






**
1.Java面向对象编程:封装、继承与多态
**
2024最全大厂面试题无需C币点我下载或者在网页打开全套面试题已打包
AI绘画关于SD,MJ,GPT,SDXL,Comfyui百科全书
封装:隐藏内部实现的魔法
封装是OOP的首要原则,它允许对象隐藏其内部实现细节,只暴露出一个可以被外界访问和使用的接口。在Java中,封装通过访问修饰符(如private、public、protected)来实现。
如何实现封装?
- 使用访问修饰符:将类的成员变量声明为
private,以隐藏其实现细节。 - 提供公共接口:通过
public方法(如getter和setter)来提供对私有成员的访问和修改。 - 实现信息隐藏:封装有助于减少耦合,提高代码的安全性和易于维护。
封装的好处
- 降低系统的耦合度:通过隐藏内部实现,减少外部对内部的依赖。
- 提高安全性:防止外部调用内部不应当访问的方法。
- 易于维护和扩展:封装使得修改内部实现时,对外部调用者透明。
继承:代码复用的利器
继承是OOP的另一个核心概念,它允许一个类(称为子类或派生类)继承另一个类(称为父类或基类)的属性和方法。
如何使用继承?
- 定义基类:创建一个定义了通用属性和方法的类。
- 派生子类:创建一个新类,它继承自基类,并添加或覆盖特定的行为。
- 使用
extends关键字:在Java中,子类通过extends关键字继承自父类。
继承的好处
- 代码复用:减少重复代码,提高开发效率。
- 建立层次结构:有助于创建清晰的类继承体系。
- 实现多态:继承是实现多态的基础。
多态:灵活的行为调度
多态是OOP的第三个核心概念,它允许不同类的对象对同一消息做出响应,但具体的行为会根据对象的实际类型而有所不同。
如何实现多态?
- 定义接口或抽象类:创建一个定义了一组方法的接口或抽象类。
- 实现多态类:不同的类实现相同的接口或继承自同一个抽象类,但提供不同的内部实现。
- 使用多态:通过接口或父类的引用调用方法,实际执行的将是对象实际类型的相应方法。
多态的好处
- 提高灵活性:允许将不同的实现作为一个通用的接口来对待。
- 增强扩展性:在不修改现有代码的情况下,可以引入新的类。
- 解耦合:将类的行为和实现分离,提高代码的可维护性。
在Java中,重载(Overloading)和重写(Overriding)是两个与方法相关的面向对象编程特性,它们都允许一个类中存在多个同名的方法,但它们的含义和用法有所不同。
**
2.重载和重写的区别
**
重载(Overloading)
重载指的是在同一个类中可以定义多个同名的方法,但它们的参数列表(参数的类型和数量)必须不同。重载是编译时多态的一个体现。
重载的特点:
- 参数列表不同:重载的方法必须在参数的数量或类型上有所区别。
- 返回类型不作为重载依据:仅有返回类型不同而参数列表相同的方法不构成重载。
- 访问修饰符不同:即使方法的访问修饰符不同,也可以构成重载。
- 发生在同一个类中:重载是同一个类中的方法重定义。
- 编译时解析:编译器在编译时根据方法签名(方法名和参数列表)来决定调用哪个重载的方法。
重写(Overriding)
重写指的是在子类中提供一个与父类中具有完全相同方法签名的方法。重写是运行时多态的一个体现。
重写的特点:
- 相同的方法签名:子类中重写的方法必须和父类中被重写的方法具有相同的方法名和参数列表。
- 返回类型相同或子类型:子类方法的返回类型应当与父类方法的返回类型相同或者是其子类型(协变返回类型)。
- 访问权限相同或更宽松:子类方法的访问权限不能比父类方法的访问权限更严格。
- 发生在父子类之间:重写涉及的是父子类之间的关系。
- 运行时解析:JVM在运行时根据对象的实际类型来决定调用哪个方法。
- 可以被
final、static或private方法阻止:如果父类中的方法被声明为final,则不能被重写;如果被声明为static,则需要使用相同的修饰符在子类中重新声明,这被称为隐藏;如果被声明为private,则不能被重写,因为私有方法对子类不可见。
区别总结:
- 作用范围:重载是同一个类的不同方法,重写是父子类之间的方法。
- 参数列表:重载要求参数列表不同,重写要求参数列表相同。
- 返回类型:重载方法的返回类型可以不同,重写方法的返回类型必须相同或为子类型。
- 实现多态的方式:重载是编译时多态,重写是运行时多态。
- 调用时机:重载由编译器在编译时根据方法签名决定,重写由JVM在运行时根据对象类型决定。
理解重载和重写的区别对于正确使用Java的面向对象特性至关重要,它们在设计灵活且可扩展的类层次结构中发挥着重要作用。
**
架构设计原则
**
1. 单一职责原则
单一职责原则(SRP)是面向对象设计中的重要原则,它要求一个类应该只有一个引起它变化的原因。换句话说,一个类应该只负责一项职责。这样做的好处是使类的设计更加清晰、可维护性更高,并且降低了对其他类的影响。
让我们以一个简单的示例来说明单一职责原则的应用。假设我们正在开发一个学生管理系统,其中有一个Student类负责表示学生的基本信息,如下所示:
public class Student {
private String name;
private int age;
private String address;
// 构造方法、getter和setter方法等
}
这个Student类负责表示学生的基本信息,包括姓名、年龄和地址。根据单一职责原则,我们可以将其拆分为独立的类,每个类负责一个职责。例如,我们可以创建一个StudentInfo类来负责管理学生的基本信息,如下所示:
public class StudentInfo {
private String name;
private int age;
private String address;
// 构造方法、getter和setter方法等
// 其他与学生基本信息相关的方法
}
通过拆分职责,我们可以更好地管理和扩展学生管理系统。这样,当我们需要修改学生基本信息的处理逻辑时,只需要修改StudentInfo类,而不会对其他类产生影响。
2. 开放封闭原则
开放封闭原则(OCP)是软件工程中的一个基本原则,它要求软件实体(类、模块、函数等)应该对扩展开放,对修改封闭。换句话说,我们应该通过添加新的代码来扩展系统的功能,而不是修改已有的代码。
让我们通过一个示例来说明开放封闭原则的应用。假设我们有一个订单处理系统,其中有一个Order类负责处理订单的创建和支付,如下所示:
public class Order {
private String orderId;
private double amount;
