







参考:
https://developers.google.com/protocol-buffers/docs/encoding
protobuf的文件都是以【.proto】结尾,每一行都以英文分号【;】结束
1.定义版本
syntax = "proto3";
proto3语法, 如果不指定则会报错,且必须是.proto文件的除空行和注释内容之外的第一行

2.定义包名
后期生成go文件的包名
package 包名
3.定义消息类型
消息类型可以定义多个
消息类型的首字母是大写还是小写?
不管是首字母小写还是首字母大写,进行protoc 编译的时候,生成的go文件的结构体名称都是大写的对外可以被访问,所有并不用太在意消息类型名字的首字母大小写问题
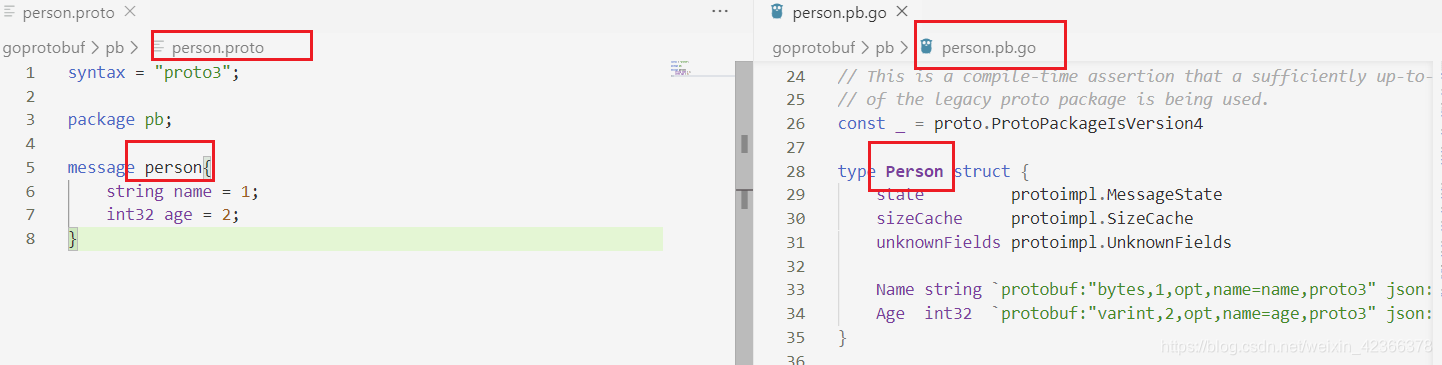
message 消息名{
}
4.定义消息字段
消息由至少一个字段组合而成,类似于Go语言中的结构体,每个字段都有一定的格式
// 注释
(字段修饰符) 数据类型 字段名称 = 唯一的编号标签值; // 注释【不建议在和代码同一行内写注释,如果后续使用grpc进行编译的话,注释的内容不存在】
不建议在和代码同一行内写注释,如果后续使用grpc进行编译的话,注释的内容不存在!!!
- 数据类型 :
| .proto类型 | Go类型 | 介绍 |
|---|---|---|
| double | float64 | 64位浮点数 |
| float | float32 | 32位浮点数 |
| int32 | int32 | 使用可变长度编码。编码负数效率低下——如果你的字段可能有负值,请改用sint32。 |
| int64 | int64 | 使用可变长度编码。编码负数效率低下——如果你的字段可能有负值,请改用sint64。 |
| uint32 | uint32 | 使用可变长度编码。 |
| uint64 | uint64 | 使用可变长度编码。 |
| sint32 | int32 | 使用可变长度编码。符号整型值。这些比常规int32s编码负数更有效。 |
| sint64 | int64 | 使用可变长度编码。符号整型值。这些比常规int64s编码负数更有效。 |
| fixed32 | uint32 | 总是四字节。如果值通常大于228,则比uint 32更有效 |
| fixed64 | uint64 | 总是八字节。如果值通常大于256,则比uint64更有效 |
| sfixed32 | int32 | 总是四字节。 |
| sfixed64 | int64 | 总是八字节。 |
| bool | bool | 布尔类型 |
| string | string | 字符串必须始终包含UTF - 8编码或7位ASCII文本 |
| bytes | []byte | 可以包含任意字节序列 |
- 字段名称:
protobuf建议以下划线命名而非驼峰式
student_name,而不是StudentName或者studentName的形式 - 唯一的编号标签:
可以看到消息定义的每个字段都有一个唯一的数字型标签. 这个标签用于在消息的二进制格式中标识字段, 一旦消息类型被使用后不可以再修改.
注意标签的值在1和15之间时编码只需一个字节, 包括标识值和字段类型(可以在Protocol Buffer Encoding中找到更多信息). 标签在16到2047之间将占用两个字节. 因此应该将从1到15的标签分派给最频繁出现的消息元素. 记得保留一些空间给未来可能添加的频繁出现的元素.
