







前置准备
CentOS7、jdk1.8、scala-2.11.12、spark-2.4.5、hadoop-2.7.7、zookeeper-3.5.7
想要完成本期视频中所有操作,需要以下准备:
一、集群规划

二、集群配置
2.1 spark-env.sh
[xiaokang@hadoop01 conf]$ cp spark-env.sh.template spark-env.sh
export JAVA_HOME=/opt/moudle/jdk1.8.0_191
export SCALA_HOME=/opt/moudle/scala-2.11.12
# 添加上如下内容:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181 -Dspark.deploy.zookeeper.dir=/ha-spark"
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=24 -Dspark.history.fs.logDirectory=hdfs://hadoop01:9000/spark-jobhistory"
2.2 spark-defaults.conf
[xiaokang@hadoop01 conf]$ cp spark-defaults.conf.template spark-defaults.conf
#spark.master spark://hadoop01:7077
spark.master spark://hadoop01:7077,hadoop02:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:9000/spark-jobhistory
2.3 slaves
[xiaokang@hadoop01 conf]$ cp slaves.template slaves
hadoop01
hadoop02
hadoop03
2.4 分发
[xiaokang@hadoop01 ~]$ distribution.sh /opt/software/spark-2.4.5
三、启动集群
3.1 启动ha-hadoop集群
[xiaokang@hadoop01 ~]$ ha-hadoop.sh start
3.2 在hadoop01上启动spark集群
# 进入/opt/software/spark-2.4.5/sbin目录并启动集群
[xiaokang@hadoop01 sbin]$ ./start-all.sh
3.3 在hadoop02上启动备Master
# 进入/opt/software/spark-2.4.5/sbin目录并启动备Master
[xiaokang@hadoop02 sbin]$ ./start-master.sh
3.4 在hadoop01上启动任务历史服务器
# 进入/opt/software/spark-2.4.5/sbin目录并启动任务历史服务器
[xiaokang@hadoop01 sbin]$ ./start-history-server.sh
四、查看集群
4.1 jps进程查看
[xiaokang@hadoop01 sbin]$ call-cluster.sh jps
--------hadoop01--------
10784 DFSZKFailoverController
13185 Master
10226 NameNode
13380 HistoryServer
13285 Worker
10902 JobHistoryServer
10024 QuorumPeerMain
10569 JournalNode
10346 DataNode
10989 NodeManager
13470 Jps
--------hadoop02--------
7569 JournalNode
7809 ResourceManager
7714 DFSZKFailoverController
7896 NodeManager
7385 NameNode
9513 Master
7290 QuorumPeerMain
7466 DataNode
9613 Jps
9439 Worker
--------hadoop03--------
8547 Worker
7588 ResourceManager
8613 Jps
7463 JournalNode
7703 NodeManager
7272 QuorumPeerMain
7357 DataNode
4.2 Web UI查看
[xiaokang@hadoop01 sbin]$ cat /opt/software/spark-2.4.5/logs/spark-xiaokang-org.apache.spark.deploy.master.Master-1-hadoop01.out | grep MasterWebUI
20/05/31 08:32:08 INFO MasterWebUI: Bound MasterWebUI to 0.0.0.0, and started at http://hadoop01:8081
通过启动日志可以看到hadoop01的MasterWebUI的端口号为8081