private boolean isPaid;
// 构造方法、getter和setter方法等
public void createOrder() {
// 创建订单的逻辑
}
public void makePayment() {
// 支付订单的逻辑
}
}
现在,我们需要为订单增加一个新的功能:发送确认邮件给客户。根据开放封闭原则,我们不应该直接修改Order类的代码来实现这个新功能,而是应该通过扩展来实现。我们可以创建一个新的类OrderConfirmation,负责发送确认邮件的逻辑,如下所示:
public class OrderConfirmation {
public void sendConfirmationEmail(String orderId) {
// 发送确认邮件的逻辑
}
}
通过这种方式,我们遵循了开放封闭原则,通过扩展OrderConfirmation类来添加发送确认邮件的功能,而不是修改Order类的代码。
3. 里氏替换原则
里氏替换原则(LSP)是面向对象设计中的一个重要原则,它要求子类对象可以替换父类对象,而不会影响程序的正确性。换句话说,子类应该能够完全替代父类并且可以在不破坏程序正确性的情况下使用。
让我们通过一个示例来说明里氏替换原则的应用。假设我们有一个图形类的继承体系,其中有一个Rectangle类表示矩形,如下所示:
public class Rectangle {
protected int width;
protected int height;
public Rectangle(int width, int height) {
this.width = width;
this.height = height;
}
public int getWidth() {
return width;
}
public void setWidth(int width) {
this.width = width;
}
public int getHeight() {
return height;
}
public void setHeight(int height) {
this.height = height;
}
public int calculateArea() {
return width * height;
}
}
现在,我们希望在图形类的继承体系中添加一个新的类Square表示正方形。根据里氏替换原则,我们应该确保子类对象(正方形)可以替换父类对象(矩形)而不会引起错误。然而,如果我们直接创建一个Square类继承自Rectangle类,并且重写setWidth和setHeight方法,会导致违反里氏替换原则,因为正方形的宽度和高度应该是相等的。
为了遵循里氏替换原则,我们可以重新设计继承体系,例如创建一个Shape类作为父类,Rectangle和Square类分别继承Shape类,并且共享一个抽象方法calculateArea,如下所示:
public abstract class Shape {
public abstract int calculateArea();
}
public class Rectangle extends Shape {
protected int width;
protected int height;
public Rectangle(int width, int height) {
this.width = width;
this.height = height;
}
// getter和setter方法
public int calculateArea() {
return width * height;
}
}
public class Square extends Shape {
protected int side;
public Square(int side) {
this.side = side;
}
// getter和setter方法
public int calculateArea() {
return side * side;
}
}
通过这种方式,我们保持了继承体系的一致性,并且确保子类对象(正方形)可以替代父类对象(矩形)而不会引起错误。
4. 依赖倒置原则
依赖倒置原则(DIP)是面向对象设计中的一个重要原则,它要求高层模块不应该依赖于低层模块,二者都应该依赖于抽象。换句话说,我们应该通过抽象来解耦高层模块和低层模块,并且依赖于抽象而不是具体实现。
让我们通过一个示例来说明依赖倒置原则的应用。假设我们正在开发一个订单处理系统,其中有一个OrderProcessor类负责处理订单,如下所示:
public class OrderProcessor {
private Database database;
public OrderProcessor() {
this.database = new Database();
}
public void processOrder(Order order) {
// 处理订单的逻辑
database.saveOrder(order);
}
}
在上述示例中,OrderProcessor类直接依赖于具体的Database类,导致高层模块(OrderProcessor)与低层模块(Database)之间存在紧耦合关系。
为了遵循依赖倒置原则,我们可以通过引入抽象来解耦高层模块和低层模块的依赖关系。我们可以创建一个抽象的Database接口,让OrderProcessor类依赖于该接口而不是具体实现类,如下所示:
public interface Database {
void saveOrder(Order order);
}
public class OrderProcessor {
private Database database;
public OrderProcessor(Database database) {
this.database = database;
}
public void processOrder(Order order) {
// 处理订单的逻辑
database.saveOrder(order);
}
}
public class MySQLDatabase implements Database {
public void saveOrder(Order order) {
// 使用MySQL数据库保存订单的逻辑
}
}
public class OracleDatabase implements Database {
public void saveOrder(Order order) {
// 使用Oracle数据库保存订单的逻辑