可以指定的最小的标签值是1, 最大的是2的29次方-1, 即536870911. 另外19000到19999(FieldDescriptor::kFirstReservedNumber through FieldDescriptor::kLastReservedNumber)不能使用, 因为Protocol Buffers的实现自己保留这个标签段.
- 注释格式:向.proto文件添加注释,可以使用C/C++/java/Go风格的双斜杠(//) 语法格式
5.重复
单数: 一个定义良好的消息可以有0个或1个此字段(但是不能超过1个).
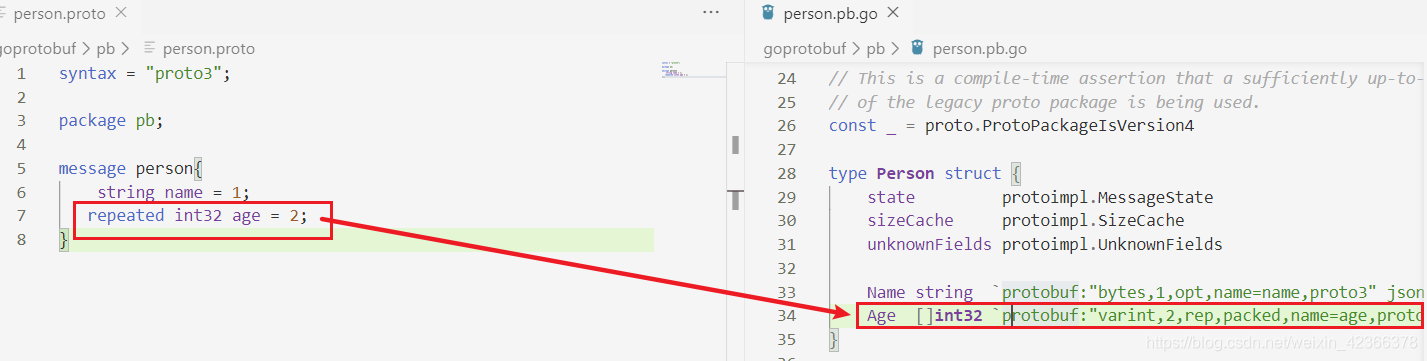
重复: 这个字段可以在定义良好的消息中重复任意次(包括0次).重复值的顺序将被维持原状.
由于历史原因, 简单数字类型的重复字段并没有编码为最有效率的方式. 新的代码应该使用特别选项[packed=true]来得到更有效率的编码. 例如:
repeated int32 age = 4 [packed=true];
重复字段的关键字是【repeated】,重复使用, 一般在go语言中用切片表示。
6.嵌套
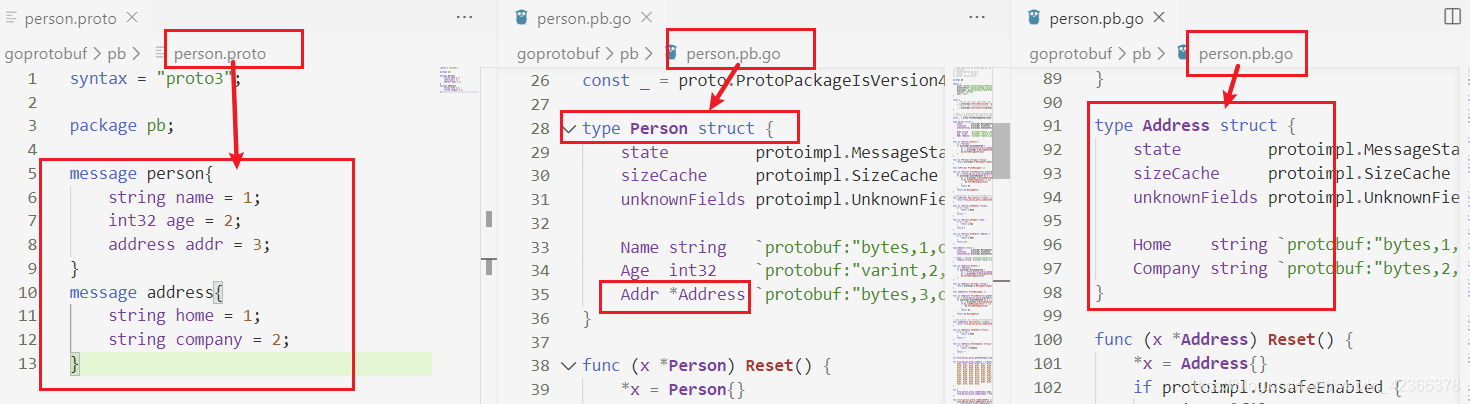
对应的生成的是go的嵌套
syntax = "proto3";
package pb;
message person{
string name = 1;
int32 age = 2;
address addr = 3;
}
message address{
string home = 1;
string company = 2;
}
7.枚举
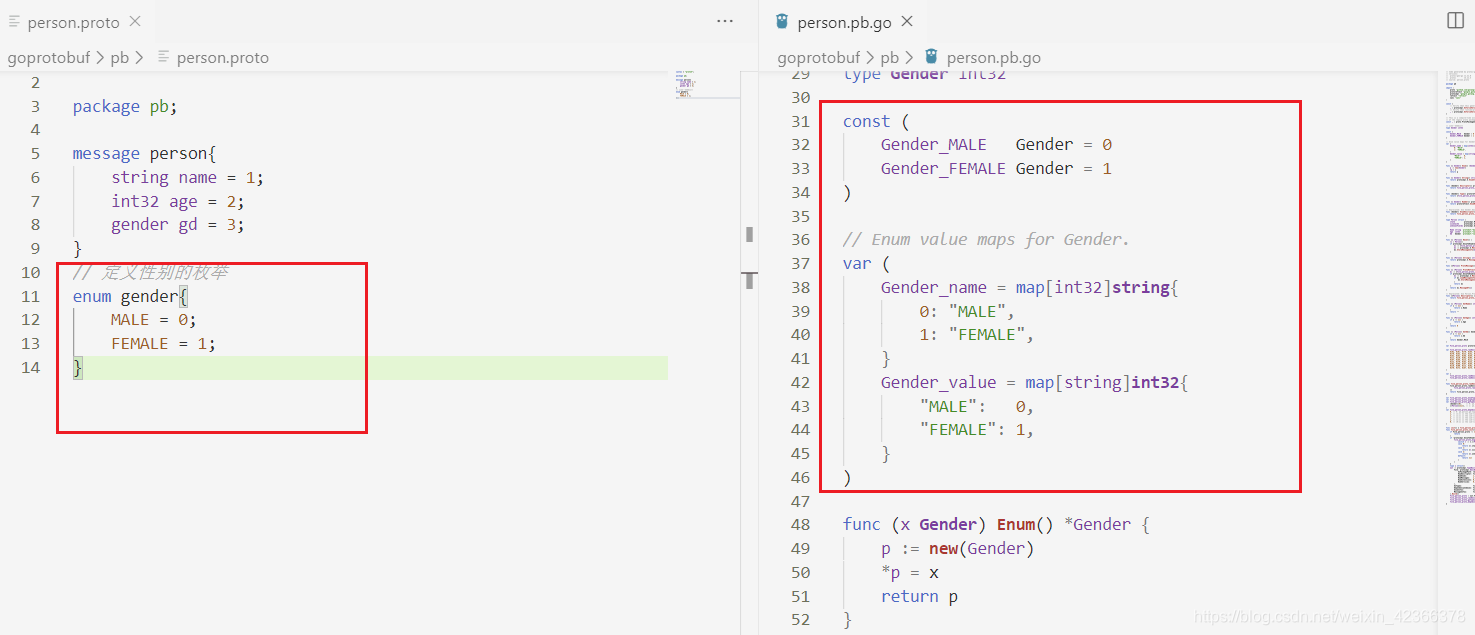
enum为关键字,作用为定义一种枚举类型
每个枚举定义必须包含一个映射到0的常量作为它的第一个元素。

