点。
- 无图无真相,无法理解 List 底层的两种数据结构(Linkedlist、Ziplist)到底是啥样的,内容不够深。
- 无法理解为什么 List 要用两种数据结构(Linkedlist、Ziplist)保存数据(实际上底层数据结构不止这两种,出现了错误)。
- 语言生硬,也就是从我们说的 AI 味太冲,学习本就是件痛苦的事情,在这样的枯燥文字中还如何学下去。
- 还要花费大量时间来调教 ChatGPT 纠正错误,可本身自己是来学习的,如何纠正呢?
2欲练此功不必自宫只需放松
Redis 看到张无剑使用 ChatGPT 来学习 Redis,快急死了。因为 ChatGPT 回复的内容存在错误!再继续学习下去怕是容易走火入魔!
Redis 化身成人,开始解答张无剑学习 Redis 的困惑,并推荐张无剑一本至高心法学习,它就是《Redis 高手心法》。
该心法从 Redis 的第一人称视角出发,以拟人故事化的方式和诙谐幽默的语言与各路“神仙”对话,配合 158 张图片,由浅入深循序渐进地讲解 Redis 的数据结构实现原理、开发技巧、运维技术和高阶使用,让人轻松愉快地学习。
将复杂的概念与实际案例相结合,让理论原理与实战相结合,以简洁诙谐幽默的方式配以大量撩人心弦又准确的图片,为你揭示 Redis 的精髓。哪怕是“天阶高级”斗技,也能愉快地修炼,而不会走火入魔。
这是心法的全局大纲,一个字“绝”。
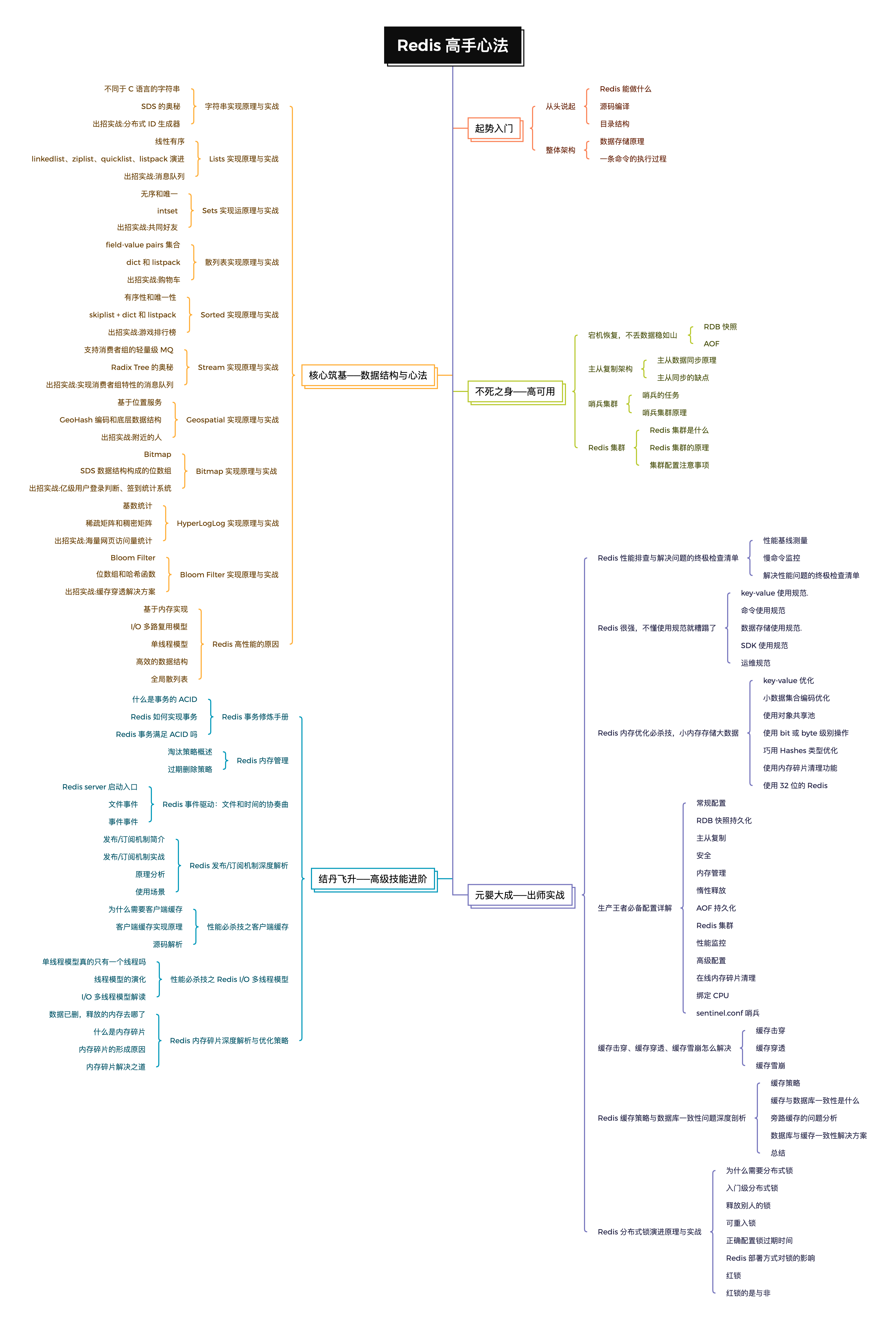
