






 本文详细介绍了如何使用Scrapy高级技巧应对网站的反爬策略,包括处理JavaScript重定向、验证码、用户代理过滤和标题一致性检查。通过创建自定义下载中间件,结合dryscrape库解决JavaScript重定向和验证码,最终成功抓取目标网站数据。
本文详细介绍了如何使用Scrapy高级技巧应对网站的反爬策略,包括处理JavaScript重定向、验证码、用户代理过滤和标题一致性检查。通过创建自定义下载中间件,结合dryscrape库解决JavaScript重定向和验证码,最终成功抓取目标网站数据。
介绍
我不会真的考虑网站刮我的爱好或任何东西,但我想我做了很多。看起来我所处理的许多事情都要求我掌握不能以任何其他方式获得的数据。我需要对Intoli的游戏进行静态分析,因此我需要搜索Google Play商店才能找到新游戏并下载游戏。该尖尖的球扩展需要从不同的网站和最简单的方式聚集梦幻足球预测是写一个刮刀。当我想起它时,我可能已经写了大约40-50个刮板。我并不是在向我的家人说谎我囤积了多少TB的数据......但我很接近。
我已经尝试过X光 / cheerio,nokogiri和其他一些,但我总是回到我个人的最爱:scrapy。在我看来,scrapy是一款优秀的软件。我不会轻易地抛出这种明确的赞誉,但它感觉非常直观,并且有很好的学习曲线。
您可以阅读The Scrapy教程并让您的第一个刮板在几分钟内运行。然后,当你需要做一些更复杂的事情时,你很可能会发现有一个内置的和有据可查的方式来做到这一点。有很大的权力建立在但框架的结构使得它保持你的出路,直到你需要它。当你最终确实需要某些默认情况下不存在的内容时,可以使用布隆过滤器进行重复数据删除,因为您访问的URL过多,无法存储到内存中,那么通常就像子类化其中一个组件并进行一些小改动一样简单。一切都感觉如此简单,这在我的书中确实是一个很好的软件设计的标志。
我已经玩了一段时间编写高级scrapy教程的想法。这些东西可以让我有机会展示它的一些可扩展性,同时解决实际中出现的现实挑战。尽管我想这样做,但我无法摆脱这样一个事实,即它似乎是一个决定性的举动,想要发布一些可能会导致某人的服务器受到bot流量攻击的东西。
晚上我可以睡得很好,只要遵循一些基本规则,就可以积极地尝试防止刮擦。也就是说,我保持我的请求率与我手动浏览时的请求率相当,并且我不会对数据做任何事情。这使得运行刮板基本上无法以任何重要的方式手动收集数据。即使我亲自遵守这些规则,对于人们可能真正想要抓取的特定网站,如何做指导仍然是一个过分的步骤。
因此,直到我遇到一个名为Zipru的洪流网站时,它仍然只是一个模糊的想法。它有多种机制,需要先进的抓取技术,但其robots.txt文件允许抓取。此外,没有理由刮掉它。它有一个公共API,可用于获取所有相同的数据。如果您有兴趣获取torrent数据,那么只需使用API; 这很好。
在本文的其余部分中,我将带领您撰写一个可以处理验证码和我们在Zipru网站上遇到的各种其他挑战的刮板。该代码不会完全按照书面方式工作,因为Zipru不是一个真正的网站,但所采用的技术广泛适用于现实世界的抓取并且代码完整。我假设你对python有基本的了解,但是我会尽力让这些对scrapy很少或根本不了解的人来说。如果事情一开始太快,那么花几分钟的时间阅读The Scrapy教程,其中将深入介绍介绍性内容。
设置项目
我们将在一个virtualenv内工作,这让我们可以封装我们的依赖关系。我们先来设置一个virtualenv ~/scrapers/zipru并安装scrapy。
mkdir ~/scrapers/zipru
cd ~/scrapers/zipru
virtualenv env
. env/bin/activate
pip install scrapy
您运行那些终端现在将被配置为使用本地virtualenv。如果你打开另一个终端,那么你需要. ~/scrapers/zipru/env/bin/active再次运行(否则你可能会得到有关命令或模块未被发现的错误)。
您现在可以通过运行创建一个新的项目脚手架
scrapy startproject zipru_scraper
这将创建以下目录结构。
└── zipru_scraper
├── zipru_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
大多数这些文件默认情况下并未实际使用,他们只是提出了一种理想的方式来构建我们的代码。从现在开始,您应该将其~/scrapers/zipru/zipru_scraper视为项目的顶级目录。这是任何scrapy命令应该运行的地方,也是任何相对路径的根源。
添加一个基本的蜘蛛
我们现在需要添加一个蜘蛛,以便让我们的刮板实际上做任何事情。蜘蛛是scrapy刮板的一部分,它处理解析文档以查找新的URL以提取和提取数据。我将非常依赖默认的Spider实现来最大限度地减少我们必须编写的代码量。这里的东西可能看起来有点自动化,但如果您查看文档,情况会更少。
首先,创建一个名为zipru_scraper/spiders/zipru_spider.py以下内容的文件。
import scrapy
class ZipruSpider(scrapy.Spider):
name = 'zipru'
start_urls = ['http://zipru.to/torrents.php?category=TV']
我们的蜘蛛继承了scrapy.Spider它,提供了一种start_requests()方法,可以通过start_urls它来开始我们的搜索。我们已经在start_urls这些点上提供了一个单独的URL 到电视列表。他们看起来像这样。
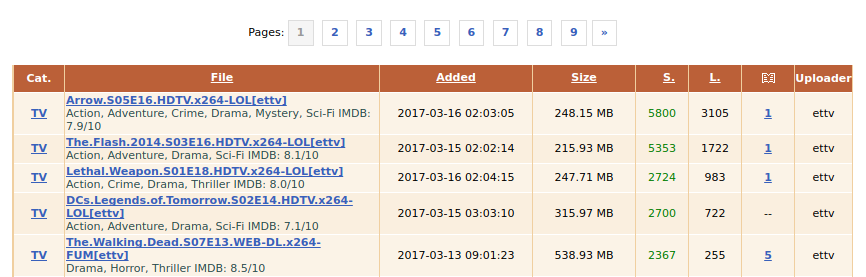
在顶部,您可以看到有链接指向其他页面。我们希望我们的刮板遵循这些链接并解析它们。为此,我们首先需要确定链接并找出它们指向的位置。
在这个阶段DOM检查员可以是一个巨大的帮助。如果要右键单击其中一个页面链接并在检查器中查看它,则会看到其他列表页面的链接如下所示
<a href="/torrents.php?...page=2" title="page 2">2</a>
<a href="/torrents.php?...page=3" title="page 3">3</a>
<a href="/torrents.php?...page=4" title="page 4">4</a>
接下来,我们需要为这些链接构造选择器表达式。有一些类似的搜索看起来更适合于css或xpath选择器,所以我通常倾向于混合并链接它们,有点自由。如果您不知道它,我强烈建议
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4377
4377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









