






Distilling the Knowledge in a Neural Network
神经网络中的知识蒸馏
我们知道,一定程度上,网络越深,参数越多,模型也会越复杂,但其最终效果也越好,而模型压缩算法是旨在将一个庞大而复杂的大模型转化为一个精简的小模型。之所以必须做模型压缩,是因为嵌入式设备的算力和内存有限,经过压缩后的模型方才能部署到嵌入式设备上。
主要的压缩方法有:知识蒸馏、轻量化模型架构、剪枝、量化。
摘要
多模型集成能显著提升机器学习性能,但是集成学习训练会耗费很大的算力,尤其是当它需要部署到很多用户端时。
Caruana 发现可以把集成学习到的知识压缩到单个模型中从而很容易的部署到多用户端。这种模型压缩的方法叫知识蒸馏。知识蒸馏在MNIST手写数据集上得到了很好的效果,也能把改善语音模型的效果。提出了一个新的模型集成范式包括一个多用模型和一个专用模型(用于区分自己领域的细粒度问题)。
一、介绍
引用昆虫的例子幼虫和成虫的生存需求不同,而在大规模机器学习领域中训练和部署都用相似的模型,尽管训练和部署的需求是完全不一样的。我们可以训练非常复杂的模型,其易于从数据中提取出结构。
训练的目标是能够通过海量的数据和算力构建一个算法,不需要将模型部署在应用终端部署的目标是希望模型较少的延时,较少耗费计算资源
所以本文思考在训练时用相对笨重的模型来提取模型的知识
笨重模型可以是很多机器学习训练的集成也可以是一个大模型(用droupout和正则化来防止过拟合)
一但笨重模型训练完成,我们可以用知识蒸馏的压缩技巧把笨重模型中训练的特征迁移到小模型中。迁移到的小模型更适合部署。之前的工作已经证明了一个大模型的知识可以迁移到小模型上。
通常我们认为,模型学习到的参数代表了知识但其实不是,知识是指笨重网络中预测结果中各类别概率的相对大小。比如在大模型中预测西瓜,然后西瓜的概率是0.8,哈密瓜是0.6,西红柿是0.3,这些概率值相对大小的关系是知识。也就是输入特征向量到输出特征向量的映射。
大模型一般用交叉熵损失函数来预测多类别,比如有猫,狗,兔子三个类别,标签用one-hot编码表示A标签:(1,0,0)对应概率值是0.7,0.5,0.3 表示类别是猫且猫的概率是0.7,其余狗和兔子的概率分别为0.5和0.3B标签:(0,1,0)对应的概率为0.5,0.6,0.1C标签:(0,0,1)对应的概率为0.1,0.4,0.23个图片全部预测正确的概率为0.7*0.6*0.2,这个概率叫做似然概率,我们优化的目标是最大化这个正确的概率也就是最大化似然概率。但这样相乘的结果太小,需要将它取对数log0.7*0.6*0.2=log0.7+log0.6+log0.2这个结果越大预测全部正确的准确度越高,但这个结果为负数,我们不希望它是负数所以取负号-log0.7-log0.6-log0.2这个结果越小预测正确的准确度越高
通常训练的损失函数要反应真正的性能准确度,(交叉熵损失就能很好地反映,上面介绍了)。真正好的模型不是在训练集上有好的准确度,而应该是在测试集上表现更好。
泛化能力:就是模型对新鲜样本下的适应能力。也就是在测试集上的表现能力,如果模型在训练集上表现好,在测试集上表现不好就是过拟合
那么当我们能很好地将大模型学习到的知识定义和量化出来迁移给小模型,就能让小模型拟合相同的知识,才有更好的泛化能力。
那么如何让小模型学习大模型的知识呢?
一个好方法是直接让大模型预测出的结果作为学生网络的标签去学习(用大模型的soft target作为学生网络的label)
soft target:(软标签)软标签也是label的概率分布,只不过软标签携带的信息更多了。通俗解释就是标签信息不是非0及1了,当图片不是某一类别时会取很小概率,当图片是某一类别时会取很大概率有软标签后label变为A(0.8,0.02,0.03)对应概率为0.7,0.5,0.3计算的交叉熵损失:-0.8*log0.7-0.02*log0.5-0.03*log0.3,可以看出携带的信息量更大了,这些信息量传给小模型,可以让小模型学到更多知识
但是soft target有时的类别概率太小了,接近0的话意义也不大。所以本文使用提高温度来让soft target更平均。
总结:知识蒸馏可以使用教师网络用温度T来蒸馏得到的soft target,再用学生网络相同的温度T蒸馏出的soft target互相拟合。
当大模型训练好后,我们可以在大模型中训练的无标注的数据集,来获得数据集的soft target,再用这个soft target训练小模型
二、蒸馏算法
神经网络通常使用softmax方法生成类别概率。
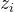 是类别的概率分数,
是类别的概率分数,
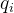 是soft target后得到的概率。soft target的公式如下:
是soft target后得到的概率。soft target的公式如下:
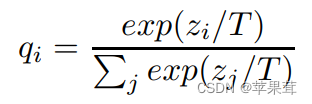
当T=1时,就是没有加soft target效果的概率
当T越大概率越平滑,那么迁移到学生模型的标签越平滑
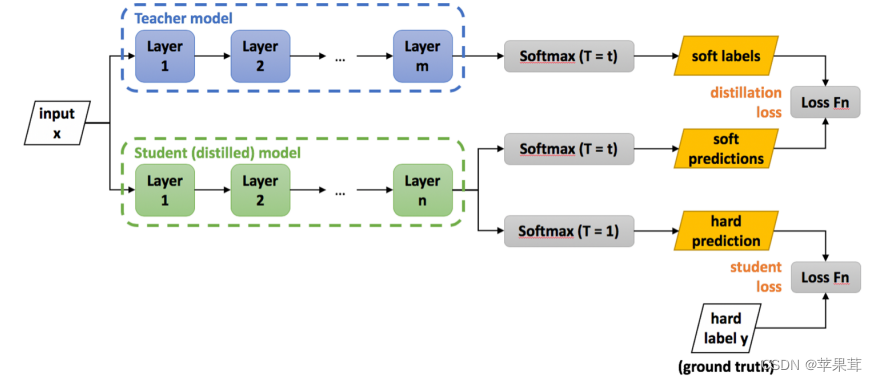
知识蒸馏算法步骤:
1、教师网络训练模型并在T=t时,得到soft labels,学生网络也训练模型用相同的温度t和教师网络的soft labels进行拟合。计算soft labels的损失函数
2、学生网络在T=1时训练,得到hard labels,计算hard labels的损失函数。
3、对soft loss和hard loss加权求和。
4、预测阶段在T=1的学生网络直接预测
注意:T设置的过高虽然传递的有用信息更多,但是错误类别的概率过高,容易产生噪音T设置的过低错误类别概率接近于0,起不到太大作用















 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









