






笔者刚学到python爬虫 无聊玩一玩
功能描述:
输入url
获取一系列的数据
在命令板输出
技术路线:requests>bs4
步骤:
List item
先从网上找到中国大学排名的url中国最好大学
分析其html结构
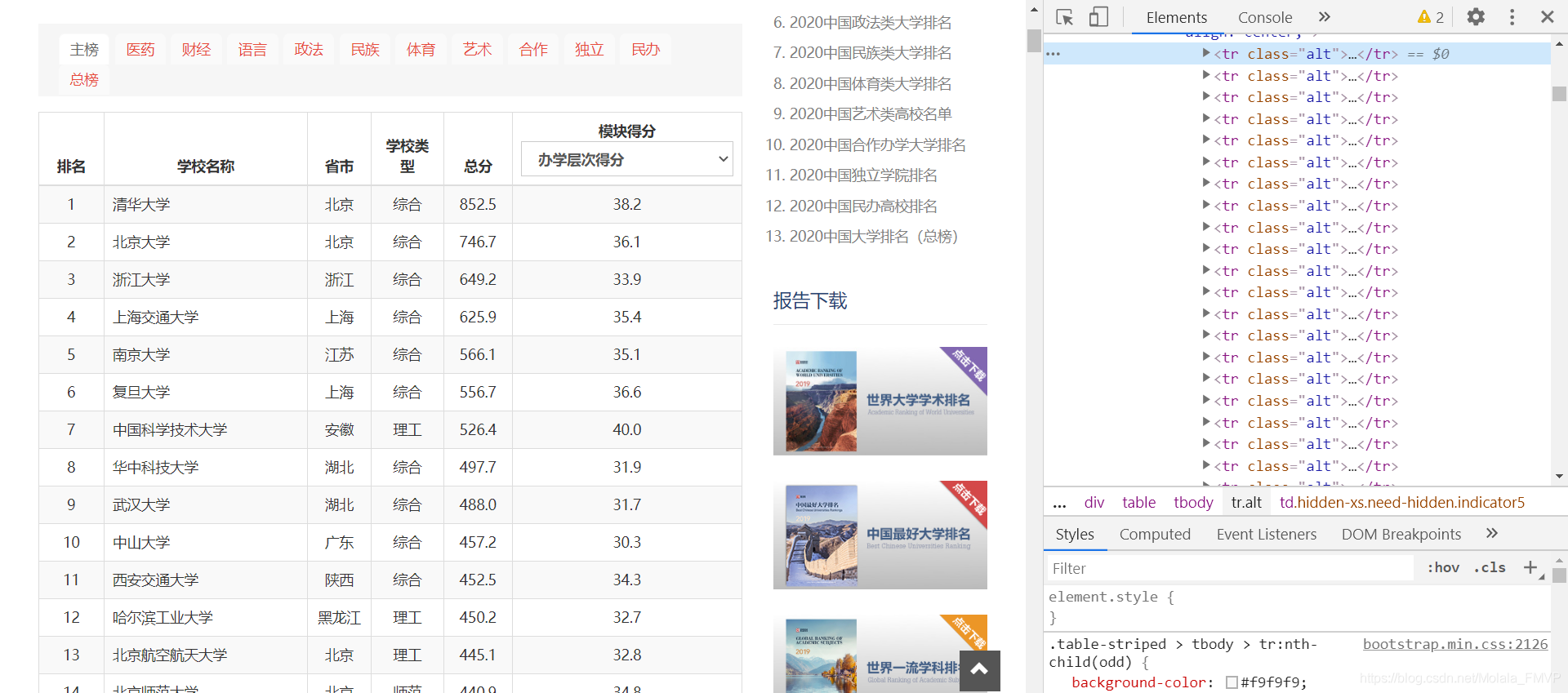

