







 本文深入探讨了数据中心网络中的拥塞控制问题,重点介绍了基于优先级的流量控制(PFC)和显式拥塞通知(ECN)在实现无损网络中的角色。PFC通过为不同优先级的数据流提供独立的流控,防止丢包,但存在死锁、拥塞传播等问题。ECN通过端到端的拥塞通知,实现更高效的流控,但可能面临延迟和丢包问题。结合使用PFC和ECN,可以构建无损以太网,确保高优先级流量的无丢包传输,同时优化资源利用率。
本文深入探讨了数据中心网络中的拥塞控制问题,重点介绍了基于优先级的流量控制(PFC)和显式拥塞通知(ECN)在实现无损网络中的角色。PFC通过为不同优先级的数据流提供独立的流控,防止丢包,但存在死锁、拥塞传播等问题。ECN通过端到端的拥塞通知,实现更高效的流控,但可能面临延迟和丢包问题。结合使用PFC和ECN,可以构建无损以太网,确保高优先级流量的无丢包传输,同时优化资源利用率。
目录
@bandaoyu 持续更新,链接: https://blog.csdn.net/bandaoyu/article/details/115346857
原文:《我们为什么需要RDMA?为什么需要无损网络?》https://www.sohu.com/a/258041228_100289134
(Priority-based Flow Control,基于优先级的流量控制)
前言
RDMA技术:降低数据中心内部网络延迟,提高处理效率。
当前RDMA在以太网上的传输协议是RoCEv2,RoCEv2是基于无连接协议的UDP协议,相比面向连接的TCP协议,UDP协议更加快速、占用CPU资源更少,但其不像TCP协议那样有滑动窗口、确认应答等机制来实现可靠传输,一旦出现丢包,依靠上层应用检查到了再做重传,会大大降低RDMA的传输效率。
所以要想发挥出RDMA真正的性能,突破数据中心大规模分布式系统的网络性能瓶颈,势必要为RDMA搭建一套不丢包的无损网络环境,而实现不丢包的关键就是解决网络拥塞。
(为什么需要无损网络:长期以来,HPC(高性能计算)的RDMA都是在Infiniband集群中使用,数据包丢失在此类群集中很少见,因此RDMA Infiniband传输层(在NIC上实现)的重传机制很简陋,既:go-back-N重传,但是现在RDMA的使用更广泛,在其他网络中,丢包的概率大于Infiniband集群,一旦丢包,使用RDMA的go-back-N重传机制效率非常低,会大大降低RDMA的传输效率,所以要想发挥出RDMA真正的性能,势必要为RDMA搭建一套不丢包的无损网络环境,go-back-N重传,见2.1 Infiniband RDMA and RoCE:https://blog.csdn.net/bandaoyu/article/details/115620365)
一、为什么会产生拥塞
产生拥塞的原因有很多,下面列举了在数据中心场景里比较关键也是比较常见的三点原因:
1.收敛比(总输入带宽/总的输出带宽)
进行数据中心网络架构设计时,从成本和收益两方面来考虑,多数会采取非对称带宽设计,即上下行链路带宽不一致,交换机的收敛比简单说就是总的输入带宽除以总的输出带宽。
交换机A:下行带宽480G,上行带宽240G,整机收敛比为2:1
交换机B:下行带宽1200G,上行带宽800G,整机收敛比为1.5:1
也就是说,当下联的服务器上行发包总速率超过上行链路总带宽时,就会在上行口出现拥塞。
2.ECMP(ECMP构建多条等价负载链路,HASH选择到已拥塞链路发送加剧拥塞)
当前数据中心网络多采用Fabric架构,并采用ECMP来构建多条等价负载的链路,并HASH选择一条链路来转发,是简单的,但这个过程没有考虑到所选链路本身是否有拥塞,对于已经产生拥塞的链路来说,很可能加剧链路的拥塞。
3.TCP Incast(多对一)
TCP Incast是Many-to-One(多对一)的通信模式,在数据中心云化的大趋势下这种通信模式常常发生,尤其是那些以Scale-Out方式实现的分布式存储和计算应用,包括Hadoop、MapReduce、HDFS等。