}
}
通过引入抽象的Database接口,我们将高层模块(OrderProcessor)与低层模块(具体的数据库实现类)解耦,并且依赖于抽象而不是具体实现。这样,我们可以轻松地切换不同的数据库实现,而不会对OrderProcessor类产生影响。
5. 接口隔离原则
接口隔离原则(ISP)是面向对象设计中的一个重要原则,它要求客户端不应该依赖于它不需要的接口。换句话说,我们应该将大接口拆分为小接口,让客户端只依赖于它需要的接口。
让我们通过一个示例来说明接口隔离原则的应用。假设我们有一个图形编辑器,其中有一个Shape接口表示图形,如下所示:
public interface Shape {
void draw();
void resize();
void rotate();
}
现在,我们希望添加一个新的功能:填充图形的颜色。根据接口隔离原则,我们应该将大接口拆分为小接口,让客户端只依赖于它需要的接口。所以,我们可以将Shape接口拆分为Drawable接口和Resizable接口,如下所示:
public interface Drawable {
void draw();
}
public interface Resizable {
void resize();
}
public interface Shape extends Drawable, Resizable {
void rotate();
}
通过这种方式,我们将大接口Shape拆分为小接口Drawable和Resizable,让客户端只需要依赖于它们需要的接口。这样,当我们需要添加填充颜色的功能时,只需要让图形类实现Drawable接口即可,而不需要修改已有的代码。
6. 合成复用原则
合成复用原则(CRP)是面向对象设计中的一个重要原则,它要求尽量使用对象组合而不是继承来达到代码复用的目的。换句话说,我们应该优先使用对象组合来构建系统,而不是过度依赖继承。
让我们通过一个示例来说明合成复用原则的应用。假设我们正在开发一个游戏,其中有一个Character类表示游戏中的角色,如下所示:
public class Character {
private Weapon weapon;
public Character() {
this.weapon = new Sword();
}
public void attack() {
weapon.use();
}
}
在上述示例中,Character类通过继承和创建具体的武器类(Sword)来实现攻击功能。然而,这种使用继承的方式可能导致系统的扩展和维护困难。
为了遵循合成复用原则,我们可以使用对象组合来实现攻击功能。我们可以创建一个Weapon接口,让Character类组合一个实现了Weapon接口
接口与抽象类的区别
在Java中,接口(Interface)和抽象类(Abstract Class)都是实现面向对象编程中的抽象概念的工具。它们都可以用来定义一组抽象的方法,这些方法可以由实现类(Implementing Class)或子类(Subclass)来实现(提供具体的实现)。尽管它们有相似之处,但它们之间存在一些关键的区别:
接口(Interface)
- 定义:接口是一种完全抽象的概念,它定义了一组抽象方法,这些方法可以由实现类来实现。
- 实现:一个类可以使用
implements关键字来实现一个或多个接口。 - 构造方法:接口不能有构造方法。
- 方法默认修饰符:在Java 8及以前的版本中,接口中的方法默认是
public abstract的,不能有方法体。从Java 8开始,接口可以包含默认方法(带有方法体的public static方法)和静态方法。 - 属性:接口中的属性默认是
public static final的,即常量。 - 多继承:一个类可以实现多个接口,这是Java实现多继承的一种方式。
- 类层次结构:接口不形成类层次结构。
抽象类(Abstract Class)
- 定义:抽象类是一种包含抽象方法的类,它既可以定义抽象方法也可以定义具体方法。
- 实现:一个类可以通过
extends关键字继承一个抽象类。 - 构造方法:抽象类可以有构造方法。
- 方法默认修饰符:抽象类中可以有抽象方法(没有方法体)和具体方法(有方法体)。
- 属性:抽象类中的属性没有默认的修饰符,需要显式声明。
- 多继承:一个类只能继承一个抽象类,因为Java不支持类的多继承。
- 类层次结构:抽象类形成类层次结构的一部分。
区别总结:
- 抽象程度:接口是完全抽象的,而抽象类可以包含具体的方法实现。
- 实现方式:类通过
implements实现接口,通过extends继承抽象类。 - 构造方法:接口不能有构造方法,抽象类可以有。
- 方法实现:接口中的方法默认是抽象的,直到Java 8才允许有默认和静态方法;抽象类可以有抽象和具体方法。
- 属性:接口的属性默认是常量,抽象类中的属性没有默认修饰符。
- 多继承:一个类可以实现多个接口,但不能继承多个抽象类。
- 类层次:抽象类形成类层次结构,而接口不形成。
在设计类和接口时,通常会根据以下准则来选择使用接口还是抽象类:
- 当你关注的是行为规范而不是具体的实现时,使用接口。
- 当你需要共享一些代码,或者需要定义一些具体的方法实现时,使用抽象类。
选择使用接口还是抽象类取决于具体的应用场景和设计需求。在Java 8之后,由于接口可以包含具有方法体的默认方法,这使得接口在某些情况下可以作为更灵活的抽象类型来使用。
在Java中,泛化关系和实现关系是面向对象编程的两个基本概念,它们描述了类与类、类与接口之间的不同连接方式。
泛化关系(Generalization)
泛化关系通常指的是继承关系,即一个类(子类或派生类)继承另一个类(父类或基类)的属性和方法。这种关系建立了一个“是一个”(is-a)的关系。
泛化关系的特点:
- 继承:子类继承父类的所有公共和受保护的属性和方法。
- 多态:子类可以扩展或重写父类的方法,实现多态性。
- 访问权限:子类可以访问父类中所有非私有的成员。
- 单一继承:在Java中,每个类只能有一个直接父类,即Java不支持类的多重继承。
实现关系(Implementation)
实现关系指的是一个类对一个或多个接口的实现。这种关系建立了一个“可以是”(can-be-a)或“像一个”(like-a)的关系。
实现关系的特点:
- 接口实现:一个类实现了接口中定义的所有方法,从而提供了接口声明的行为。
- 多重实现:一个类可以实现多个接口,这是Java实现多继承的一种方式。
- 抽象性:接口是完全抽象的,它们不提供方法的具体实现,只定义了方法的签名。
- 灵活性:实现关系提供了一种机制,允许类具有多个抽象类型。
