









-
查看ceph 读写i/o最好不要通过iostat查看 因为有可能会将内容写到缓存中,从而无法获得对于的真正读写i/o
可以通过ceph dashboard来查看,也可以通过ceph -s来查看
动态获取脚本:
#!/bin/bash LANG=C PATH=/sbin:/usr/sbin:/bin:/usr/bin interval=1 length=86400 for i in $(seq 1 $(expr ${length} / ${interval}));do date=`date` echo -n "$date " ceph pg stat sleep ${interval} done -
查看用户已经使用的空间
radosgw-admin user stats --uid=<uid> --sync-stats
-
如果发现mgr相关命令不可以使用例如:
ceph config set mgr mgr/dashboard/server_port 8080等等
出现 mgr/dashboard/server_port位置找不到等问题时检查当前所在的mgr是否存活
检查是否存活:
systemctl status ceph-mgr@{node名称}如果发现实在复活不了mgr则删除掉它
sudo systemctl stop ceph-mgr@{mgr-name} sudo systemctl disable ceph-mgr@{mgr-name} sudo rm -rf /var/lib/ceph/mgr/ceph-{mgr-name} -
可以创建subuser,其名称可以带中文,但是带中文的话到时候会dashboard会显示错误
-
rgw创建bucket的时候必须给定最大值,否则后期当某一个bucket中object中的数量非常多会出现问题
-
没有什么不是重启不能解决的
如果日志排查不出有什么问题,直接重启看看行不行
-
对象存储使用s3上传 1个26M大小的文件 上传的时候显示增加了8个objects 而删除的时候只少了1个 这是什么原因?
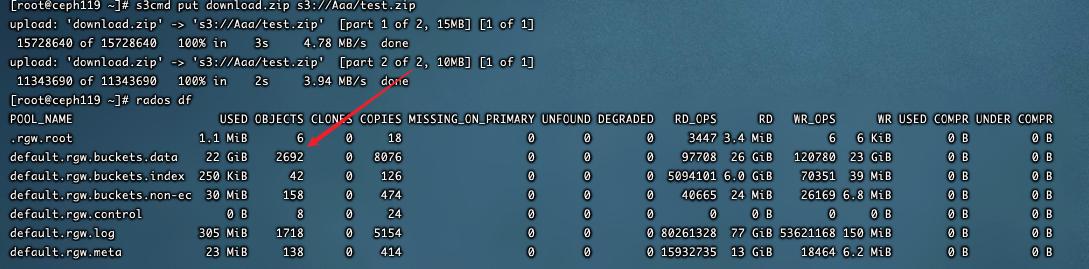
可以看到上传之后此处object的个数为2692个
删除之后

可以看到删除之后此处的object个数为2691个
剩下的由gc清理
关于rgw分段上传问题
-
分段上传会将每一段都作为一个object,比如一个文件45M,按照默认的分段上传的大小为15M,那么将会分段上传3次,每一个都会作为一个object上传
如果上传的bucket的max_object=2,那么上传将会失败,因为需要max_object=3
下面的例子是docker.log=55M,Quota的max_object=3,因此在上传第四块的时候出错
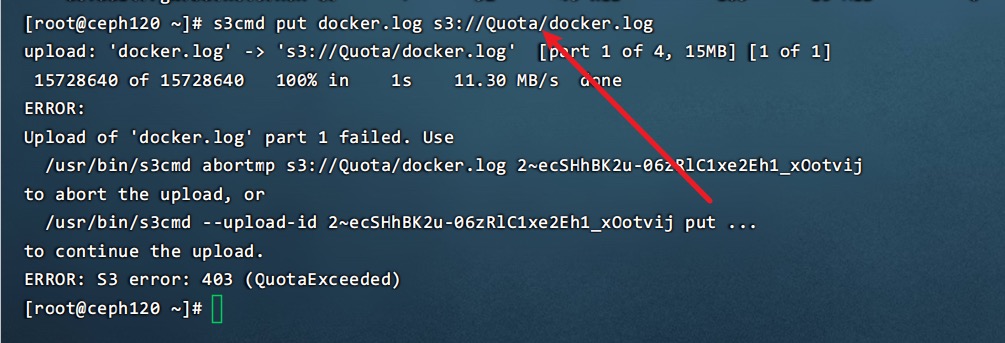
可以查询看到
-
为何达不到bucket的max_object,继续上传会报配额不足的情况?
分段上传失败此处太多,导致usage中的rgw.multimeta中的num_objects残留数量太多,因为max_object<(红色箭头之和)
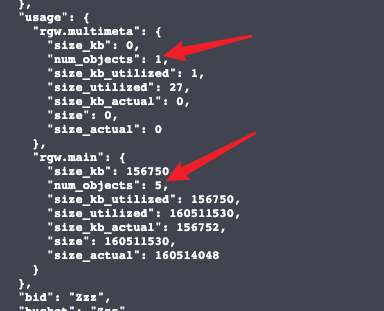
注:
- 下面的第二个红色箭头的数字代表的含义:bucket中上传完毕的对象总个数(包括合并的与为合并的)
- 当分段上传完成之后会将分片合并为一个object
- 当分段上传的一块上传完毕之后也会产生一个object
- 下面的第一个红色箭头的数字代表的含义:bucket中未上传完毕的对象总个数
- 分段上传未上传成功会产生一个num_object (如果不是分段上传,强制停止的话也会作为一个完整的上传对象,不会在第一个箭头处+1,而是在第二个箭头处+1)
例子:
一个对象55M,对应的max_bucket为6,上传了2次之后,rgw.main中的num_objects=2,rgw.multimeta=0
当上传第三次的时候会失败,在第四个分段时报出配额不足的问题,bucket状态查询如下所示:
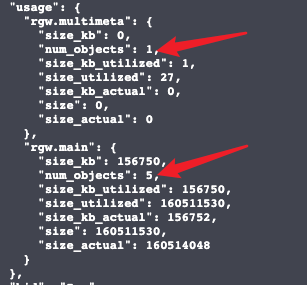
虽然说应该能够完成上传,因为2+4=6,但是我猜测还有一次是告诉ceph上传完毕,从而导致整个过程变为了2+5>max_object
总结
1. <font color=red>分段上传一定要获得最终的结果,如果上传失败一定要记得清理</font>
2. rgw.main中的num_objects代表的是真正上传成功的个数,包括分段上传中上传成功的个数
3. rgw.multimeta中的num_objects代表的是所有未上传成功的个数,比如说分段上传中上传失败的个数(失败比如说网络中断、强制停止上传)
4. Quota中的max_objects需要>2+3中的nums_objects才能继续完成上传
5. Quota中的max_size_kb需要>2+3中的size_kb_utilized才能继续完成上传
6. 定期清理失败的上传对象
清理操作参考:https://blog.csdn.net/qq_16327997/article/details/89635115
ceph pg
参考(https://rcblog.erc.monash.edu.au/blog/2018/04/ceph-placement-group-scrubbing/)
-
查看pg对应的osd
ceph pg dump pgs_brief -
查看拥有某个osd的所有pg
比如下面显示的就是拥有osd0的所有pg
ceph pg dump pgs_brief | egrep '\[0,|UP_' -
查看指定osd上的scrub任务
ceph daemon osd.0 dump_scrubs -
查看哪些pg正在scrub
ceph pg dump pgs_brief |grep scrub -
调整ceph scrub策略
https://www.jianshu.com/p/a46f6d28167f
分享永久链接的生成方法
- 设置对象所在bucket的权限为public
- 设置对象的权限为public
- 生成链接(截取生成链接到第一个问号位置,不加上问号)















 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