利用bs,做出一个list内嵌dict与tuple
import requests
from bs4 import BeautifulSoup
def getContent(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "爬取失败"
def makeSoup(content):
soup = BeautifulSoup(content, "html.parser")
return soup
def tackleContents(soup): # 由分析html结构得出
l = [] # 字典list
l1 = [] # 元组list
for i in soup.findAll(name="tr", class_="alt"):
# print(i)
d = {}
td_list = i.findAll(name="td")
d["ranking"] = int(td_list[0].string)
d["name"] = td_list[1].div.string
d["location"] = td_list[2].string
d["type"] = td_list[3].string
d["score"] = float(td_list[4].string)
t = (d["ranking"], d["name"], d["location"], d["type"], d["score"])
l.append(d)
l1.append(t)
return l, l1
将列表作为全局量,命令版控制查看
# 字典形式
def selectByName(name):
result = None
for r in l:
if r["name"] == name:
result = r
return result
if result is None:
return "无结果"
# 元组形式
def selectByNumber(number):
if 1<=number<=len(l1):
return l1[number-1]
else:
return "无结果"
最后用命令行(无聊形式)…
print("正在网上收取排名结果,请骚等...\n")
l, l1 = tackleContents(makeSoup(getContent("http://www.zuihaodaxue.com/zuihaodaxuepaiming2020.html")))
choice = None
while choice != '0':
choice = input("请输入您要查看的依据(1.校名、2.排名、0.退出):")
if choice == "1":
c = input("请输入您的校名:")
print(selectByName(c))
elif choice=="2":
n = input("请输入您的排名:")
print(selectByNumber(int(n)))
elif choice=="0":
break
else:
print("请输入正确的选项")
6.结果展示
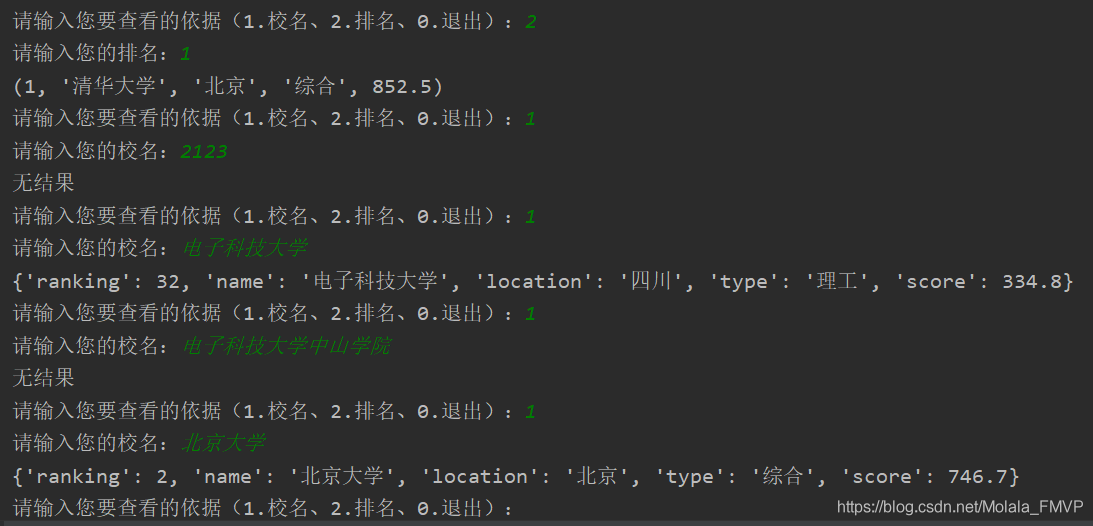
最后附上B站的排行榜(直接上代码)html结构分析可照着以下代码慢慢看就不放html图了
import requests
from bs4 import BeautifulSoup
# b站播放量
def get_content():
list1 = []
url = "https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3"
r = requests.get(url)
r.encoding = "utf-8"
soup = BeautifulSoup(r.text, "html.parser")
number = 0
for p in soup.findAll("div", class_="info"):
dict1 = {}
number += 1
a = p.find("a")
spans = p.findAll("span", class_="data-box")
if not spans:
continue
if not a:
continue
dict1.setdefault("name", a.get_text())
dict1.setdefault("wow", spans[0].get_text())
dict1.setdefault("comment", spans[1].get_text())
dict1.setdefault("link", a["href"])
list1.append(dict1)
return list1
for i in get_content():
print(i)
运行结果
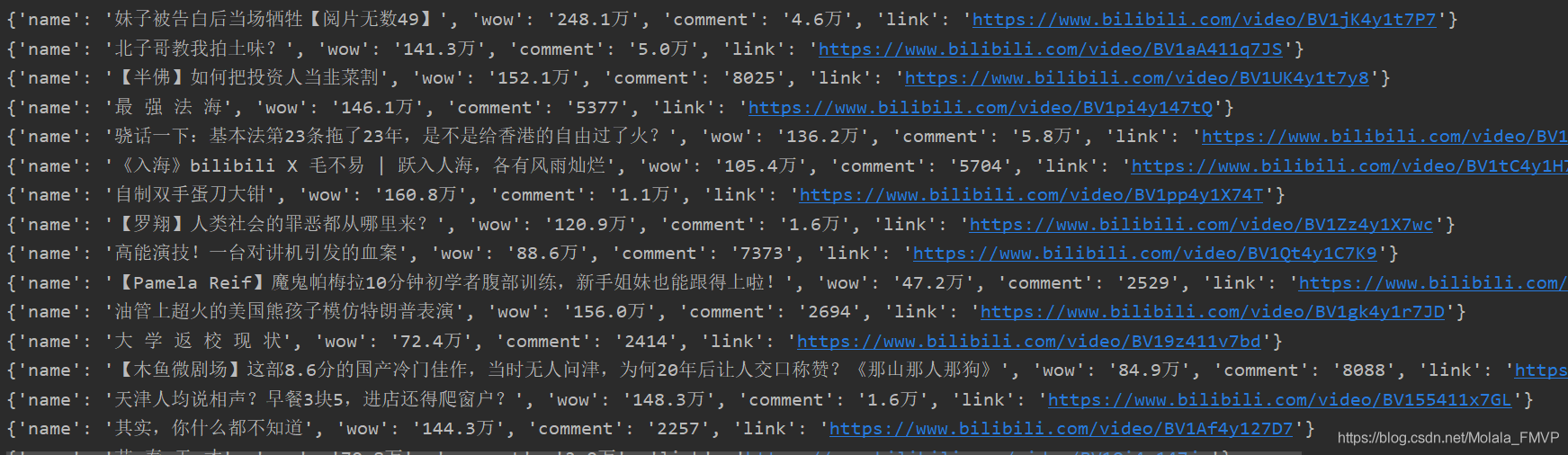
第一次写CSDN,也算是笔记吧哈哈哈哈哈
by Molala















 4314
4314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









