







 本文详细介绍了Scrapy中的Item Pipeline,包括其在数据处理流程中的位置、主要功能,以及如何自定义Pipeline组件。文章通过实例演示了如何使用Pipeline实现MongoDB、MySQL存储以及图片下载,讲解了process_item、open_spider、close_spider等核心方法的用法,并展示了如何配置和启用Pipeline以实现高效的数据处理和存储。
本文详细介绍了Scrapy中的Item Pipeline,包括其在数据处理流程中的位置、主要功能,以及如何自定义Pipeline组件。文章通过实例演示了如何使用Pipeline实现MongoDB、MySQL存储以及图片下载,讲解了process_item、open_spider、close_spider等核心方法的用法,并展示了如何配置和启用Pipeline以实现高效的数据处理和存储。
Item Pipeline是项目管道,本节我们详细了解它的用法。
首先我们看看Item Pipeline在Scrapy中的架构,如下图所示。
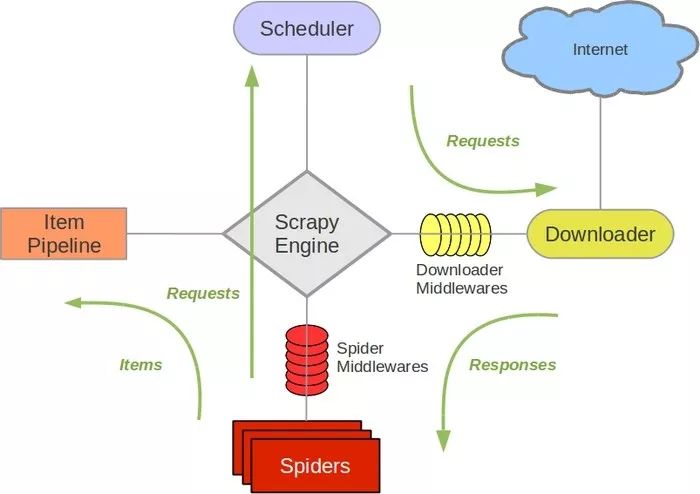
图中的最左侧即为Item Pipeline,它的调用发生在Spider产生Item之后。当Spider解析完Response之后,Item就会传递到Item Pipeline,被定义的Item Pipeline组件会顺次调用,完成一连串的处理过程,比如数据清洗、存储等。
Item Pipeline的主要功能有如下4点。清理HTML数据。
验证爬取数据,检查爬取字段。
查重并丢弃重复内容。
将爬取结果保存到数据库。
一、核心方法
我们可以自定义Item Pipeline,只需要实现指定的方法,其中必须要实现的一个方法是: process_item(item, spider)。
另外还有如下几个比较实用的方法。open_spider(spider)。
close_spider(spider)。
from_crawler(cls, crawler)。
下面我们详细介绍这几个方法的用法。
1.process_item(item, spider)
process_item()是必须要实现的方法,被定义的Item Pipeline会默认调用这个方法对Item进行处理。比如,我们可以进行数据处理或者将数据写入到数据库等操作。它必须返回Item类型的值或者抛出一个DropItem异常。
process_item()方法的参数有如下两个。item,是Item对象,即被处理的Item。
spider,是Spider对象,即生成该Item的Spider。
process_item()方法的返回类型归纳如下。如果它返回的是Item对象,那么此Item会被低优先级的Item Pipeline的process_item()方法处理,直到所有的方法被调用完毕。
如果它抛出的是DropItem异常,那么此Item会被丢弃,不再进行处理。
2.open_spider(self, spider)
open_spider()方法是在Spider开启的时候被自动调用的。在这里我们可以做一些初始化操作,如开启数据库连接等。其中,参数spider就是被开启的Spider对象。
3.close_spider(spider)
close_spider()方法是在Spider关闭的时候自动调用的。在这里我们可以做一些收尾工作,如关闭数据库连接等。其中,参数spider就是被关闭的Spider对象。
4. from_crawler(cls, crawler)
from_crawler()方法是一个类方法,用@classmethod标识,是一种依赖注入的方式。它的参数是crawler,通过crawler对象,我们可以拿到Scrapy的所有核心组件,如全局配置的每个信息,然后创建一个Pipeline实例。参数cls就是Class,最后返回一个Class实例。
下面我们用一个实例来加深对Item Pipeline用法的理解。
二、本节目标
我们以爬取360摄影美图为例,来分别实现MongoDB存储、MySQL存储、Image图片存储的三个Pipeline。
三、准备工作
请确保已经安装好MongoDB和MySQL数据库,安装好Python的PyMongo、PyMySQL、Scrapy框架。
四、抓取分析
我们这次爬取的目标网站为:https://image.so.com。打开此页面,切换到摄影页面,网页中呈现了许许多多的摄影美图。我们打开浏览器开发者工具,过滤器切换到XHR选项,然后下拉页面,可以看到下面就会呈现许多Ajax请求,如下图所示。
我们查看一个请求的详情,观察返回的数据结构,如下图所示。
返回格式是JSON。其中list字段就是一张张图片的详情信息,包含了30张图片的ID、名称、链接、缩略图等信息。另外观察Ajax请求的参数信息,有一个参数sn一直在变化,这个参数很明显就是偏移量。当sn为30时,返回的是前30张图片,sn为60时&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 206
206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