区别:
- 关系类型:泛化关系是一种特殊的实现关系,其中子类是父类的特化。实现关系是类与接口之间的关联。
- 继承:泛化关系涉及继承,而实现关系不涉及继承。
- 多重:泛化关系中,Java不支持多重继承,但实现关系允许一个类实现多个接口。
- 实现方式:泛化关系通过
extends关键字实现,实现关系通过implements关键字实现。 - 目的:泛化用于建立一个继承体系,实现关系用于定义一组可以由多个类实现的接口。
联系:
- 多态性:两者都支持多态性。在泛化关系中,可以通过父类引用来操作子类对象;在实现关系中,可以通过接口引用来操作实现了接口的类的对象。
- 设计原则:它们都是面向对象设计原则的体现,有助于降低耦合度,提高代码的可重用性和可维护性。
在实际应用中,泛化关系和实现关系经常结合使用,以构建灵活和可扩展的系统。选择使用泛化关系还是实现关系取决于设计的具体需求,以及如何平衡代码的抽象性和具体性。
数据类型
Java是一种静态类型语言,这意味着在编译时就需要确定所有变量的类型。Java提供了两种基本的数据类型:基本类型和引用类型。
基本类型
基本类型是Java中最简单的数据类型,它们直接对应于计算机的最小数据单位。Java有八种基本类型:
- 整数类型:
byte,short,int,long - 浮点类型:
float,double - 字符类型:
char - 布尔类型:
boolean
引用类型
引用类型是对象的引用,它们指向内存中的对象。在Java中,除了基本类型之外的都是引用类型,包括类、接口、数组等。
基本类型的深入解析
整数类型
整数类型用于表示整数值,它们在内存中的大小是固定的。例如,int类型占用4个字节(32位),可以表示从-231到231-1的整数。
int number = 10; // 正确的整数赋值
int largeNumber = 2147483647; // 最大值赋值
// int tooLargeNumber = 2147483648; // 超出范围的赋值,会编译错误
浮点类型
浮点类型用于表示有小数点的数值。float类型占用4个字节,而double类型占用8个字节,后者提供更高的精度。
float pi = 3.14f; // float类型的赋值
double piDouble = 3.141592653589793; // double类型的赋值
字符类型
char类型用于表示单个字符,它占用2个字节。字符类型使用单引号表示。
char letter = 'A'; // 字符类型的赋值
布尔类型
boolean类型用于表示逻辑值,它只有两个可能的值:true和false。
boolean isTrue = true; // 布尔类型的赋值
引用类型的奥秘
引用类型是Java中更高级的概念,它们指向内存中的对象。在Java中,所有的对象都是通过引用来操作的。
String name = "Java"; // String是一个引用类型
类型转换
在Java中,类型转换是将一种数据类型转换为另一种数据类型的过程。这可以是自动的(隐式)或显式的(强制)。
int number = 10;
long largeNumber = number; // 隐式类型转换
类型提升
在某些情况下,当操作涉及不同类型的数值时,较小的数据类型会自动转换为较大的数据类型,这个过程称为类型提升。
int number = 10;
double pi = 3.14;
double result = number / pi; // 结果是double类型
数据类型的应用
在实际编程中,选择合适的数据类型对于性能和内存管理至关重要。例如,如果你知道一个数值不会超过255,那么使用byte类型会比使用int更节省内存。
byte smallNumber = 10; // 使用byte类型
在Java中,基本类型(primitive types)和包装类型(wrapper types)之间的转换是常见的操作。基本类型是Java的原始数据类型,而包装类型是基本类型的封装,它们是java.lang包中的类。
基本类型(Primitive Types):
- boolean
- byte
- short
- int
- long
- float
- double
- char
包装类型(Wrapper Types):
- Boolean
- Byte
- Short
- Integer
- Long
- Float
- Double
- Character
自动装箱(Autoboxing)和拆箱(Unboxing):
从Java 5开始,Java引入了自动装箱和拆箱的特性,使得在基本类型和对应的包装类型之间可以自动转换。
自动装箱(Autoboxing):
基本类型转换为对应的包装类型。
Integer integerObject = 123; // int到Integer的自动装箱
自动拆箱(Unboxing):
包装类型转换为对应的基本类型。
int intValue = integerObject; // Integer到int的自动拆箱
显式装箱(Explicit Boxing)和拆箱(Explicit Unboxing):
虽然自动装箱和拆箱非常方便,但有时候需要显式地进行类型转换。
显式装箱(Explicit Boxing):
使用包装类型的静态方法valueOf()进行装箱。
Integer integerObject = Integer.valueOf(123); // 显式装箱
显式拆箱(Explicit Unboxing):
使用包装类型的xxxValue方法进行拆箱。
int intValue = integerObject.intValue(); // 显式拆箱
注意事项:
- 性能:频繁的装箱和拆箱可能会影响性能,特别是在循环中,因为它涉及到对象的创建和垃圾收集。
- null值:包装类型可以为null,而基本类型不可以。在进行自动拆箱时,如果包装类型为null,会抛出
NullPointerException。 - 比较:包装类型的比较涉及到对象的引用比较,如果要比较两个包装类型的值,应该使用
equals()方法。对于浮点数,由于精度问题,比较时要小心。 - 缓存:从Java 5开始,
Integer类有一个缓存机制,它缓存了从-128到127的整数值。当访问这个范围内的整数值时,实际上是返回缓存中的对象,而不是每次创建新对象。
示例:
public class BoxingUnboxingExample {
public static void main(String[] args) {
// 自动装箱
int num = 100;
