








作者:包寒吴霜
中科院心理所硕士在读(名字/人格/社会/文化心理学)
知乎:https://www.zhihu.com/people/psychbruce
社会科学研究经常会遇到“超多变量”的情况——多量表、多维度、多题项,以及复杂的正反计分题……如何更高效地计算量表总分?如何更简洁地进行反向计分?
本文将为大家分享如何使用R语言(data.table包 + 自编函数)优雅地计算多变量。
当我们的数据中存在成百上千个变量时,不仅变量管理存在一定的难度,而且变量计算也会变得比较复杂。如果使用R来处理,有哪些现存的方法呢?
dplyr包的mutate函数(需再次赋值给data)
1data=mutate(data, X=x1+x2+x3, Y=y1+y2+y3)data.table包的“:=”函数(原地更新,无需赋值)
1# 单变量计算2data[, X:=x1+x2+x3]3# 多变量同时计算4data[, ":="(X=x1+x2+x3, Y=y1+y2+y3)]变量少还好说,然而,一旦遇到几十个甚至几百个变量,我们都希望利用更简便的方法来计算总分或平均分,而不是一个个敲变量名。
首先,直接使用sum(...)或mean(...)是行不通的,大家可以自行尝试(算出来的其实是每一列的总分而不是每一行的总分)。实际上,我们需要用mapply把相关函数施加于各个变量上,这样才能分别对每一行计算总分:
1data[, ":="(Xsum=mapply(sum, x1, x2, x3))]这只是一个初步的解决思路,但依然尚未解决多变量的问题——我们并不想一个个敲变量名。
于是乎,针对大家经常遇到的一些变量计算需求,我编制了相应的R函数,既可以用于普通的data.frame(mutate),也可以用于data.table(:=)。
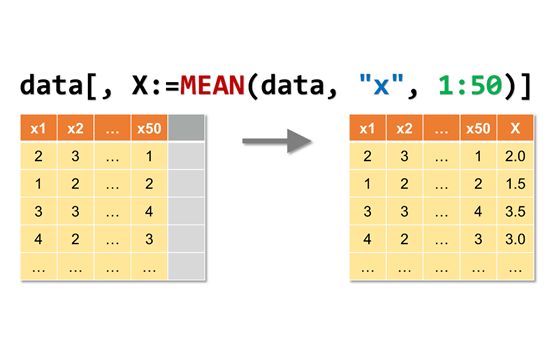
下面以计算平均值为例,介绍自编的MEAN函数的基本用法:
1data[, ":="(Xmean1=MEAN(data, "x", 1:50),2 Xmean2=MEAN(data, vars=c(& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









