






文章目录
何为二分查找法
二分查找法的使用
C++中的二分查找法
左闭右开原则
lower_bound返回值说明
upper_bound返回值说明
使用Python实现lower_bound()
丑陋实现
优化实现
结尾
何为二分查找法
以下来自Wiki
在计算机科学中,二分搜索(英语:binary search),也称折半搜索(英语:half-interval search、对数搜索(英语:logarithmic search,是一种在有序数组中查找某一特定元素的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
二分查找法的使用
计算机世界里,快速查找是一个非常重要的话题,二分查找作为基础且重要的查找方法,值得深入学习。
使用二分查找的要点:
时间复杂度:O ( l o g n ) O(log~n)O(logn),原因在于每次把搜索区域减少一半
空间复杂度:O ( 1 ) O(1)O(1)
使用条件:有序数组
C++中的二分查找法
头文件: #include
主要使用的两个函数:
lower_bound(first, last, key)
upper_bound(first, last, key)
要说明的是,在有关数组界限中,一般使用左闭右开的原则,即(,]
左闭右开原则
大多数有关界限的问题,计算机世界中大多会使用左闭右开的原则,其原因归结于下:
上下界之差为元素个数
易于表现两个相邻区间,前一区间的下界,即为后一区间的上界
易于表达空集,上界不会大于下界
lower_bound返回值说明

lower_bound返回值ret与key的关系:
r e t ≥ k e y ret \ge keyret≥key
upper_bound返回值说明
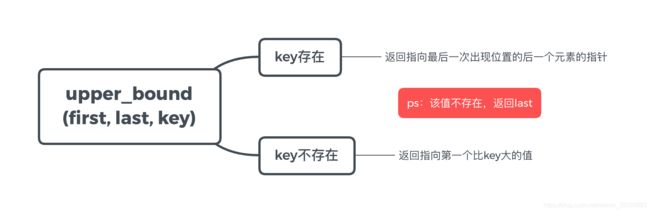
lower_bound返回值ret与key的关系:
r e t > k e y ret \gt keyret>key
使用Python实现lower_bound()
丑陋实现
def lower_bound(sublist, key):
"""
二分查找
:param sublist: 有序序列
:param key: 需要查找的值
:return: >= key
"""
l, r = 0, len(sublist)
while l < r: # 根据左闭右开原则, l < r 表示还有区域可搜索
# m = (l + r) // 2 存在溢出可能
m = l + (r - l) // 2
# 若搜索区域为偶数,则m中间靠右,即偏大
# 若搜索区域为奇数,则m中间
if sublist[m] > key:
# key在sublist[m]的左侧
r = m
elif sublist[m] < key:
# key 在sublist[m]的右侧
l = m + 1 # 左闭右开区间, m索引已经考虑,不符合,即不在搜索区域内
else:
# 相等下,遍历左侧搜索区域,该步骤可能会提高时间复杂度
for i in range(m - 1, l - 1, -1):
if sublist[i] != key:
return i + 1
# 出循环条件 l == r, 意味没有找到
if l < len(sublist) and sublist[l] < key:
l += 1
return l
优化实现
以上的实现,是最直观的实现方法,但非常冗长.
关键点:
如果key在数组中大量重复,会严重降低算法复杂度
最后返回值处理并不优雅,没有充分考虑到各种每次所选择的中间值(偶数情况)带来的问题
关键点1的解决:
应该依旧使用二分查找在剩下的区域中查找,从而避免算法退化
关键点2的解决:
考虑一种情况,key值不在数组中.
如果进行二分搜索,搜索范围应该是:
…->4->2->1
考虑4个元素情况下的一些情形(未列举完全):
如图所示,黄色为本次循环的middle值,即所考察的值。
而红色为key本该在的位置,箭头为最终指向的返回值。

通过图发现,每次返回的值与key的大小关系不固定。
而最终返回值期望是大于或等于key的值。
原因在于:如果为偶数元素个数情况下,small,(middle), big,在这次循环中,会选择big,从而导致大值被排除,剩下较小值,不满足返回条件
综上,代码修改如下:
def lower_bound(sublist, key):
"""
二分查找
:param sublist: 有序序列
:param key: 需要查找的值
:return: >= key
"""
l, r = 0, len(sublist)
while l < r:
m = l + (r - l - 1) // 2 # 选择靠左的值
if sublist[m] >= key:
# 在等于的情况下,考虑重复元素,要依旧在左侧寻找key,因此设置右界限为m
r = m
else:
l = m + 1
return r
结尾
曾经以为二分查找算法非常简单,但通过深入学习优秀的源码,以及自己动手,才发现并没有想象中的那么简单,想要写出优雅的算法代码,确实是需要多思考多动手的。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