Integer wrapper = num; // 自动装箱
// 自动拆箱
int number = wrapper; // 自动拆箱
// 显式装箱
Integer wrapper2 = Integer.valueOf(100);
// 显式拆箱
int number2 = wrapper2.intValue();
// 使用equals()方法比较包装类型的值
Integer a = 10;
Integer b = 10;
Integer c = 200;
boolean areEqual = (a.intValue() == b.intValue()); // true
boolean areNotEqual = (a.equals(c)); // false
}
}
理解基本类型与包装类型之间的转换对于编写正确和高效的Java程序非常重要。
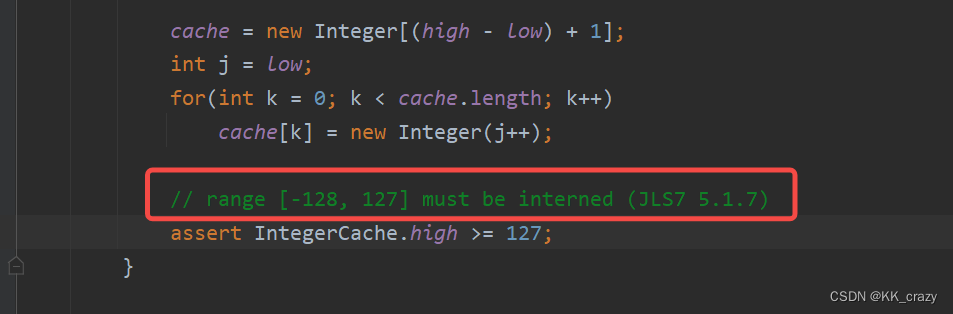
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
@HotSpotIntrinsicCandidate
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
must be interned :被拘留的
/**
* Cache to support the object identity semantics of autoboxing for values between
* -128 and 127 (inclusive) as required by JLS.
*
* The cache is initialized on first usage. The size of the cache
* may be controlled by the {@code -XX:AutoBoxCacheMax=<size>} option.
* During VM initialization, java.lang.Integer.IntegerCache.high property
* may be set and saved in the private system properties in the
* jdk.internal.misc.VM class.
*/
/**
*缓存以支持之间的值的自动装箱的对象标识语义
*-128和127(包括在内),按照JLS的要求。
*
*缓存在首次使用时初始化。缓存的大小
*可以由{@code-XX:AutoBoxCacheMax=<size>}选项控制。
*在VM初始化期间,java.lang.Integer。IntegerCache.high属性
*可以设置并保存在中的专用系统属性中
*jdk.internal.misc。VM类。
*/
在Java编程中,对Integer对象的创建和使用是常见的操作。然而,很多开发者可能没有意识到,通过不同的方法创建Integer对象,其背后的实现机制和性能影响可能截然不同。
缓存池机制
Java为Integer类提供了一个缓存池,在Integer.valueOf(int i)方法的实现中,有一个内部的缓存机制。根据Java的自动装箱规范,Integer.valueOf()方法会缓存从-128到127范围内的Integer对象。
Integer.valueOf(int i)的缓存逻辑:
- 如果输入的
int值在-128到127之间(包括-128和127),valueOf()方法将返回一个缓存的对象。 - 如果输入的
int值超出这个范围,valueOf()方法将创建一个新的Integer对象。
new Integer(int i)的行为:
- 无论
int值是什么,new Integer(int i)总是会创建一个新的Integer对象实例。
性能考量
使用Integer.valueOf()而不是直接使用new操作符可以减少内存使用和垃圾收集的开销,特别是当处理大量Integer对象时,尤其是它们的值集中在上述的缓存范围内。
实际案例演示
案例1:比较valueOf和new的性能
public class IntegerCachingDemo {
public static void main(String[] args) {
int number = 127;
Integer i1 = new Integer(number);
Integer i2 = Integer.valueOf(number);
System.out.println("i1 == i2 ? " + (i1 == i2)); // 输出 true,因为valueOf返回了缓存的对象
int anotherNumber = 128;
Integer i3 = new Integer(anotherNumber);
Integer i4 = Integer.valueOf(anotherNumber);
System.out.println("i3 == i4 ? " + (i3 == i4)); // 输出 false,因为valueOf没有缓存这个值,创建了新对象
}
}
案例2:循环创建大量Integer对象
public class IntegerLoopCreation {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 200; i++) {
// 使用valueOf()创建缓存范围内的Integer对象
list.add(Integer.valueOf(i));
// 使用new创建Integer对象,即使在缓存范围内也会创建新对象
list.add(new Integer(i));
}
}
}
在Java中,基本类型对应的缓冲池主要指的是Integer类的缓存池,因为其他的基本类型(如int, long, double等)并不具有类似的缓存机制。这个缓存池是由Java虚拟机(JVM)自动管理的,旨在提高性能,特别是在创建大量相同整数值的Integer对象时。
Integer缓存池的工作原理:
-
缓存范围:根据Java的自动装箱规范,
Integer.valueOf(int i)和Integer.valueOf(String s)方法会缓存从-128到127(包括-128和127)的Integer对象。 -
自动装箱:当自动装箱一个
int值到Integer对象时,如果该值在缓存范围内,就会使用缓存池中的实例,而不是每次调用都创建一个新的对象。 -
自动拆箱:与自动装箱相对应,自动拆箱一个
