






USE sql_store; //表示使用哪一个数据库
SELECT * //获取所有列
或者SELECT customer_id,first_name 获取固定列
select 1,2
select distinct state. —挑选截然不同的数据结果,去重
select (unit_price+10)*100 AS 'new_price'
FROM customers //明确 想要查询的表
-- WHERE customer_id=1 //筛选作用,直接定位查询id为1的顾客
//--为SQL的注释符号
where的数值判定
WHERE points>3000 可以是数值比较,或者是文本比较,或者日期比较
WHERE state<>'VA ‘ // != 和<>作用一样
WHERE birthdate>'1990-01-01'
where的逻辑判定 (NOT优先级高于AND优先于OR,有优先级可以用括号表明优先级)
WHERE birth_date>'1990-01-01' AND points>1000
WHERE NOT (birth_data>'1990-01-01'ORpoints>1000)
OR运算符链接的是表达式或者条件,不能连接字符串
如WHERE state='VA' OR state =‘GA ' OR state =‘FL’✅
WHERE stste ='VA'OR 'GA'OR 'FL’ ❌
IN运算符
WHERE state='VA' OR state =‘GA ' OR state =‘FL'
可以用IN运算符
WHERE stste IN(‘VA’,’FL’,'GA ')无所谓顺序
WHERE state NOT IN(‘VA’,’FL’,'GA ')
BETWEEN
WHERE points BETWEEN 1000 AND 3000
WHERE birth_date BETWEEN '1990-01-01' AND '2000-01-01'
LIKE运算符 模糊查找
WHERE last_name like 'B%’ //查询b开头的,
%的应用 表示可以代替任意字符也可以用’%b%’查询名字位置在中间里含有b的
WHERE last_name like '_y' 表示名字两个字符,一个下划线表示一个单字符
REGEXP 正则表达式
WHERE last_name regexp 'field' // '^field’ 意味着必须以field开头。
‘field$’意味必须以filed结尾
WHERE last_name regexp 'field|mac|rose' //表示多个搜寻模式
WHERE last_name regexp '[gim]e’//包含ge ie me,;'[a-h]e’包括h;也可以e[fmq]放在后边;
Is null. 查询空缺数据 不能用= 因为null不是一个数值或者文本,是一种空集的状态
is not null。不空 用于逻辑判定。
order by //排序作用 ,给数据排序
order by state, first_name //排序作用 ,给数据按照某一列先排序,在第二顺位排序
order by first_name DESC. //倒序
就是select 没有选择排序的列,排序仍可以进行
limit 子句 // 永远在最后
limit 3 // 限制前三条数据
limit 6,3//带偏移量,从第六个开始数3个
delete from invoice_with_balance //删除满足where 条件的数据
where invoice_id =1
三个子句有先后顺序,先选择(目标),然后从哪里,在哪里,最后按顺序
第三章
Join on 内连接 完全匹配查询
SELECT order_id,o.customer_id,first_name,last_name
FROM orders o //可以简化数据表,直接在完整表名字后边写别名,赋简称以后必须全部都用简称,不然报错
join customers c // 需要匹配的表
on o.customer_id=c.customer_id // on后边跟条件,表示o表的哪一列可以跟c表的哪一列匹配,
等号左边是主表的条件,等号右边是副表的内容
—也可以用 using子句代替on+条件
using(customer_id). //如果两个表格匹配的关键字一样,可以使用using语句
跨数据库连接
from order_items o
join sql_inventory.products p //需要匹配的数据库的具体的表
on o.product_id=p.product_id. // 条件:不同表的产品id一致
自连接 P20
SELECT e.employee_id ,e.first_name, m.first_name as manger
//职员表的id和名字,管理员表的名字,作为manger
FROM employees e //从employee的表
join employees m // 需要匹配自己的表,命名为m,相当于备份
on e.reports_to=m.employee_id //条件是本表的reports_to 和employee_id 一致
