






InnoDB中的索引:
B+树索引
全文(Full Text)索引 不支持中文
哈希索引
这里的哈希索引是自适应的(自动完成的),innodb会自动根据情况生成hash索引,不能人为干预。
B+树的B代表balance而不是binary,B+树不属于二叉树。B+树常应用于磁盘存储中。
B+树的演化
演化过程:
数组
—>
二叉查找树(BST)
—>
平衡二叉树(AVL)
—>
B-树
—>
B+树
顺序查找
二分
左右深度差<=1
m叉树,叶子在同一层
数据全保存在叶子,叶子之间有指针
注:b-树(平衡多路查找树)又称B树
B-树与AVL的区别:
变成了m叉树,使得关键字增多,从而树的深度减少
所有叶子节点在同一层,且都为NULL
m个关键字的节点至少有 ⌈ m/2⌉个子树。
关键字更多。层次更少,查找更快。
B+树与B-树的区别:
B+树的分枝节点不再保存关键字指针,只保存索引。
叶子节点保存了所有关键字信息。(数据,指针都保存在叶子节点)
叶子节点之间有双向指针相连。
同一节点中的数据按值从小到大排序。
n个关键字的父节点有n个字树。
层次更少。查询更稳定(每次都一样)。遍历更快(叶子之间有指针)
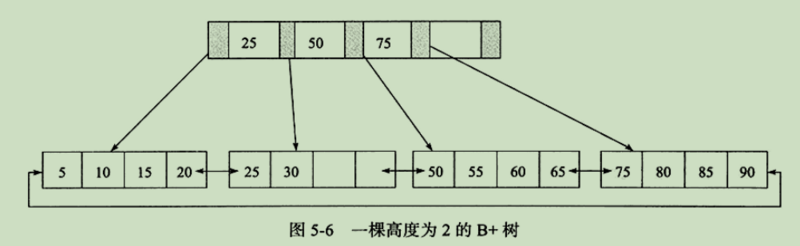
B+树的三个操作:插入
插入
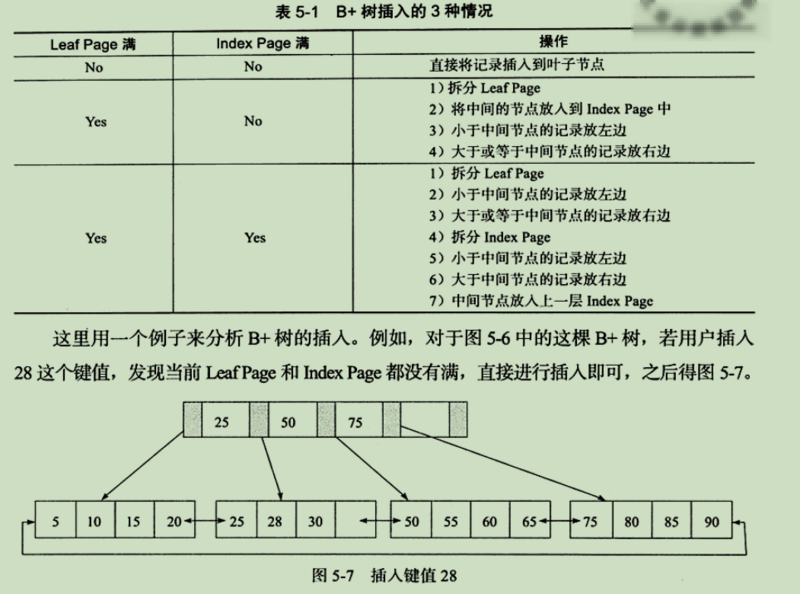
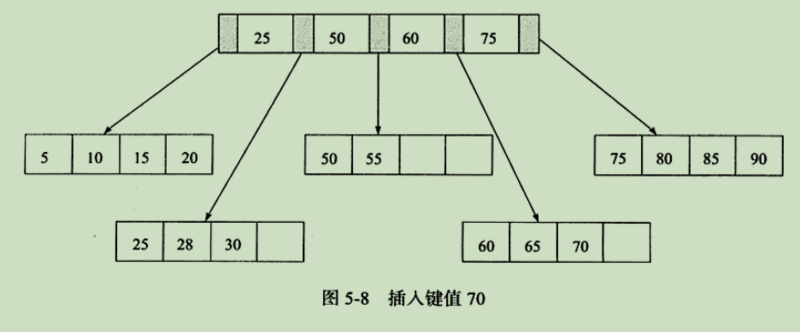
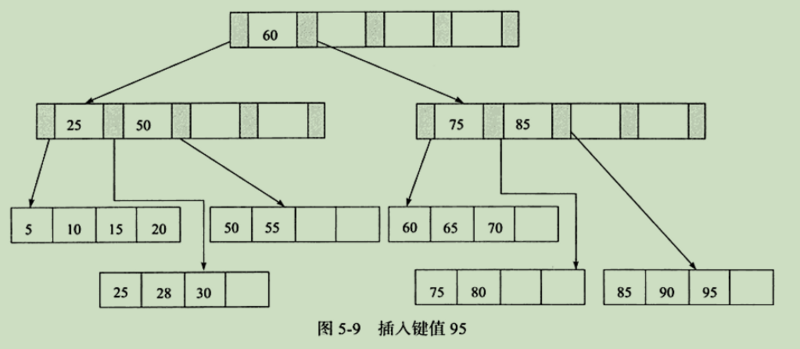