篇幅有限,我列举《Redis 高手心法》的部分内容给你修炼……
3Redis Lists 底层数据结构演进
Redis 说道:“我支持很多种数据类型,对于不同的数据类型,底层用了多种数据结构来实现存储。”
我给开发者提供了 String(字符串)、Hashes(散列表)、Lists(列表)、Sets(无序集合)、Sorted Sets(可根据范围查询的排序集合)、Bitmap(位图)、HyperLogLog、Geospatial(地理空间)和 Stream(流)等数据类型。
为了在速度和内存占用之间找到最优解,我设计了多种数据结构。总之为了实现多快好省(支持数据类型多、速度快、好用、节省内存)。
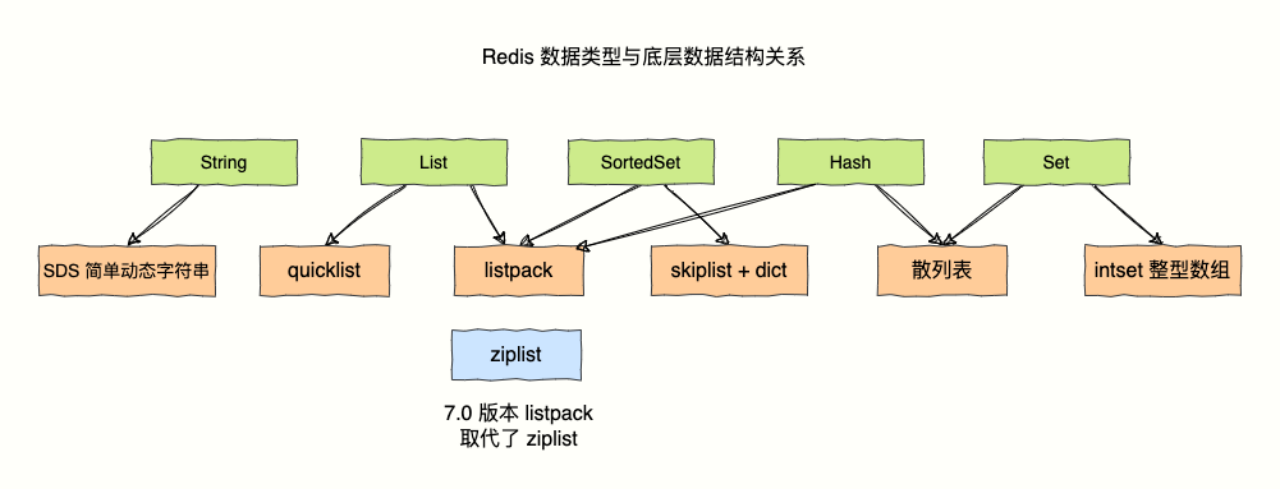
Redis:ChatGPT 回复你关于 Lists 实现原理有错误,实际上是这样的……
在 C 语言中,并没有现成的链表结构,所以 Antirez 为我专门设计了一套实现方式。
关于 Lists 类型的底层数据结构,可谓英雄辈出,Antirez 大佬一直在优化,创造了多种用来保存的数据结构。
包括早期作为 Lists 的底层实现的 linkedlist(双端链表)和 ziplist(压缩列表),Redis 3.2 引入的由 linkedlist 和 ziplist 组成的 quicklist,以及 7.0 版本中取代了 ziplist 的 listpack。
张无剑:“为什么弄了这么多数据结构呀?”