复合连接 P22
from order_items oi //需要复合的主表
join order_item_notes oin //需要复合的副表
on oi.order_id=oin.order_Id //两个主键都对应
AND oi.product_id=oin.product_id
—也可以用using子句
using(order_id,product_id)
隐式连接 P23
SELECT *
FROM orders o,customers c //一定注意子句后边没有标点符号
WHERE o.customer_id=c.customer_id //隐式连接一定要写where子句判定条件
外连接 outer joins 可能数据不匹配,基于某一个表格来展示
SELECT *
FROM customers c
left join orders o. //. left 就是保留join左边的表,right就是保留join右边的表,无论条件是否成立
on c.customer_id=o.customer_id
自然连接
select o.order_id,c.first_name
FROM orders o
NATURAL JOIN customers c. // 电脑基于共同的列来进行随机匹配。
交叉连接 //
显式语法
select c.first_name AS customerp.name AS product
from customers c
cross join products p
隐式语法
select c.first_name AS customerp.name AS product
from customers c,produc p
union子句//在同一张表中查询不同的结果并合并。
也可以基于不同的表格进行查询,把结果合并到一个结果集。
union all 可以不去重
基于同一张的不同结果
SELECT order_id,order_date,'不活跃'AS status
FROM orders
WHERE order_date<'2019-01-01'
union //联合
SELECT order_id,order_date,'活跃'AS status
FROM orders
WHERE order_date>='2019-01-01'
基于不同的表格
select first_name //结果显示的列是第一个行
from customers
union
select name
from shippers //第一个表格合并的行和第二个表格合并的行数量要一致。
第四章
列的数据类型
Int 整数型 如1,2,3
varchar(50)为可变字符,最多可以有50个字符。char(50)固定字符数量如果不够,则用空格补齐。
PK 为主键的缩写
NN 非空值//选中非空值,则该列不可以空值,即表示必选。
AI,自动递增//多用于主键,增加一条记录则主键数量增一。
default/expression//默认值,若此格的值为空白,则输入null。若是数值则输入'0'。
单表插入单行
Insert into customers(last_name,first_name,birth_date,address,city,state) // 设置插入指令以及插入的表。
values ('john','smith','1990-01-01','address','city','CA’) // 赋值:如果插入指令设置的是表, 那么需要填写所有字段 ,如果插入指令设置的是个别字段,则需要针对字段进行填写。
单表插入多行
Insert into shippers (name) //单列
values('shipper1'),('shipper2'),('shipper3')
Insert into products (name,quantity_in_stock,unit_price) // 多列
values('product1',10,1.95),('produc 2',12,2.98),('product3',22,3.98)
多表插入数据
现在已知的表中查询现有的顾客。并在此顾客下建立一个新的订单。
Insert into orders(customer_id,order_date, status)
values(1,'2019-01-02',1);//添加新的订单
insert into order_items
values(last_insert_id(),1,1,2.32), //调用函数获取最新的订单ID,并应用于订单类目。
(last_insert_id(),2,1,1.32)
创建表格副本
首先创建新表。
create table orders_archive AS 创建新表。
select *from orders //子查询,查询母表
只复制部分数据进入新表。
insert into orders_archive
select * //以下作为添加代码的子查询 //代替赋值,因为已经查询出目标数据。
from orders
where order_date<'2019-01-01'
更新表格中单条数据
update invoices