例如,当一个Parent Server向一组节点(服务器集群或存储集群)发起一个请求时,集群中的节点都会同时收到该请求,并且几乎同时做出响应,很多节点同时向一台机器(Parent Server)发送TCP数据流,从而产生了一个“微突发流”,使得交换机上连接Parent Server的出端口缓存不足,造成拥塞。
如下图,parent向所有node发出数据请求,多个node几乎同时向parent发出数据回复,形成多打一造成拥堵。
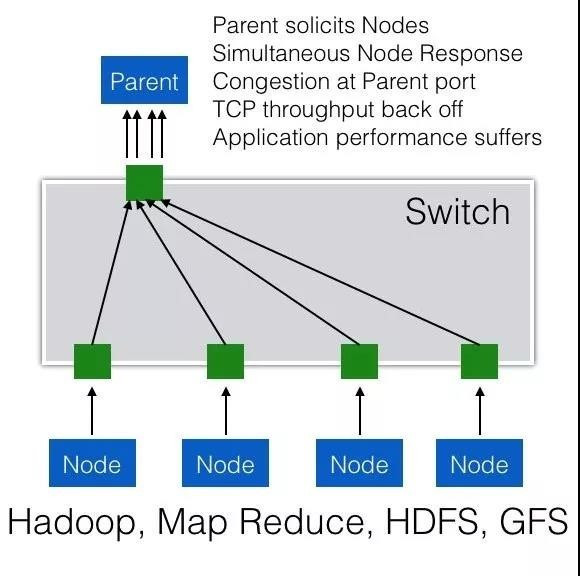
正如前面所说,RDMA和TCP不同,它需要一个无损网络。对于普通的微突发流量,交换机的Buffer缓冲区可以起到一定作用,在缓冲区将突发的报文进行列队等待,但由于增加交换机Buffer容量的成本非常高,所以它所能起到的作用是有限的,一旦缓冲区列队的报文过多,仍旧会产生丢包。
RDMA需要一个无损网络,交换机的Buffer缓冲应对网络拥堵防丢包作用有限,
为了实现端到端的无损转发,避免因为交换机中的Buffer缓冲区溢出而引发的数据包丢失,交换机必须引入其他机制,如流量控制,通过对链路上流量的控制,减少对交换机Buffer的压力,来规避丢包的产生。
二、PFC如何实现流控
(流控发展史:FC(整个链路流控)-->PFC(基于优先级流控)-->PFC+ECN(流控发生前避免拥塞)/PFC+ETS(分配带宽)+ECN)
IEEE 802.1Qbb(Priority-based Flow Control,基于优先级的流量控制)简称PFC,是流量控制的增强版。
FC(整个链路流控)
(下游发现拥堵,向上游发PAUSE帧)
说PFC之前,我们可以先看一下IEEE 802.3X(Flow Control)流控的机制:当接收者没有能力处理接收到的报文时,为了防止报文被丢弃,接收者需要通知报文的发送者暂时停止发送报文。
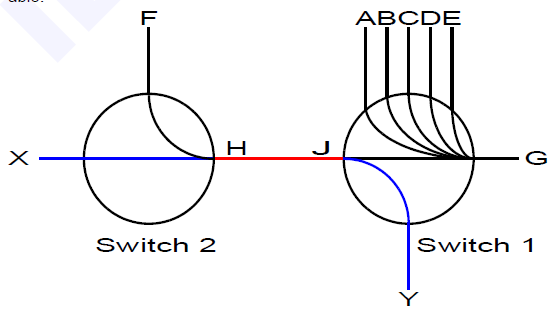
如下图所示,端口G0/1和G0/2以1Gbps速率转发报文时,端口F0/1将发生拥塞。为避免报文丢失,开启端口G0/1和G0/2的Flow Control功能。
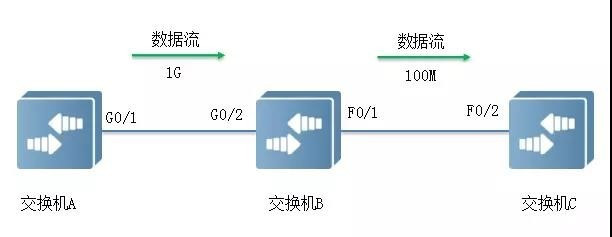
当F0/1在转发报文出现拥塞时,交换机B会在端口缓冲区中排队报文,当拥塞超过一定阈值时,端口G0/2向G0/1发PAUSE帧,通知G0/1暂时停止发送报文。
• G0/1接收到PAUSE帧后暂时停止向G0/2发送报文。暂停时间长短信息由PAUSE帧所携带。交换机A会在这个超时范围内等待,或者直到收到一个Timeout值为0的控制帧后再继续发送。
PFC(基于优先级流控)
(下游某一优先级发现拥堵,向上游某一优先级发PAUSE帧)
FC(IEEE 802.3X协议)缺点:一旦链路被暂停,发送方就不能再发送任何数据包,如果是因为某些优先级较低的数据流引发的暂停,结果却让该链路上其他更高优先级的数据流也一起被暂停了,其实是得不偿失的。
如下图中报文解析所示,PFC在基础流控IEEE 802.3X基础上进行扩展,允许在一条以太网链路上创建8个虚拟通道,并为每条虚拟通道指定相应优先级,允许单独暂停和重启其中任意一条虚拟通道,同时允许其它虚拟通道的流量无中断通过。

PFC将流控的粒度从物理(端口)细化到(8个虚拟通道),分别对应Smart NIC硬件上的8个硬件发送队列(这些队列命名为Traffic Class,分别为TC0,TC1,...,TC7),在RDMA不同的封装协议下,也有不同的映射方式。
• RoCEv1(RDMA封装协议):
这个协议是将RDMA数据段封装到以太网数据段内,再加上以太网的头部,因此属于二层数据包。为了对它进行分类,只能使用VLAN(IEEE 802.1q)头部中的PCP(Priority Code Point)域3 Bits来设置优先级值。