注:旋转,用于减少拆页次数。
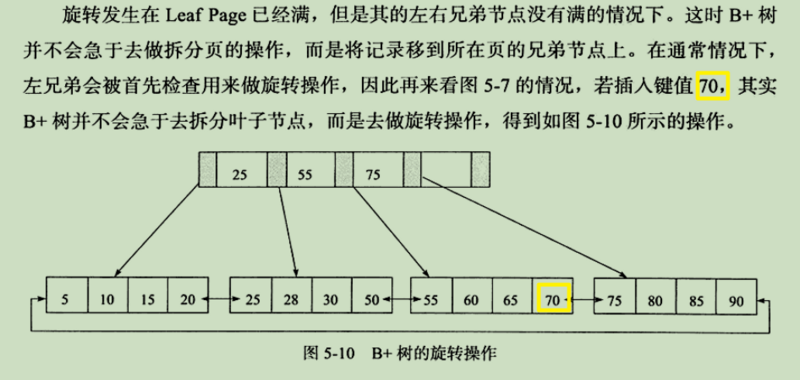
删除
根据删除后的填充因子来判断是否删除,50%是可以设置的最小值。
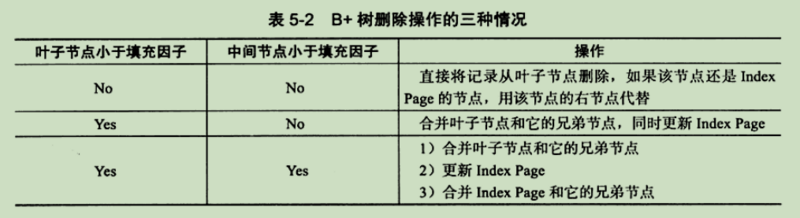
第一种情况:都没小于填充因子50%
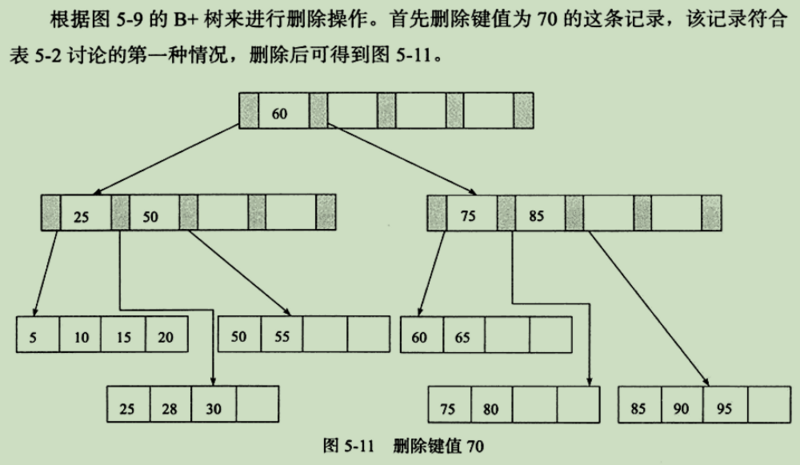
第四种情况:索引节点的填充因子 < 50% && 叶子节点不小于。
注:这种情况表中没有列出来,但是下图就是这种。该书的作者此处有笔误。
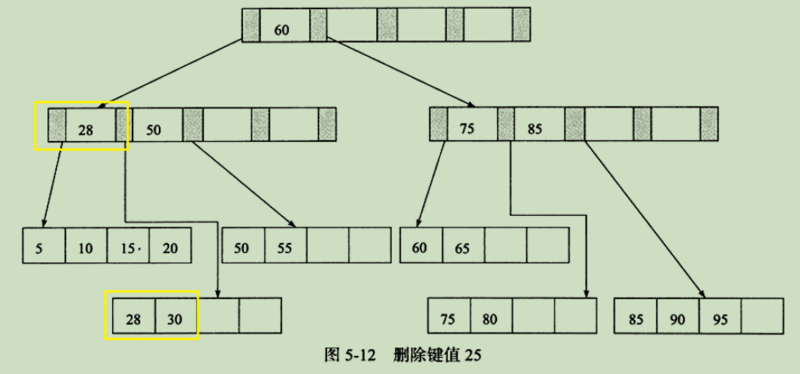
第三种情况
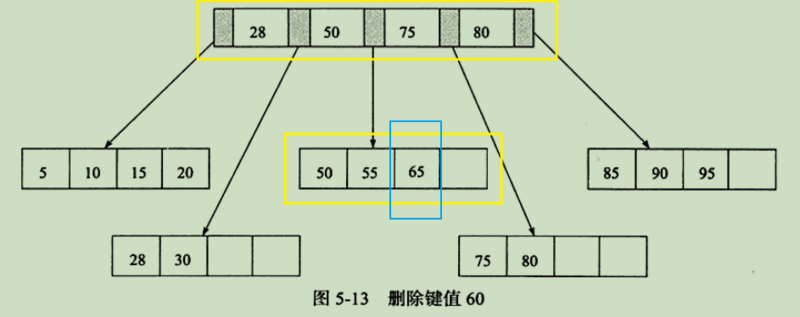
扇(shan)出:一个模块调用其他模块的格数。
扇入:被多少个模块调用。
B+树索引
聚集索引(clustered index)、辅助索引(secondery index)
聚集索引
为每张表的主键构造一颗B+树(叶子按顺序存放),叶子节点存放表的行记录数据,叶子节点 == 数据页。数据页之间双向指针连接。一张表只能有一个聚集索引。
范围查找非常快。(因为有顺序,而且有双向指针)
聚集索引的字段必须是NOT NULL && UNIQUE
辅助索引
叶子节点不包含所有行记录数据,每个叶子节点还包含一个书签(bookmark),书签指向的就是聚集索引。
创建索引的语法
创建
ALTER TABLE tbl_name
ADD [idx_type] | [idx_name] (clo1,col2...)