set payment_total=invoice_total*0.5, // 可设为具体值,也可以是表达式
payment_date=due_date
where invoice_id=1
更新表格中多条数据 !!! 这里先写查询的代码,查询结果是目标以后再写更新代码
update invoices
set payment_total=invoice_total*0.5,
payment_date=due_date
where client_id=3 //如果想要更新所有数据可以不写这个子句
--where client_id IN (3,4)//也可以选中固定的几个目标
--where client_id= //可以根据姓名来自动匹配ID。
(select client_id
from clients
where name='Myworks')
--where client_id in
(select client_id
from clients
where state in ('CA','NY')) // 可以选中具体的国家查询来匹配ID进行更改。
--where paymen_date is null //可以选择数据为空的进行更改。
删除单行。
delete from invoices //如果只有此行代码,会删除表里的所有数据。
where invoice_id=1 //删除发票ID为1的数据。
where client_id= //运用子查询删除某个人的数据。
(select client_id
from clients
where name ='muyworks')
恢复数据库
file----open sql scrip--打开create-databases.sql---运行——刷新数据库
第五章
函数
select max(invoice_total) as highest, //最大值
min(invoice_total) as lowst, //最小值
avg(invoice_total) as average, //平均值
sum(invoice_total) as total, //求和
— sum(invoice_total *1.1) AS total, //可以是表达式计算以后再取最大值。
count(invoice_total) as number_of_invoices, // 计数功能 不可以设置空值
count(payment_date) as count_of_payments, //计数功能,可以设置空值
count(*) as total_records //计算所有数据,包括空值的,不建议用
select count( distinct client_id) AS total_records //以顾客id作为计数的标准
from invoices
where invoice_date between '2019-01-01'AND '2019-06-03 '//可以加上筛选条件,对日期进行区分。
group by //分组功能,此子句必须在select和from,where 之后,必须在order by之前
select client_id ,
sum(invoice_total) as total_sales
from invoices
where invoice_date>='2017-07-01'
group by client_id // 以顾客ID进行分组计算销售总额。
order by total_sales desc
select state,city,sum(invoice_total)as total_sales //连接其他的数据表。进行分组统计。
from invoices i
join clients using (client_id)
group by client_id. //如果有更名,用更名以前的字段来分组,必须使用列的实际名字
select client_id,sum(invoice_total)AS total_sales,
count(*) as number_of_invoices
from invoices
group by client_id
having total_sales>500 and number_of_invoices>5
select client_id,sum(invoice_total)AS total_sales,
count(*) as number_of_invoices
from invoices
group by client_id
having total_sales>500 and number_of_invoices>5 //having筛选的条件一定是上面出现过的字段。
with rollup //只能应用于聚合值的列,汇总整个结果集
select state,city,sum(invoice_total) as total_sales
from invoices
join clients c using (client_id)
group by state,city with rollup //用于group by 之后
第六章
子查询
可以用于select里,或者from,或者where子句