Antirez 所做的这一切都是为了在内存空间开销与访问性能之间做取舍和平衡,跟着我去
“吃透”每个类型的设计思想和不足,你就明白了。
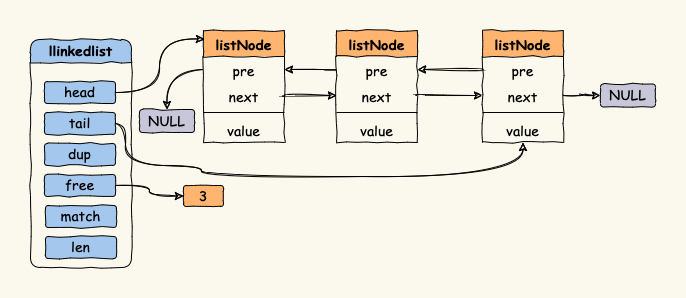
3.1linkedlist
在 Redis3.2 之前,Lists 的底层数据结构由 linkedlist 或者 ziplist 实现,优先使用 ziplist 存储。当 Lists 对象满足以下两个条件时,将使用 ziplist 存储链表,否则使用 linkedlist。
◎ 链表中的每个元素占用的字节数小于 64。
◎ 链表的元素数量小于 512 个。
张无剑:看起来没什么问题呀,为什么还要 ziplist 呢?
你知道的,我在追求快和节省内存的方向上无所不及,有两个原因导致了 ziplist 的诞生。
◎ 普通的 linkedlist 有 prev、next 两个指针,在数据很小的情况下,指针占用的空间会 超过数据占用的空间,这就离谱了,是可忍,孰不可忍。
◎ linkedlist 是链表结构,在内存中不是连续的,遍历的效率低下。
3.2ziplist
为了解决上面两个问题,Antirez 创造了 ziplist,这是一种内存紧凑的数据结构,占用一块 连续的内存空间,能够提升内存使用率。ziplist 有多个 entry 节点,可以存放整数或者字符串,结构如图所示。
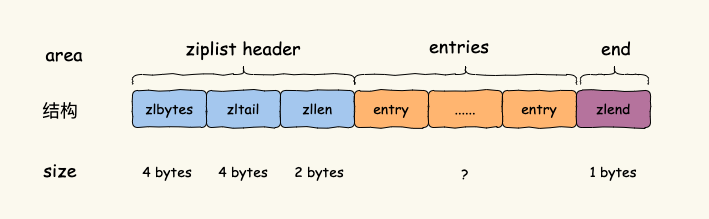
ziplist 头尾元数据的大小是固定的,并且 zllen 记录了 ziplist 头部最后一个元素的位 置,所以,能以 O(1) 的时间复杂度找到 ziplist 中第一个或最后一个元素。而在查找中间元素 时,只能从 Lists 头或者 Lists 尾遍历,时间复杂度是 O(N)。
张无剑:“听起来很完美,为什么还要搞 quicklist ?”