Integer对象时,如果该对象是缓存池中的对象,那么拆箱后的int值将直接指向这个缓存的Integer对象。 -
缓存池大小:缓存池的大小是固定的,不会随着JVM堆的大小变化而变化。
-
线程安全:由于缓存池的大小有限,且在多线程环境下可能会有多个线程尝试获取同一个缓存对象,因此JVM确保了缓存池的线程安全。
缓存池的相关方法:
-
Integer.valueOf(int i):如果参数i在-128到127之间,此方法将返回缓存池中的Integer对象。 -
Integer.valueOf(String s):将字符串参数转换为int值,并返回对应的Integer对象,同样会利用缓存池。 -
Integer.valueOf()的其他重载版本:如接受long、float、double等类型的参数,但它们不会使用缓存池。
缓存池的使用场景:
缓存池主要用于以下场景:
-
频繁创建相同整数值的
Integer对象:例如,数据库操作中的ID字段,或者配置项中的整数值。 -
集合类:在使用如
HashSet、HashMap等集合类时,如果键或值是Integer类型,缓存池可以减少内存占用和提高性能。
注意事项:
-
缓存池限制:由于缓存池的大小限制,对于超出范围的整数值,每次创建
Integer对象时都会生成新的实例。 -
内存使用:大量使用缓存池可能会影响JVM的内存使用,尤其是在缓存池大小不足以满足需求时。
-
性能测试:在某些情况下,使用缓存池可能会提高性能,但在其他情况下,可能不会有显著的性能提升。因此,对于性能敏感的应用,建议进行性能测试。
相关案例Demo:
public class IntegerCacheDemo {
public static void main(String[] args) {
Integer int1 = 123;
Integer int2 = 123;
System.out.println(int1 == int2); // 输出 false,因为123不在缓存池范围内
Integer int3 = Integer.valueOf(123);
Integer int4 = Integer.valueOf(123);
System.out.println(int3 == int4); // 输出 true,因为valueOf使用了缓存池
}
}
在这个示例中,直接使用new Integer(123)创建的两个对象int1和int2不相等,因为它们是两个不同的实例。而使用Integer.valueOf(123)创建的两个对象int3和int4相等,因为它们引用了缓存池中的同一个实例。
通过理解基本类型对应的缓冲池,开发者可以更好地利用Java的自动装箱特性,编写出更高效、更节省资源的代码。
在Java面试中,String类常常是面试官喜欢探讨的话题之一,因为它不仅涉及到Java的基础知识,还与性能优化紧密相关。以下是一些关于String的重要知识点以及在项目开发中应当避免的错误。
Java中String的面试知识点:
字符串是常量;它们的值在它们之后不能更改
*创建。字符串缓冲区支持可变字符串。
*因为String对象是不可变的,所以它们可以共享
-
不可变性:
String对象一旦创建,其值就不能被改变。 -
字符串常量池:在JVM中,字符串常量会存储在字符串常量池中,以节省内存空间。
-
字符串连接:在循环中使用
+操作符连接字符串会导致性能问题,因为每次循环都会创建一个新的String对象。推荐使用StringBuilder或StringBuffer。 -
equals()方法:用于比较字符串的内容是否相等。 -
hashCode()方法:返回字符串的哈希值,由字符串的内容决定。 -
substring()方法:返回字符串的子串。 -
indexOf()和lastIndexOf()方法:分别返回指定字符或子串在此字符串中第一次和最后一次出现的索引。 -
trim()方法:去除字符串两端的空白字符。 -
valueOf()方法:将其他对象转换为字符串形式。 -
split()方法:根据分隔符分割字符串。 -
replace()和replaceAll()方法:分别替换字符串中第一次出现的和所有匹配的子串。 -
toLowerCase()和toUpperCase()方法:将字符串转换为小写或大写。 -
isEmpty()方法:检查字符串是否为空。 -
length()方法:返回字符串的长度。 -
intern()方法:将字符串对象与字符串常量池中的对象进行比较,如果常量池中已存在该字符串,则返回常量池中的对象引用。
项目开发中需要避免的错误:
-
避免在循环中创建字符串:如前所述,这会导致大量的内存消耗和垃圾收集。
-
避免使用
new String("..."):这会创建不必要的新字符串对象,而使用原始字符串字面量可以直接引用字符串常量池中的对象。 -
避免在字符串比较时使用
==操作符:这会检查对象引用是否相等,而不是字符串的内容。应该使用equals()方法。 -
避免在字符串操作中忽略
null检查:在调用字符串的方法之前,应确保字符串不为null,以避免NullPointerException。 -
避免使用
String作为集合键:由于String的不可变性,它非常适合作为集合的键。但如果你使用了一个继承自String的可变类作为键,那么可能会违反集合的不变性要求。 -
避免在多线程环境中使用
StringBuffer:StringBuffer的方法不是线程安全的。在这种情况下,应使用StringBuilder(如果字符串的共享不重要)或ReentrantLock和AtomicReference等同步机制。 -
避免使用
String来存储敏感信息:由于字符串在Java中是以明文形式存储的,它可能会在日志、堆转储或调试输出中泄露。 -
避免使用
String进行性能敏感的操作:例如,不要在大量数据上使用String进行子串搜索,而应考虑使用专门的库,如Apache Commons Lang。 -
避免在
switch语句中使用String:虽然Java 7开始支持在switch语句中使用String,但在性能敏感的场合,使用if-else可能更高效。 -
避免使用
String类的内部知识来优化代码:例如,依赖字符串的不可变性来避免同步,这可能会导致代码难以理解和维护。
通过对这些String相关的知识点和常见的错误有深刻理解,可以在面试中表现出你对Java基础知识的掌握,同时也能提升项目开发中代码的性能和安全性。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/**
* The value is used for character storage.