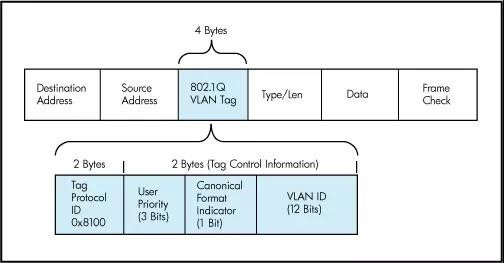
RoCEv2(RDMA封装协议):
这个协议是将RDMA数据段先封装到UDP数据段内,加上UDP头部,再加上IP头部,最后再加上以太网头部,属于三层数据包。对它进行分类,既可以使用以太网VLAN中的PCP域,也可以使用IP头部的DSCP域。
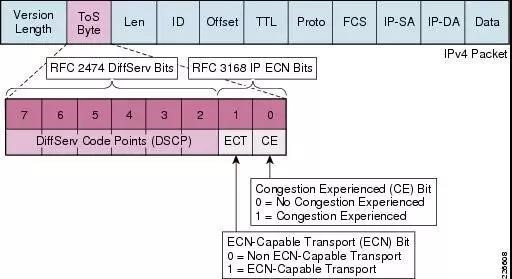
简单来说,在二层网络的情况下,PFC使用VLAN中的PCP位来对数据流进行区分,在三层网络的情况下,PFC既可以使用PCP、也可以使用DSCP,使得不同数据流可以享受到独立的流控制。当下数据中心因多采用三层网络,因此使用DSCP比PCP更具有优势。
RoCE 协议数据结构的详细说明:https://blog.csdn.net/bandaoyu/article/details/117560876
三、PFC存在的问题
- 死锁(PFCdeadlock)
虽然PFC能够通过给不同队列映射不同优先级来实现基于队列的流控,但同时也引入了新的问题,例如PFC死锁的问题。
PFC死锁,是指当多个交换机之间因微环路等原因同时出现拥塞,各自端口缓存消耗超过阈值,而又相互等待对方释放资源,从而导致所有交换机上的数据流都永久阻塞的一种网络状态。
正常情况下,当一台交换机的端口出现拥塞并触发XOFF水线时,即下游设备将发送PAUSE帧反压,上游设备接收到PAUSE帧后停止发送数据,如果上游设备本地端口缓存消耗超过阈值,则继续向上游反压。如此一级级反压,直到网络终端服务器在PAUSE帧中指定Pause Time内暂停发送数据,从而消除网络节点因拥塞造成的丢包。
但在特殊情况下,例如发生链路故障或设备故障时,BGP路由重新收敛期间可能会出现短暂环路,会导致出现一个循环的缓冲区依赖。如下图所示,当4台交换机都达到XOFF水线,都同时向对端发送PAUSE帧,这个时候该拓扑中所有交换机都处于停流状态,由于PFC的反压效应,整个网络或部分网络的吞吐量将变为零。
(BGP(Border Gateway Protocol,边界网关协议)是用来连接Internet上的独立系统的路由选择协议。)
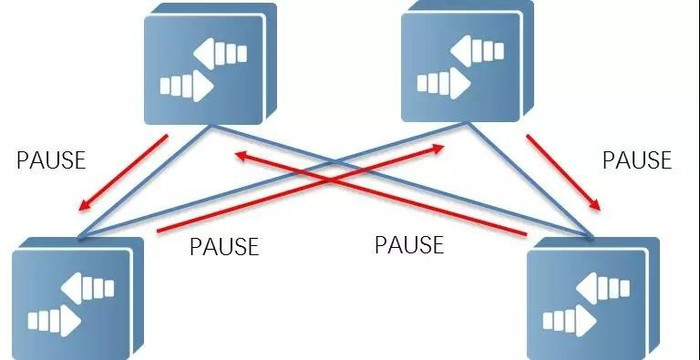
即使在无环网络中形成短暂环路时,也可能发生死锁。虽然经过修复短暂环路会很快消失,但它们造成的死锁不是暂时的,即便重启服务器中断流量,死锁也不能自动恢复。
为了解除死锁状态,一方面是要杜绝数据中心里的环路产生,另一方面则可以通过网络设备的死锁检测功能来实现。锐捷RG-S6510-48VS8CQ上的Deadlock检测功能,可以检测到出现Deadlock状态后的一段时间内,忽略收到的PFC帧,同时对buffer中的报文执行转发或丢弃的操作(默认是转发)。
例如,定时器的监控次数可配置设置检测10次,每次10ms内检测是否收到PFC Pause帧。若10次均收到则说明产生Deadlock,对buffer中的报文执行默认操作,之后将设置100ms作为Recover时间后恢复再检测。命令如下:
priority-flow-control deadlock cos-value 5 detect 10 recover 100 //10次检测,100ms recover。
RDMA无损网络中利用PFC流控机制,实现了交换机端口缓存溢出前暂停对端流量,阻止了丢包现象发生,但因为需要一级一级反压,效率较低,所以需要更高效的、端到端的流控能力。
- 拥塞传播
[RoCE]拥塞控制机制(ECN, DC-QCN) - https://www.cnblogs.com/burningTheStar/p/85
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3610
3610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