“既要又要还要”的需求是很难实现的,ziplist 节省了内存,但是也有不足。
◎ 不能保存过多的元素,否则查询性能会大大降低,导致 O(N) 时间复杂度。
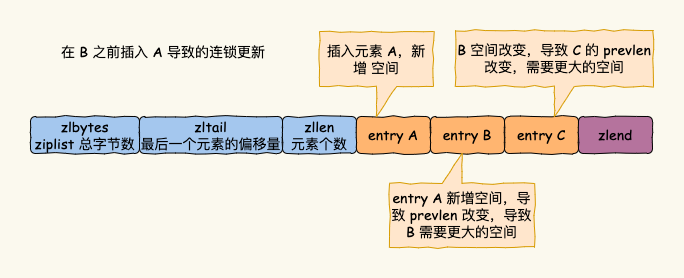
◎ ziplist 的存储空间是连续的,当插入新的 entry 时,内存空间不足就需要重新分配一块连续的内存空间,引发连锁更新的问题。
每个 entry 都用 prevlen 记录上一个 entry 的长度,在当前 entry B 前面插入一个新的 entry A 时,会导致 B 的 prevlen 改变,也会导致 entry B 的大小发生变化。entry B 后一个 entry C 的 prevlen 也需要改变。
3.3quicklist
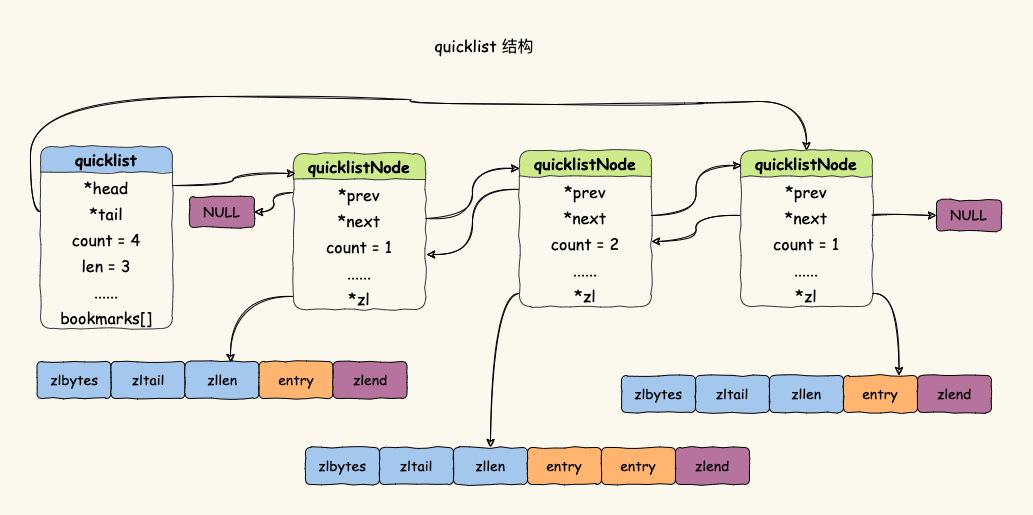
连锁更新会导致多次重新分配 ziplist 的内存空间,直接影响 ziplist 的查询性能。于是, Redis 3.2 引入了 quicklist。quicklist 是综合考虑了时间效率与空间效率引入的新型数据结构。它结合了 linkedlist 与 ziplist 的优势,本质还是一个链表,只不过链表的每个节点都是一个 ziplist。
3.4listpack
张无剑:搞了半天还是没能解决连锁更新的问题嘛。
别急,饭要一口一口吃,路要一步一步走,步子迈大了容易摔跟头。ziplist 是紧凑型数据结构,可以有效利用内存。但是每个 entry 都用 prevlen 保留了上一 个 entry 的长度,所以在插入或者更新时可能出现连锁更新影响效率。
于是 Antirez 又设计出了“链表 + ziplist”组成的 quicklist 来避免单个 ziplist 过大,缩 小连锁更新的影响范围。可毕竟还是使用了 ziplist,本质上无法避免连锁更新的问题。于是, 5.0 版本设计出另一个内存紧凑型数据结构 listpack,并在 7.0 版本中替换掉 ziplist。
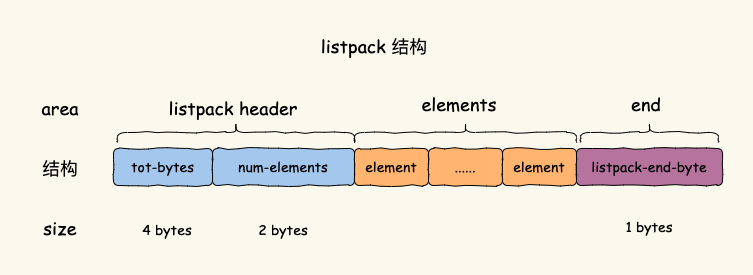
listpack 与 ziplist 最大的区别是 elements 部分, 为了解决 ziplist 连锁更新的问题,element 不再像 ziplist 的 entry 保存前一项的长度。
4RDB 快照与 AOF 实现持久化
Chaya:Redis 数据保存在内存,如果没有持久化,一旦断电或者宕机,保存在内存中的数据将全部丢失,咋办呢?