idx_type包含(unique,primary key,fulltext,index)
删除
ALTER TABLE tbl_name
DROP PRIMARY KEY
| DROP {INDEX|KEY} idx_name
创建部分索引(不是整个数据,而是开头的一定长度)
ALTER TABLE tbl_name
ADD KEYidx_b (b(100))
这里b字段为varchar(8000),但只建立前100个字符。
查看索引:SHOW INDEX FROM tbl_name;
更新基数Cardinality:ANALYZE TABLE tbl_name;
基数Cardinality
表示索引中 不重复记录数 的预估值。
实际应用中,Cardinality应尽可能接近1。如果值非常小,也表示没必要创建该索引。
什么时候创建索引
当列的值各种各样时,可以考虑创索引,如name字段。
对于值比较单一的列,无需创索引。如:sex字段值只有M/F。
B+树索引使用
联合索引、覆盖索引
联合索引
对于索引 idx_a_b(a,b),存储结构也是一个B+树,只是每个节点有多个值(这里为2):
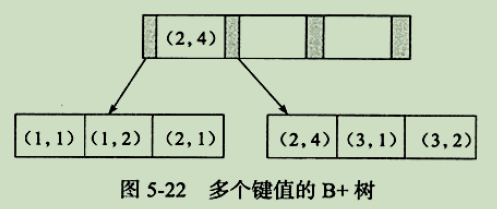
对于where a=xxx and b=xxx; idx_a_b有效。
对于where a=xxx; idx_a_b有效。
但对于where b=xxx; idx_a_b就失效了。
因为(1,2)(1,2)(2,1)(2,4)(3,1)(3,2)对于第一个字段a是有序的;对于a相同时,b也是有序;但值看b,则没有顺序了。这就是前缀匹配。
联合索引的优点:会对后面的字段排序。
适用场景:查找同一用户,按时间排序的购物记录。
添加索引: ALTER TABLE tbl_name ADD INDEX idx_uid_buydate(uid,buydate);
覆盖索引
指从辅助索引中查到记录,而不需去聚集索引中查,效率更高。
因为辅助索引只直接保存了一部分数据,所以结构会比较小,能更快查出来。
使用场景:统计函数COUNT(*)会先走覆盖索引。
强制使用索引force index(idx_name):select * from table_name force index (index_name) where conditions;
索引提示use index(idx_name): 告诉优化器,可以考虑一下这个索引来查,决定权在优化器本身。
优化器不使用索引:
典型场景:查整行select * 时,辅助索引扫描(index scan)不会使用,因为查整行还要通过书签去聚集索引查,所以优化器就直接使用了聚集索引进行全表扫描(table scan)。
MRR优化(Multi-Range Read)
适用于:range,ref,eq_ref。有索引进行 范围 查找时会进一步优化。
命令:SET @@optimizer_switch = 'mrr=on,mrr_cost_based=off'; 总是开启mrr,不考虑代价。
使用提示extra: using mrr;
ICP优化(Index Condition Pushdown)
适用于:range,ref,eq_ref,ref_or_null。对where条件进一步优化。
如对于索引(a,b,c),where a="123" and b LIKE "%xx%" and c LIKE "%yy%";
原本索引b会失效(LIKE加%开头),但ICP优化器会进一步优化,进一步过滤。
使用提示:using index condition;
全文检索(Full-Text-Search)
定义:用于检索整本书或整篇文章中任意内容的技术。
全文索引使用 倒排索引(inverted index)来实现,inverted index保存着{单词,文档id,文档中的位置}
InnoDB全文检索
采用full inverted index实现,存储着{word,(DocumentId,Position)},word又单独存在一个辅助表中。
每张表只能有一个全文检索的索引。
全文索引中各列的字符集和编码要相同。
不支持没有界定符号(如空格)的语言:中文,韩语等。
使用命令WHERE MATCH(col) AGAINST('key'):SELELCT * FROM tbl WHERE MATCH(col) AGAINST('key');















 6385
6385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









