






关键词:分库分表,路由机制,跨区查询,MySQL 数据变更,分表数据查询管理器与线程技术的结合,Cache
前面已经讲过Mysql实现海量海量数据存储查询时,主要有几个关键点,分表,分库,集群,M-S,负载均衡。
其中分库分表是很重要的一点。分库是如何将海量的Mysql数据放到不同的服务器中,分表则是在分库基础上对数据现进行逻辑上的划分。
数据划分可有多种方式,找到一个主键后,可以按号段分,也可以Hash取模分,也可以选择在认证库中保存DB配置。具体如何选择具体情况具体分析。
划分后,就是后期的查找和维护工作了。为了实现快速查找,得有一个高效的查找机制,这里可以选择建索引的方法,并充分借鉴已有的成熟的路由技术。同时,增减数据时,还要考虑到索引的维护,数据迁移时,数据的重新分摊也是一个要考虑的问题。下面具体分析数据变更的情形:
大型应用中Mysql经常碰到数据无限扩充的情况。常用解决方案如下:
MySQL master/slave:只适合大量读的情形,未必适合海量数据。MySQL cluster:提供的可能不是大家想要那种功能。MySQL proxy: MySQL master/slave配合MySQL 5.1 partition:只是将一个表存储上逻辑分开,部分改善了性能,但是可扩展性仍然是问题。
MySQL对于海量数据按应用逻辑分表分数据库,通过程序来决定数据存放的表。但是
跨区查询是一个问题,当需要快速查找一个数据时你得准确知道那个数据存在哪个地方。为了达到这个目的,可以将分表逻辑放到中间层,这样上层的应用则就简单很多,也便于扩展。下面结合网上一个关于分表查询很好的例子分析:
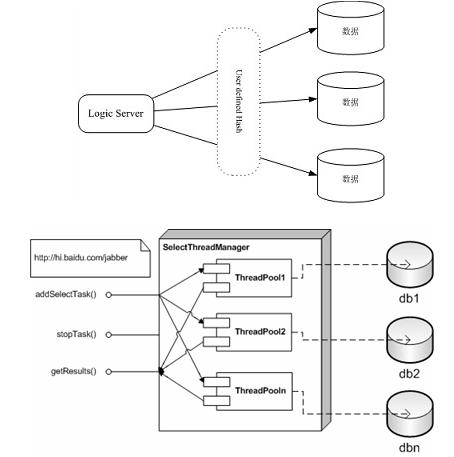
这里,SelectThreadManager分表数据查询管理器,它为分表的每个database or
server建立一个thread pool
addTask() -添加任务
stopTask() -停止任务
getResult() -获取执行结果
最快的执行时间=最慢的MySQL节点查询消耗时间
最慢的执行时间=超时时间
由于引入了线程思想,某个ThreadPool忙时候处理流程如下:1.假如ThreadPoolN非常忙,(也意味DB N非常忙);2.新的查询任务到来,addTask(),新的任务的一个thread加到ThreadPoolN任务排队中3.外层应用已经获得其他thread返回结果,继续等待4.外层应用等待超时的时间到,调用stopTask()设置该任务全部thread中的停止标志,外层应用返回。5.若干时间后,ThreadPoolN取到该排队Thread,因为设置了停止位,线程直接运行完成。
2. JDBC层实现做一个JDBC Driver的包装,拦截PreparedStatement, Statement的executeQuery(),然
后调用SelectThreadManager完成
3. MySQL partition
MySQL 5.1的partition功能由于单张表的数据跨文件,批量查询时候同样存在上述问题,不过它是在MySQL内部实现的,不需要外部调用者关心。其查询实现的原理应该大致类似。但partition只解决了IO的瓶颈,并不能解决CPU计算的瓶颈,因此无法代替传统的手工分表方式。
对于这个问题还有许多其他方法,学网络的应该很熟悉DNS的两种查询方法:递归方式和迭代方式。这些思路也可以应用到数据库查询中来并应用。如,HSCALE分表分数据库的思路:是在的基础上,在MySQL proxy的层面将上层的请求分配到实际的表上。实际的原理是通过拦截SQL进行替换和服务器重定向再将SQL传递到目标服务器上。它的分表算法可以由自定义的Lua脚本来实现,非常灵活。目前已经能支持同数据库分表,跨数据库的实现也将增加,因为在MySQL proxy的框架下,这并不是很困难的事情。使用HSCALE有2个开销,一是网络层面的,、MySQL proxy对每个SQL会增加0.0 ms级的网络延迟,如果增加了HSCALE,则会增加0. ms级延迟。第2个开销则是MySQL proxy, Lua, SQL解析,HSCALE算法等造成。现在的版本或许不是很成熟,但是在原理上基本上没多大障碍,发展下去将是一个不错的选择。具体可参照:。
海量数据查询时,还有很重要的一点,就是Cache的应用。不过是不是Cache在任何时候都是万能贴呢?不一定。Cache也命中率,维护等问题。而且在访问Cache时,系统会和一个单一的锁来对访问进行控制,这样最初的查询请求会被阻塞,直到锁释放。关于这个可以查看High Performance MySQLSecond Edition一书,中对此有很好的总结。
扩展知识:
DNS查询有两种试:递归方试和迭代方式。递归是如果被查询的名称服务器不是所请求的数据的权威,它将不得不向其他名字服务
器发出查询以获得答案。它可以向其他名字服务器发送递归查询,从而要求它们找到答案并返回。
迭代查询中名字服务器只用将它已知的最合适的答案返回给查询者。它本身不需要再有任何其他查询。被查询的名字服务器在它的本地数据中寻找所需数据。如果没有找到答案,它就在本地数据中找出与所要查询的名字服务器最接近的名字服务器的名字和地址,并作为指示返回给查询者,帮助它把解析过程进行下去。
分享到:


2012-07-30 20:23
浏览 3389
分类:数据库
评论















 2469
2469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