我有两大撒手锏,可以实现数据持久化,做到宕机快速恢复,“不丢数据稳如山”,无须从数据库中慢慢恢复数据。它们就是 RDB 快照和 AOF(Append Only File)。
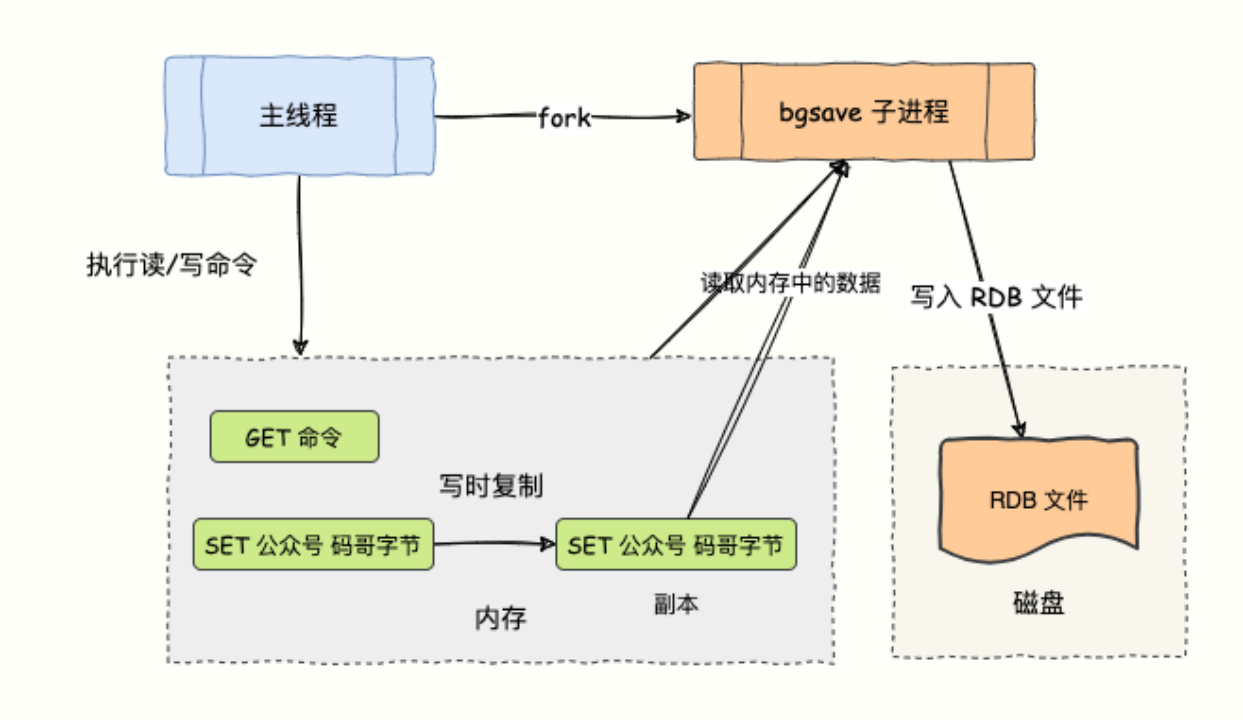
MySQL:“在实际生产环境中,程序员通常会给你配置 6GB 的内存,将这么大的内存数据生成 RDB 快照文件落到磁盘的过程会持续比较长的时间。你如何做到在继续处理写命令请求的同时保证 RDB 与内存中的数据一致呢?”