[xiaokang@hadoop02 sbin]$ cat /opt/software/spark-2.4.5/logs/spark-xiaokang-org.apache.spark.deploy.master.Master-1-hadoop02.out | grep MasterWebUI
20/05/31 08:32:43 INFO MasterWebUI: Bound MasterWebUI to 0.0.0.0, and started at http://hadoop02:8082
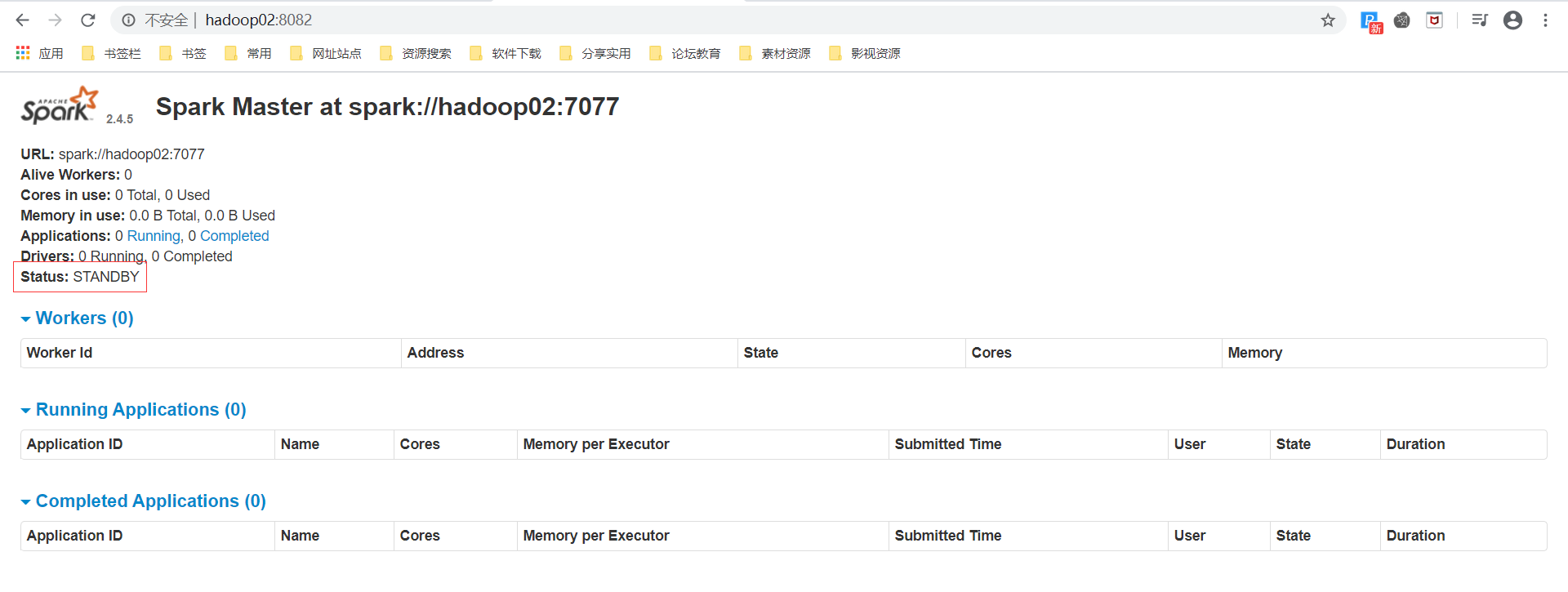
通过启动日志可以看到hadoop02的MasterWebUI的端口号为8082
hadoop01上的任务历史服务器端口号为18080

五、计算 PI (测试高可用)
[xiaokang@hadoop01 ~]$ spark-submit --master spark://hadoop01:7077,hadoop02:7077 --executor-memory 1G --total-executor-cores 8 --executor-cores 2 --class org.apache.spark.examples.SparkPi /opt/software/spark-2.4.5/examples/jars/spark-examples_2.11-2.4.5.jar 10000
--executor-memory 1G 指定每个executor可用内存为1G
--total-executor-cores 8 指定所有executor使用的cpu核数为8个
--executor-cores 2 表示每个executor使用的 cpu 的核数
运行过程中将主Master给kill掉,测试是否高可用
[xiaokang@hadoop01 ~]$ kill -9 13185
杀掉主Master之后,程序还是同样在执行,可以看到hadoop02的MasterWebUI中状态显示为recovering

最终计算结果如下:

WebUI查看应用执行资源分配情况:

















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