_______________
select *
from clients
where client_id not in(. //not in 不在此列表的
select distinct client_id
from invoices)
此段程序也可以用外连接来实现。
select *
from clients
left join invoices using(client_id)
where invoice_id is null
____________
All关键字
___________
select*
from invoices
where invoice_total>
(select max(invoice_total)
from invoices
where client_id=3)
也可以用
select*
from invoices
where invoice_total>ALL //--where invoice_total>ALL (150,130,167)
(select invoice_total
from invoices
where client_id=3
Any关键字 // = any 与IN 作用相同,都是针对在一个集合里选择任意一个
where invoice_total>some(
select invoice_total
from invoices
where client_id=3
)
相关子查询
-- 挑选在他们部门工资超过部门平均值的员工房
select *
from employees e
where salary >(
select avg(salary)
from employees
where office_id = e.office_id //如果要分组筛选计算,可以用子查询,复制表和本表的字段相同
)
exists 运算符
//exists并没有把结果返回给前面的字句,而是判断真假,若为真才返回查询结果。
-- find the products that have never been ordered
select *
from products p
where not exists ( //如果用in则需要标明具体列 ,where product_id not in()
select product_id
from order_items
where product_id=p.product_id ) 需要子查询内等于外查询
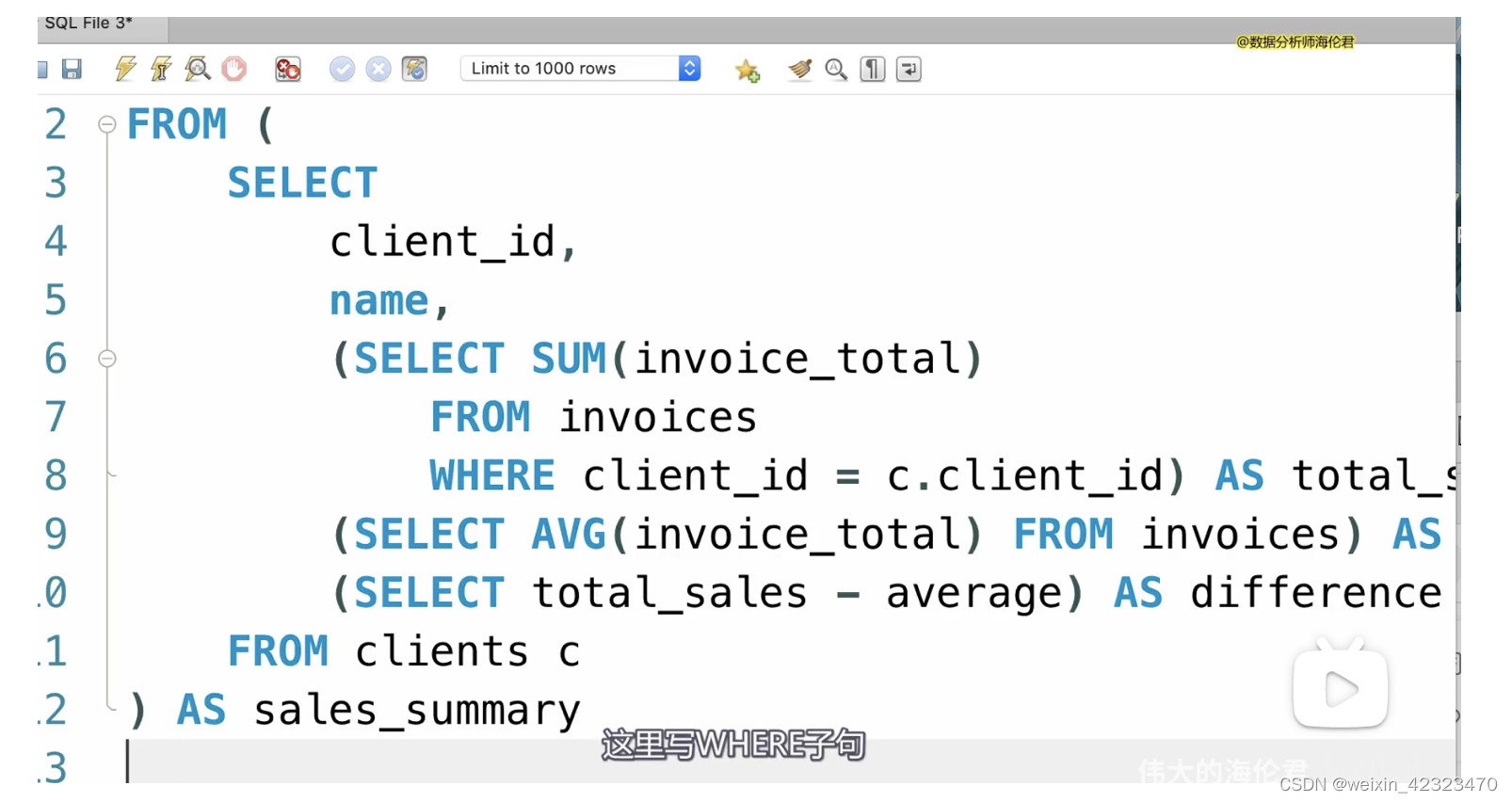
select语句进行子查询
select
invoice_id,
invoice_total,
(select avg(invoice_total)
from invoices) as invoice_average,
invoice_total-(select invoice_average)
//表达式中不能使用别名,但是可以用(select 别名)来引用
from invoices
from 后边嵌套已查询的一张虚拟的表,查询出来的表可以正常使用
第七章
数值函数 //专门处理数值数据的
MySQL :: MySQL 5.7 Reference Manual :: 12.6 Numeric Functions and Operators 数据函数所有关键字
round
select round(5.73) //四舍五入
结果:6
select round(5.7345,2)
结果:5.73 //可以选择保留的小数点位数
select gender,university,
count(*)as user_num,
Round(avg(active_days_within_30),1)as avg_active_day, //round也可以用函数,并且可以起别名
Round(avg(question_cnt),1) as avg_question_cnt
from user_profile
group by gender,university
truncate //截断数字
select truncate(5.7345,2) 结果5.73
select ceiling(5.7345) 结果 6 //可以得到大于或者等于这个数字的最小整数 向上取整
select floor(5.7345) 结果5 //向下取整,小于或者等于这个数字的最大整数
select ABS(-5.7) 结果5.7 //取绝对值
select rand() //生成0-1之间的随机浮点数
字符串函数
MySQL :: MySQL 8.0 Reference Manual :: 12.8 String Functions and Operators
完整字符串函数
select length('hello!world') 结果:11 //计算计算字符串长度
select upper('hello!world') //输出为大写
select lower('hello!world’) //输出为小写
select ltrim(' hello!world') //删除字符串左边的空格
select rtrim ('hello!world ') //删除字符串右边的空格