作为唯快不破的 NoSQL 数据库扛把子,我在对内存数据做快照时,并不会暂停写操作(读操作不会造成数据的不一致)。我使用了操作系统的多进程写时复制技术(Copy On Write ,COW)来实现快照持久化。
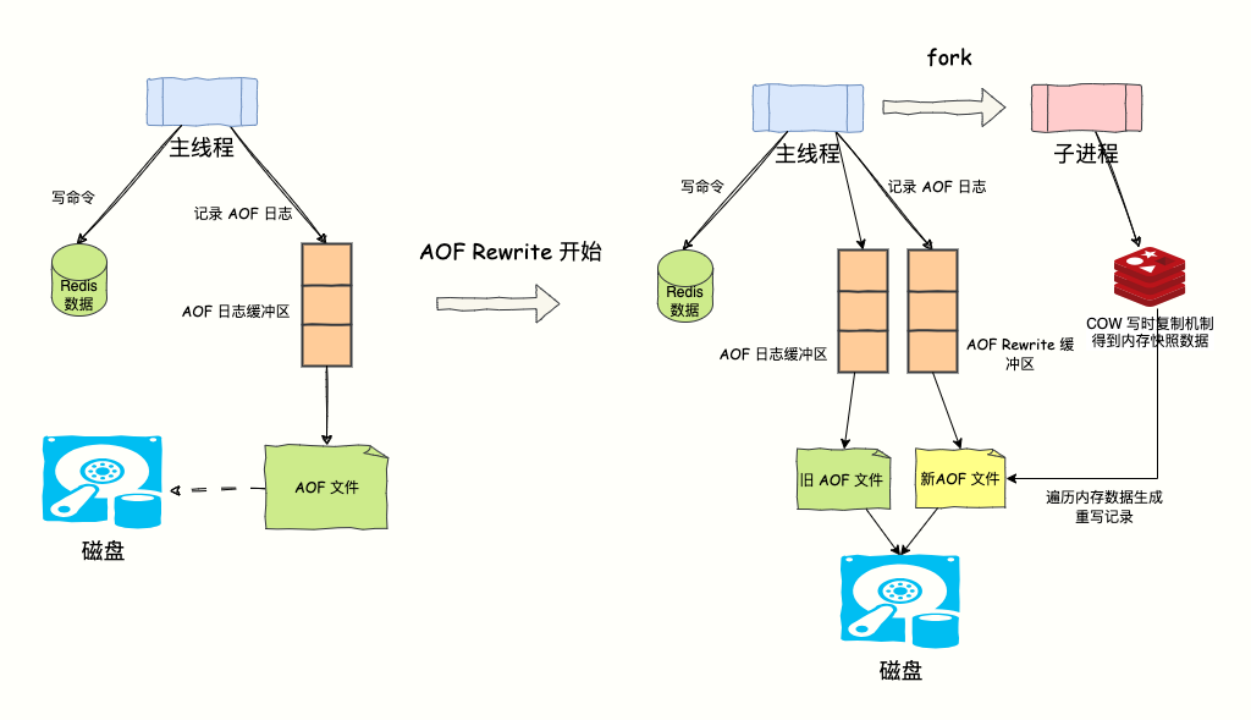
Chaya:“随着写入操作持续执行,AOF 日志过大怎么办?文件越大,数据恢复就越慢。”
为了解决 AOF 文件体积膨胀的问题,创造我的 Antirez 老哥设计了 AOF 重写机制(AOF Rewrite),对文件进行瘦身。
5主从复制架构
Chaya:“有了 RDB 快照和 AOF 再也不怕宕机丢失数据了,但是 Redis 实例宕机了怎么办?如何实现高可用呢?”