8.默认缺省值
当一个消息被解析的时候,如果被编码的信息不包含一个特定的元素,被解析的对象锁对应的域被设置位一个默认值,对于不同类型指定如下:
- 对于strings,默认是一个空string
- 对于bytes,默认是一个空的bytes
- 对于bools,默认是false
- 对于数值类型,默认是0
9.基本编译
可以通过定义好的.proto文件来生成go,Java,Python,C++, Ruby, JavaNano, Objective-C,或者C# 代码,需要基于.proto文件运行protocolbuffer编译器protoc。
通过如下方式调用protocol编译器:
protoc --proto_path=IMPORT_PATH --go_out=DST_DIR path/to/file.proto
- –proto_path=IMPORT_PATH,IMPORT_PATH指定了 .proto 文件导包时的路径,如果忽略则默认当前目录。如果有多个目录则可以多次调用–proto_path,它们将会顺序的被访问并执行导入。
- –go_out=DST_DIR, 指定了生成的go语言代码文件放入的文件夹
- 允许使用
protoc --go_out=./ *.proto的方式一次性编译多个 .proto 文件 - 编译时,protobuf 编译器会把 .proto 文件编译成 .pd.go 文件
10.简化
可以通过以下命令对写好的proto文件进行编译
protoc --go_out=./ *.proto
对当前所有的.proto结尾的protobuf文件进行编译,编译的结果放在当前目录下














 2180
2180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