select trim(' hello world') //删除前后的空格,中间的不删除
select left('hello!world ',4) //显示左边4个字符
select right('hello!world ',4) //显示右边4个字符
select substring('hello!world ',4,3) 结果:'lo!’ //第一个是字符串,第二个是起始位置(从1开始),第三个数据是截取字符长度,如果不写,则会从起始位置到字符串最后
select locate('!','hello!world ') 结果 6 //定位到第一个参数在字符串中的位置.如果第一个参数不在字符串中,则显示结果为0
select locate('!','hello!world ‘) 结果为7 //若第一个参数为字符串,结果为第一次出现的位置
select replace('hello!world','world','mysql') 结果为 hello!mysql
//作用:用第三个目标字符代替第二个字符串
select concat('hello!','world') //拼接两个字符串,也可以是n个字符串
应用:select concat(first_name,' ',last_name) as name //可以连接数据表中两列数据
日期和时间函数
select now() ,curdate(),curtime()//获取当前时日期+时间,获取当前日期,获取当前时间
select now(),year(now()) ,month(now()),day(now()), hour(now()), minute(now()),second(now())
//获取当面年月日,时分秒
select dayname(now()),monthname(now()) //得到星期或者月份的英文
select extract(year from now()) //从当前时间提取出年,也可以改为其他的单位
格式化日期和时间
https://www.w3school.com.cn/sql/func_date_format.asp
select DATE_FORMAT(now(),'%M%d%') 格式化日期
select TIME_FORMAT(now(),'%H:%i %p') 格式化时间
计算日期和时间
select date_add(now(),interval 1 day) 间隔一天,返回明天同一时间// day可以换成任何单位,也可以传递负值,查询过去的时间
select date_sub(now(),interval 1 year) 可以直接查询过去的时间
select datediff('2022-02-07','2022-02-01’) //计算两个日期之间的间隔,!!注 此查询只可以返回日期
select time_to_sec('09:00') //返回从零点计算的秒数
select time_to_sec('09:00')-time_to_sec('09:02') //计算两时间相隔的秒数
ifnull函数
select order_id,ifnull(shipper_id,'not assigned') as shipper
from orders // ifnull( ) 括号里带两个参数,一个是选取的列,
第二个是如果第一个参数为空,则输出什么
coalesce //使联合
select order_id,
coalesce(shipper_id,comments,'not assigned') as shipper
// 该函数三个参数,第一个是要选取的列,第二个是 第一列如果为空,则选取备注,第三个参数是前两个都为空,则输入最后一个
from orders
if 函数
if(条件,true的结果,F的结果)
SELECT order_id,order_date,
if(year(order_date)=year(now()),'Active','Archived') as category
FROM orders
case 运算符
select order_id,
case
when year(order_date)=year(now()) then'active'
when year(order_date)=year(now())-1 then'last year'
when year(order_date)<year(now())-1 then'archived'
else 'future'
end as category
FROM orders
第八章
创建视图
create view sales_by_client AS // 创建视图
select c.client_id,c.name,sum(invoice_total) as total_sales
from clients c
join invoices i using (client_id)
group by client_id,name
drop view sales_by_clnt // 删除视图
create or replace view sales_by_client as.// 可以点击运行旁边的文件夹进行保存,在views右边的。小工具里点击进行修改代码。