Chaya 愣了一会儿,又赶紧补充道:“依然记得那晚我和我的恋人鸳语轻传,香风急促,走在成都的街头约会。可是这时候 Redis 忽然宕机了,无法对外提供服务,电话连环 call,岂不是折煞人也“。
莫怕,为了你们的幸福。我提供了主从模式,通过主从复制,将一份冗余数据复制到其他 Redis 服务器,实现高可用。你们放心地说温存,说风月。
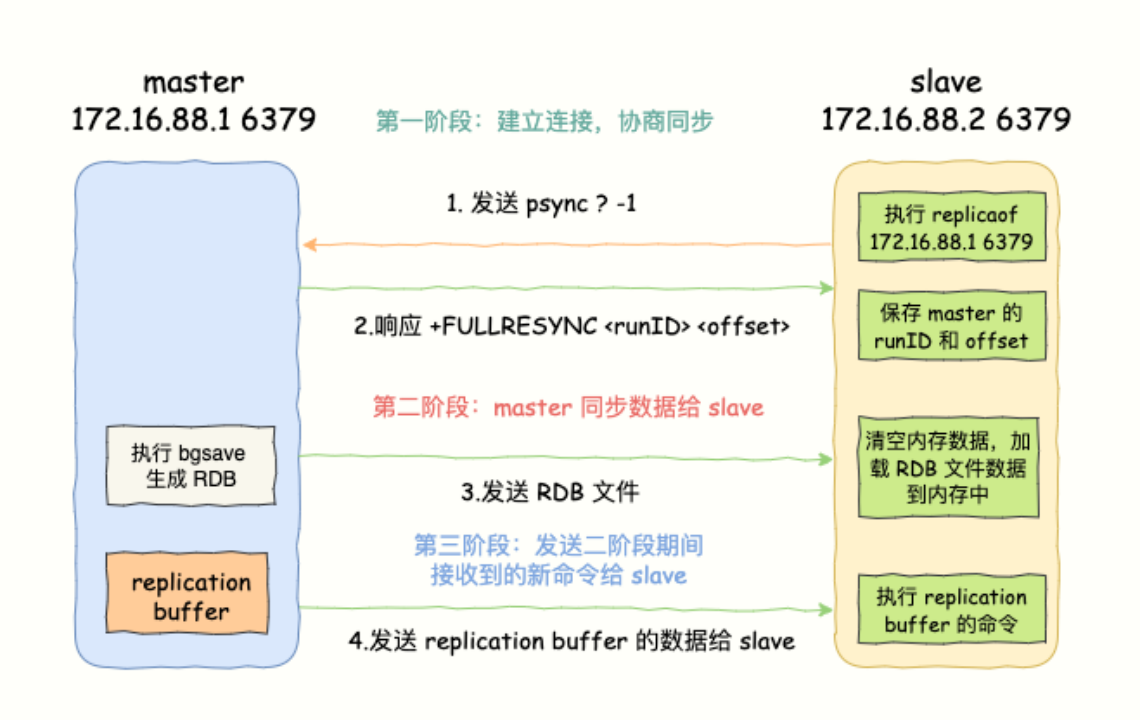
Chaya:“master 和 slave 的同步是如何完成的呢?master 的数据是一次性传给 slave,还是分批同步?主从正常运行期间又怎么同步呢?要是 master 和 slave 间的网络断连了,重新连接后数据还能保持一致吗?”
你问题怎么这么多?不要急。我知道你想安心地与恋人相会,不受 Redis 宕机导致的服务报警的干扰。主从数据同步分为 4 种情况。
◎ master 和 slave 第一次全量同步。
◎ master 和 slave 正常运行期间的数据同步。
◎ master 和 slave 网络断开重连同步。
主从库第一次复制过程大体可以分为 3 个阶段:建立连接阶段(准备阶段)、同步数据阶段、发送同步期间接收的新写命令到 slave 阶段。
篇幅有限,不再一一列举……
6心法问世,“化神”专家赞誉
《Redis 高手心法》问世,得到了一些“化神”大佬的赞誉。

看下本书的实拍图

















 6539
6539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









