






一、参数问题
1.分片数量不能修改。
因为每条数据的唯一document_id已经分配到各自的分片上。当利用document_id进行查找时,利用shard = hash(document_id) % (num_of_primary_shards)能定位到指定的分片。因此,一旦分片数量修改,将无法正确找到数据。
2.字段无法更改。
字段名字和字段类型一旦生成,无法更改。只能通过重新构建新的数据索引,然后把旧的数据复制到新的数据结构中(该操作建议在测试环境中使用,线上环境尽量慎重)。
3.写入的数据默认1s后才能查询。
如果在代码中做写入,然后需要马上查,此时会出问题。ES的默认refresh时间为1s。"refresh_interval": "1s"
4.写入时会检查版本号,并发可能会有冲突。
ES作为一种数据存储的方式,和mysql或其他数据库一样,也会存在并发冲突。可以加锁解决
5.分页越深,查询效率越慢。
ES读取数据分为两个阶段:
1.Query Phase:获得查询的协调节点会把请求发送给所有的分片,分片将满足条件的Document id返回给协调节点。协调节点将结果集排序。
2.Fetch Phase:协调节点根据拿到的Document id,再向分片请求具体的数据。最有协调节点将结果汇总并返回。
但是实际的Fetch Phase过程中,协调节点收到的数据是shards number*(from+size)条。排序后再返回客户端size大小的数据。
eg:假设有3个分片,查询200到220(from=200,size=20)。则每个分片返回了220条数据。即协调节点内要计算并排序(200+20)*3条数据。随着分片数量和查询id变大,协调节点中需要计算和排序的量就越大。因此,分页查询越深,查询速度越慢。
二、使用遇到的问题
1.【报错】:maxClauseCount is set to 1024
分析:query的参数中总数据量只能为1024,超过就会报错maxClauseCount is set to 1024。
解决:将query的参数调整到filter中
2.【报错】:failed to parse [time] IllegalArgumentException Invalid format: ‘2023/05/30’ is malformed at ‘05/30’
分析:是因为该数据对应的字段不支持写入这个格式的数据
解决:将"2023/05/30"改为支持写入的格式,本人的配置未指定,是默认的,因此改为"2023-05-30"即可保存
另外,提供默认支持的日期格式,亲测是有效的:
2023-02-24T12:00:00
2023-02
2013-W06-5
2013-039
20130208
2013
2013050
2013-02-08T09
2017-12-14T16:34
2017-12-14T16:34:10.234
2017-W50
2013-02-04T10:35:24-08:00
2013-02-04T18:35:24+00:00
3.【报错】:Limit of total fields [1000] in index has been exceeded
分析:ElasticSearch默认的字段数量是1000,如果你新建的索引数据超过1000,就会报错
解决:
使用Kibana平台执行:
PUT 唯一的索引名(/唯一的别名)/_settings
{
"index.mapping.total_fields.limit":2000
}
再查看配置:
GET 唯一的索引名(/唯一的别名)/_settings
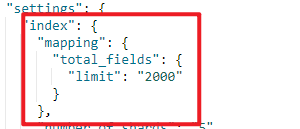
就能看到多了下图中的配置(如果未执行上一步,查看配置是无法看到以下内容的)
updateTime:2024.02.07















 1384
1384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









