








来源:cnblogs.com/yangming1996/p/8031199.html
一、历史版本的实现演变
二、重要成员属性的介绍
三、put 方法实现并发添加
四、remove 方法实现并发删除
五、其他的一些常用方法的基本介绍
HashMap 是我们日常最常见的一种容器,它以键值对的形式完成对数据的存储,但众所周知,它在高并发的情境下是不安全的。尤其是在 jdk 1.8 之前,rehash 的过程中采用头插法转移结点,高并发下,多个线程同时操作一条链表将直接导致闭链,死循环并占满 CPU。
当然,jdk 1.8 以来,对 HashMap 的内部进行了很大的改进,采用数组+链表+红黑树来进行数据的存储。rehash 的过程也进行了改动,基于复制的算法思想,不直接操作原链,而是定义了两条链表分别完成对原链的结点分离操作,即使是多线程的情况下也是安全的。
当然,它毕竟不是并发容器,除非大改,否则依然是不能应对高并发场景的,或者说即使没有因多线程访问而造成什么问题,但是效率必然是受到影响的。例如在多线程同时添加元素的时候可能会丢失数据,迭代 map 的时候发生 fail-fast 等。
本篇文章将要介绍的 ConcurrentHashMap 是 HashMap 的并发版本,它是线程安全的,并且在高并发的情境下,性能优于 HashMap 很多。我们主要从以下几个方面对其进行学习:
历史版本的实现演变
重要成员属性的介绍
put 方法实现并发添加
remove 方法实现并发删除
其他的一些方法的简单介绍一、历史版本的实现演变
jdk 1.7 采用分段锁技术,整个 Hash 表被分成多个段,每个段中会对应一个 Segment 段锁,段与段之间可以并发访问,但是多线程想要操作同一个段是需要获取锁的。所有的 put,get,remove 等方法都是根据键的 hash 值对应到相应的段中,然后尝试获取锁进行访问。
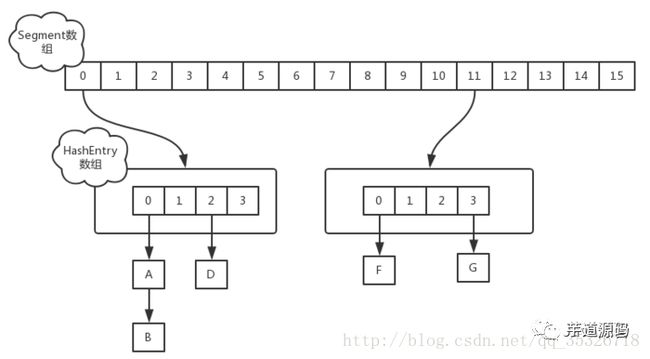
jdk 1.8 取消了基于 Segment 的分段锁思想,改用 CAS + synchronized 控制并发操作,在某些方面提升了性能。并且追随 1.8 版本的 HashMap 底层实现,使用数组+链表+红黑树进行数据存储。本篇主要介绍 1.8 版本的 ConcurrentHashMap 的具体实现。
二、重要成员属性的介绍 transient volatile Node[] table;
和 HashMap 中的语义一样,代表整个哈希表。
/**
* The next table to use; non-null only while resizing.
*/
private transient volatile Node[] nextTable;
这是一个连接表,用于哈希表扩容,扩容完成后会被重置为 null。
private transient volatile long baseCount;
该属性保存着整个哈希表中存储的所有的结点的个数总和,有点类似于 HashMap 的 size 属性。
private transient volatile int sizeCtl;
这是一个重要的属性,无论是初始化哈希表,还是扩容 rehash 的过程,都是需要依赖这个关键属性的。该属性有以下几种取值:
0:默认值
-1:代表哈希表正在进行初始化
大于0:相当于 HashMap 中的 threshold,表示阈值
小于-1:代表有多个线程正在进行扩容
该属性的使用还是有点复杂的,在我们分析扩容源码的时候再给予更加详尽的描述,此处了解其可取的几个值都分别代表着什么样的含义即可。
构造函数的实现也和我们之前介绍的 HashMap 的实现类似,此处不再赘述,贴出源码供大家比较。
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
其他常用的方法我们将在文末进行简单介绍,下面我们主要来分析下 ConcurrentHashMap 的一个核心方法 put,我们也会一并解决掉该方法中涉及到的扩容、辅助扩容,初始化哈希表等方法。
三、put 方法实现并发添加
对于 HashMap 来说,多线程并发添加元素会导致数据丢失等并发问题,那么 ConcurrentHashMap 又是如何做到并发添加的呢?
public V put(K key, V value) {
return putVal(key, value, false);
}
putVal 的方法比较多,我们分两个部分进行分析。
//第一部分
final V putVal(K key, V value, boolean onlyIfAbsent) {
//对传入的参数进行合法性判断
if (key == null || value == null) throw new NullPointerException();
//计算键所对应的 hash 值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node[] tab = table;;) {
Node f; int n, i, fh;
//如果哈希表还未初始化,那么初始化它
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//根据键的 hash 值找到哈希数组相应的索引位置
//如果为空,那么以CAS无锁式向该位置添加一个节点
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node(hash, key, value, null)))
break;
}
这里需要详细说明的只有 initTable 方法,这是一个初始化哈希表的操作,它同时只允许一个线程进行初始化操作。
private final Node[] initTable() {
Node[] tab; int sc;
//如果表为空才进行初始化操作
while ((tab = table) == null || tab.length == 0) {
//sizeCtl 小于零说明已经有线程正在进行初始化操作
//当前线程应该放弃 CPU 的使用
if ((sc = sizeCtl) < 0)
Threa
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1832
1832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