__________
update invoice_with_balance //可以更新视图的数据。更新以后改变原表的数据。
set payment_total =invoice_total
where invoice_id = 2
with check option //更新数据以后与原表的筛选条件不符,刷新以后删除该行。
若不希望删除本行。只要可以加入最后一个语句,r。
可更新数据
view没有以下任何一个,数据可以更新,可以在insert,update ,delete语句中使用这类视图
--distinct --aggregate functions(min,max,sum,…)
--group by /having --union
第九章 存储
创建存储
DELIMITER $$ // 用$$表示分隔
create procedure get_clients() //创建存储程序
begin
select *from clients; //创建存储的查询 !!最后一句不要忘记加分号
END $$
DELIMITER ; // 分隔后用分号结束
也可以直接在Stored Procedures 左边菜单栏右击create
调用存储过程
call get_clients( )
删除存储
DROP PROCEDURE get_clients
更保险 一点
DROP PROCEDURE if exists get_clients
创建存储过程的基本构架,需要保存到文件
DROP PROCEDURE if exists get_clients;
DELIMITER $$
create procedure get_clients()
begin
select * from clients;
end $$
DELIMITER ;
建立携带参数的存储过程,返回符合参数的数据
DROP PROCEDURE if exists get_clients_by_state;
DELIMITER $$
create procedure get_clients_by_state
(
state char(2) -- VARCHAR
)
begin
if state is null then
set atate ='CA';
end if;
select * from clients c
where c.state =state; //存储的列与表格的列一致则返回
end $$
DELIMITER ;
带默认值的参数
DROP PROCEDURE IF EXISTS get_clients_by_state;
DELIMITER $$
CREATE PROCEDURE `get_clients_by_state`
(
state CHAR(2)
)
BEGIN
if state is null then // 如果值为null,则设置国家为CA
set state ='CA';
end if; //结束if条件语句
select * from clients c
where c.state = state;
END $$
DELIMITER ;
DROP PROCEDURE IF EXISTS get_clients_by_state;
DELIMITER $$
CREATE PROCEDURE `get_clients_by_state`
(
state CHAR(2)
)
BEGIN
if state is null then // 如果值为null,则返回所有数据
select * from clients c;
else
select * from clients c //否则返回固定值
where c.state=state
end if; //结束if条件语句
END $$
DELIMITER ;
上边用if条件else比较麻烦
begin
select * from clients c
where c.state =ifnull(state,c.state);
end $$
建立可更新数据的存储
CREATE DEFINER=`root`@`localhost` PROCEDURE `make_payment`(
invoice_id int,
payment_amount decimal(9,2),
payment_date DATE
)
BEGIN
if payment_amount< = 0 then
signal sqlstate ‘22003’
set massage_text = ‘invalid payment amount' ;
end if;
update invoices i // 在更新是可能输入负值或者其他不合理的数据 ,
可以用上述if语句提示设定错误代码
set i.payment_total =payment_amount,
i.payment_date =payment_date
where i.invoice_id =invoice_id;
END















 2733
2733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