*该值用于字符存储
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*
* Additionally, it is marked with {@link Stable} to trust the contents
* of the array. No other facility in JDK provides this functionality (yet).
* {@link Stable} is safe here, because value is never null.
*/
@Stable
private final byte[] value;
/**
*{@code String}类表示字符串。全部的
*Java程序中的字符串文字,如{@code“abc”},是
*实现为此类的实例。
</p>
*字符串是常量;它们的值在它们之后不能更改
*创建。字符串缓冲区支持可变字符串。
*因为String对象是不可变的,所以它们可以共享。例如
*<blockquote><pre>
*字符串str=“abc”;
*</pre></blockquote><p>
*相当于:
*<blockquote><pre>
*char-data[]={'a','b','c'};
*String str=新字符串(数据);
*</pre></blockquote><p>
*以下是一些关于如何使用字符串的更多示例:
*<blockquote><pre>
*System.out.println(“abc”);
*字符串cde=“cde”;
*System.out.println(“abc”+cde);
*字符串c=“abc”.substring(2,3);
*字符串d=cde.substring(1,2);
*</pre></blockquote>
</p>
*类{@code String}包括用于检查的方法
*序列的单个字符,用于比较字符串,用于
*搜索字符串、提取子字符串和创建
*字符串的副本,其中所有字符都被翻译为大写或
*小写。大小写映射基于Unicode标准版本
*由{@link java.lang.Character Character}类指定。
</p>
*Java语言为字符串提供了特殊支持
*串联运算符(+&),用于的转换
*其他对象转换为字符串。有关字符串的其他信息
*连接和转换,请参阅<i>The Java&trade;语言规范</i>。
*
*<p>除非另有说明,否则将{@code null}参数传递给构造函数
*或方法将导致{@link NullPointerException}
*抛出。
*
*<p>{@code String}表示UTF-16格式的字符串
*其中<em>补充字符</em>由<em>代理表示
*对</em>(请参阅unicode部分
*的{@code Character}类中的字符表示法</a>
*更多信息)。
*索引值引用{@code-char}代码单元,因此补充
*字符在{@code String}中使用两个位置。
*<p>{@code String}类提供了处理
*Unicode代码点(即字符),以及
*处理Unicode代码单元(即{@code-char}值)。
*
*<p>除非另有说明,否则用于比较字符串的方法不采用区域设置
*考虑在内。{@link java.text.Colletor}类提供了的方法
*细粒度、区域设置敏感的字符串比较。
*
*@implNote字符串串联运算符的实现留给
*Java编译器的自由裁量权,只要编译器最终符合
*到<i>Java&trade;语言规范</i>。例如,{@code javac}编译器
*可以使用{@code StringBuffer}、{@code String Builder}、{@codeStringBuffer}来实现运算符,
*或{@code java.lang.invoke.StringConcatFactory},具体取决于JDK版本。这个
*字符串转换的实现通常通过方法{@code-toString},
*由{@code-Object}定义,并由Java中的所有类继承。
*
*@作者Lee Boynton
*@作者Arthur van Hoff
*@作者Martin Buchholz
*@作者Ulf Zibis
*@参见java.lang.Object#toString()
*@参见java.lang.StringBuffer
*@参见java.lang.StringBuilder
*@参见java.nio.charset。Charset
*@自1.0起
*@jls 15.18.1字符串连接运算符+
*/
在Java中,基本数据类型(primitive types)本身是线程安全的,因为它们是不可变的(immutable)。这意味着一旦一个基本数据类型被创建,它的值就不能被改变。然而,当多个线程共享和修改同一个基本数据类型的引用时,就会出现线程安全问题。以下是Java中的基本数据类型:
- boolean - 布尔型,只有两个可能的值:true和false。
- byte - 8位的有符号整数,范围从 -128 到 127。
- short - 16位的有符号整数,范围从 -32,768 到 32,767。
- int - 32位的有符号整数,范围从 -2,147,483,648 到 2,147,483,647。
- long - 64位的有符号整数,范围从 -2^63 到 2^63-1。
- float - 32位的单精度浮点数。
- double - 64位的双精度浮点数。
- char - 16位的Unicode字符。
这些基本数据类型的变量是线程安全的,因为它们的值在赋值后不能被更改。但是,如果你有一个指向这些基本数据类型数组的引用,并且多个线程可以访问这个数组,那么这个数组就不是线程安全的,因为不同的线程可以独立修改数组的不同元素。
此外,虽然基本数据类型本身是线程安全的,但是涉及到这些类型的操作(如计算和更新)在多线程环境下可能会导致线程安全问题,特别是当多个线程尝试同时修改同一变量时。为了确保线程安全,可能需要使用同步代码块、锁、原子变量(如AtomicInteger)或其他并发控制机制。
示例:
public class ThreadSafeExample {
private int counter = 0;
public void increment() {
counter++; // 非原子操作,可能在多线程环境下导致问题
}
}
// 正确的线程安全方式使用原子类
public class AtomicExample {
private AtomicInteger counter = new AtomicInteger(0);
public void increment() {
counter.incrementAndGet(); // 原子操作,线程安全
}
}
在第一个示例中,尽管int类型本身是线程安全的,但是counter++操作不是原子的,这意味着在多线程环境下可能会遇到竞争条件。在第二个示例中,使用AtomicInteger确保了incrementAndGet()操作的原子性,从而避免了线程安全问题。
总结来说,基本数据类型本身是不可变的,因此是线程安全的,但在多线程环境中使用这些类型的变量时,仍然需要注意同步和并发控制。
