







这是我第一次写博客,如果有写的不好的地方,希望各位多担待,并且可以指出我的错误所在。
Grep是什么东西呢?
grep (缩写来自Globally search a Regular Expression and Print)是一种强大的文本搜索工具,它能使用特定模式匹配(包括正则表达式)搜索文本。
这是我从百度百科上面复制来的,从这上面可以看出来Grep是一个文本搜索工具,简单来说,就是类似于windows里面搜索文本的一个工具。但是我们的这个hadoop是在linux上面运行的,而且我们这个案例实际上是在linux上面去寻找文件。
工具准备:
- linux系统
- 搭建好的Hadoop环境
案例演示步骤
(1)创建文件夹 input(当然,首先你得在/opt/module/hadoop-2.7.2,这个路径下面,这个是博主自己创建得路径,不同情况,不同路径)
[zhl@localhost hadoop-2.7.2]$ mkdir input
(2)将hadoop文件夹下得etc文件下以.xml结尾得文件拷贝到input下面来
执行下面这条语句:
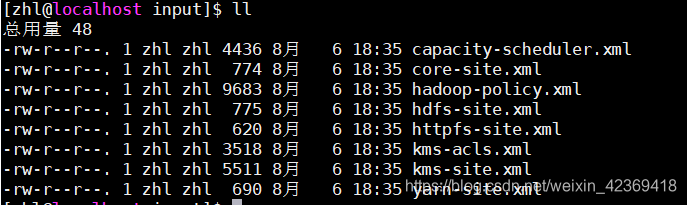
[zhl@localhost hadoop-2.7.2]$ cp etc/hadoop/*.xml input/
从这里就可以看到,input下面多了这些xml文件。
(3)到hadoop-2.7.2目录下执行以下语句
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input/ output 'dfs[a-z.]+'
这句话是什么意思呢,使用hadoop-mapreduce-examples-2.7.2.jar这个他原本就存在的案例,从input文件夹下面寻找到符合 'dfs[a-z.]+'这个正则表达式的文件名,放到output文件下面去。
但是要注意的是output文件不能一开始就存在,必须是不存在这个output文件,才能执行这个语句。
关于这个正则表达式的话,自己如果不懂的话,再去找找博客看下。
成功后的界面:
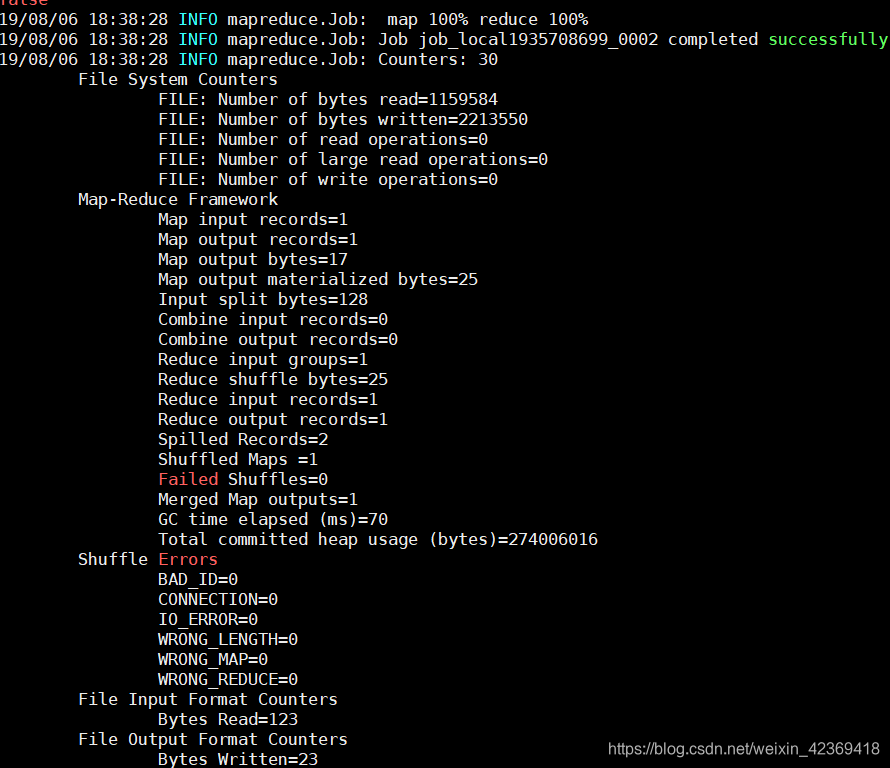
(4)查看结果
[zhl@localhost hadoop-2.7.2]$ cd output/
[zhl@localhost output]$ ll
总用量 4
-rw-r--r--. 1 zhl zhl 11 8月 6 18:38 part-r-00000
-rw-r--r--. 1 zhl zhl 0 8月 6 18:38 _SUCCESS
[zhl@localhost output]$ cat part-r-00000
1 dfsadmin
从以上可以看出来,_SUCCESS文件是表明已经成功了,没有错误,所以只是一个成功的标志。
在part-r-00000文件中可以看到,找到了一个文件符合我们正则表达式的文件名dfsadmin。
以上就是Grep的所有演示内容,如果有错误的话,希望各位指出来。
目前博主用的hadoop版本是2.7.2版本,如果需要下载的话,请跟博主联系。。。。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









