






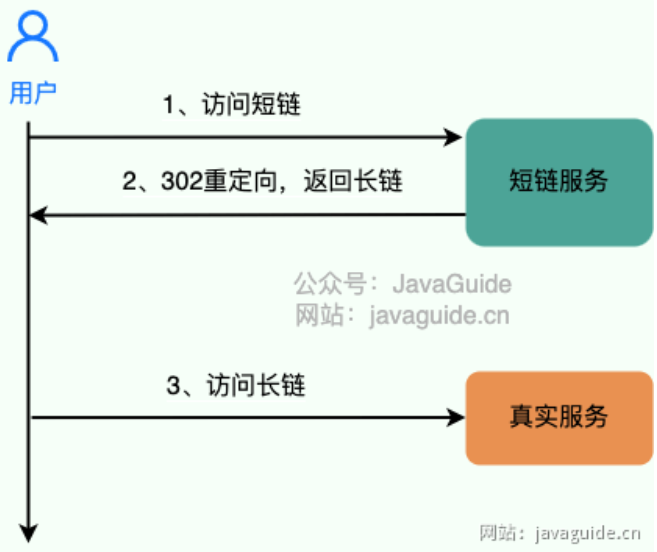
什么是短链?为什么需要短链?
- 短的链接,并不是真正的请求地址。(最终通过访问短链的服务,重定向到您真正要访问的地址)
- 有些链接的请求参数会非常多(非常长),导致不雅观且有些地方输入内容是有长度限制的(微博、手机短信)。因此,通过短链可以解决这些问题。
方案一
- 服务端接收到长链。
- 判断长链是否存在。
- 若存在,直接返回短链。
- 若不存在,执行步骤3。
- 进行哈希运算,转成62进制。
- 判断该短链是否存在。(Redis或MySQL)
- 若不存在,存入短链和长链的映射关系、长链和短链的映射关系(目的:判断长链是否存在)。
- 若存在,对哈希运算加盐,重新生成短链。或者在当前短链的尾部加个随机的字符串,再进行重新判断。

方案优点
- 实现相对来说简单,对于大多数的场景下来说都足够了。
方案缺点
- 需要频繁的请求缓存、数据库。(2 次查 redis、2 次写 redis、2 次查 hbase、2 次写 hbase)
优化方案
既然想要优化,那么就要先分析出哪些地方可以优化、哪些地方耗时最长 值得优化!
通过流程图可以看出,我们写入数据是必须的。(无法再进行优化的)
**可以发现更多的IO操作,是发生在判断上面。**那么现在问题可以转化成:有没有一种算法可以避免碰撞所带来的检查开销。
可是如果不判断,就会发生哈希冲突,导致有重复的短链啊。那么有什么办法可以避免吗?
- 有的。如果使用自增的id,那么就不会发生哈希冲突了。那么就无需再进行判断操作了。

那么分布式自增算法是怎么实现的呢?
目前市面上已知方案:
- 通过数据库自增(并发 QPS 数有限)
- 通过 redis 自增(存在单 key 热点问题,也就是所有的发号请求都会打到同一分片上),两种方案均会增加性能损耗,且存在扩展瓶颈,无法满足京东的海量业务请求。
- 雪花算法(长度太长不符合,短网址要求长度一般在 7 个字符)
分布式号段发放算法
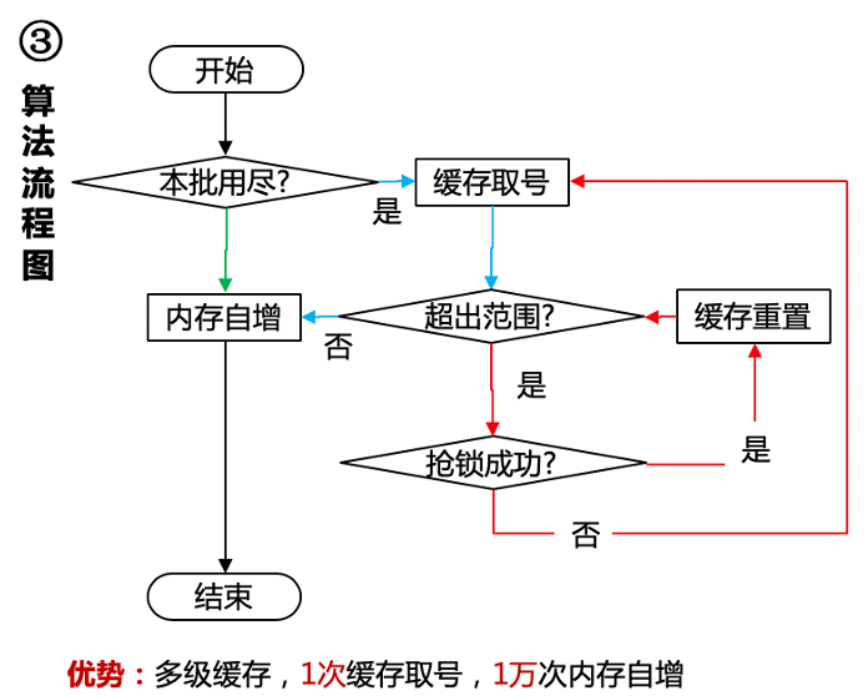
- 主要采用缓存发号加内存自增方式,既无碰撞率又性能极高,主要体现在下图的三条彩色通道上面。(即:一次性申请多个id,放在JVM的缓存中。用完再从Redis中获取一批id)
- 绿色通道:内存发号,速度极快,每次从缓存取出 10000 个无重复号码,然后在内存中便可连续生成 10000 个短码,因此速度比传统基于数据库及缓存自增发号方式快万倍。
- 蓝色通道:缓存取号,依赖缓存保证分布式发号无碰撞,批量发号,每 1 万次内存绿色通道才走一次蓝色缓存通道取号,因此性能极高
- 红色通道:保障机制,保障生成的号码都在短网址对应长度的号码总容量范围内,仅在初始化及总容量用尽时执行,性能损耗可忽略不计。















 3898
3898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