@Override
@HotSpotIntrinsicCandidate
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
在Java中,String、StringBuffer和StringBuilder是三种不同的类,它们在处理字符串时有不同的用途和性能特点。以下是它们的主要区别:
String
- 不可变性:
String对象一旦创建,其值就不能被改变。这意味着任何修改操作都会产生一个新的String对象。 - 字符串常量池:字符串字面量(如
"hello")通常存储在字符串常量池中,这有助于节省内存。 - 性能:由于其不可变性,频繁修改字符串时性能较低,因为每次修改都会创建一个新对象。
- 线程安全:
String类是线程安全的,因为其状态不能被改变。
String、StringBuffer和StringBuilder
StringBuffer
- 可变性:
StringBuffer对象可以被修改,所有修改操作都是在同一对象上进行的,而不是创建新对象。 - 线程安全:
StringBuffer是线程安全的,这意味着它的方法是同步的,可以在多线程环境中使用。 - 性能:由于同步的开销,
StringBuffer在单线程环境中比StringBuilder慢。 - 使用场景:当字符串操作在多线程环境中进行,并且需要保证线程安全时,应使用
StringBuffer。
StringBuilder
- 可变性:与
StringBuffer类似,StringBuilder对象也可以被修改。 - 线程不安全:
StringBuilder不是线程安全的,它的方法是无同步的,因此在单线程环境中性能更优。 - 性能:由于没有同步的开销,
StringBuilder在单线程环境中的性能优于StringBuffer。 - 使用场景:当字符串操作在单线程环境中进行,并且不需要考虑线程安全时,应使用
StringBuilder。
性能对比
- 对于单线程操作,
StringBuilder通常是最佳选择,因为它提供了最好的性能。 - 对于多线程操作,如果需要确保线程安全,可以使用
StringBuffer。
示例代码
String str1 = "Hello";
String str2 = str1 + " World"; // 创建了一个新的String对象
StringBuffer sb = new StringBuffer("Hello");
sb.append(" World"); // 在原有对象上修改
StringBuilder sbd = new StringBuilder("Hello");
sbd.append(" World"); // 在原有对象上修改
在这个例子中,使用String进行字符串连接时,每次连接操作都会产生一个新的String对象。而StringBuffer和StringBuilder则允许在原有对象上进行修改,避免了创建多个对象的开销。
结论
选择使用String、StringBuffer还是StringBuilder取决于具体的应用场景:
- 使用
String,当你需要一个不可变的字符串对象,并且不会频繁修改字符串内容时。 - 使用
StringBuffer,当你需要在多线程环境中进行字符串操作,并且要求线程安全时。 - 使用
StringBuilder,当你在单线程环境中进行字符串操作,并且追求性能时。
/**
* Returns a canonical representation for the string object. 返回字符串对象的规范表示形式。
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class {@code String}.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
* It follows that for any two strings {@code s} and {@code t},
* {@code s.intern() == t.intern()} is {@code true}
* if and only if {@code s.equals(t)} is {@code true}.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
* @jls 3.10.5 String Literals
*/
public native String intern();
在Java中,String.intern()方法是一个非常重要的特性,它与字符串常量池(String Pool)紧密相关。以下是关于String.intern()方法的详细知识点:
字符串常量池
字符串常量池是Java虚拟机(JVM)用来存储字符串常量和通过String.intern()方法产生的字符串的内存区域。其主要目的是为了节省内存空间,避免相同的字符串字面量被多次创建。
String.intern()方法
String.intern()方法的作用是将一个字符串对象与字符串常量池中的字符串对象进行比较。如果常量池中已经包含了该字符串,则返回常量池中的字符串对象的引用;如果没有,则将该字符串对象添加到常量池中,并返回这个新字符串对象的引用。
方法签名
public native String intern()
intern()方法是String类的成员方法,它是一个本地方法,用native关键字标识,这意味着其底层实现是用C/C++或其他非Java语言编写的。
用途
- 优化字符串的使用:通过重用常量池中的字符串,减少内存占用。
- 安全性:在某些情况下,可以避免字符串被篡改。
- 性能:对于频繁访问的字符串,使用
intern()可以提高性能,因为可以直接从常量池中获取字符串引用。
注意事项
- 字符串常量自动进入常量池:通过字符串字面量(如
"hello")创建的字符串,在编译时会自动放入字符串常量池中。 - 字符串变量不会自动进入常量池:通过
new String("hello")创建的字符串,不会自动放入常量池,除非显式调用intern()方法。 intern()方法开销:如果字符串常量池中没有对应的字符串,intern()方法会将字符串添加到常量池,这可能涉及一些性能开销。- 滥用
intern()可能导致内存溢出:如果无限制地使用intern()方法,可能会导致常量池占用大量内存,甚至内存溢出。
示例
String s1 = "hello";
String s2 = new String("hello");
String s3 = s2.intern();
System.out.println(s1 == s2); // 输出 false
System.out.println(s1 == s3); // 输出 true,因为 s3 调用 intern() 后,引用了常量池中的 "hello"
在这个示例中,s1直接通过字符串字面量创建,自动存储在字符串常量池中。s2通过new String()创建,不会自动存储在常量池中。s3通过调用s2.intern()后,引用了常量池中的字符串对象。
String.intern()方法是一个非常有用的特性,可以帮助优化字符串的使用。然而,开发者应当谨慎使用,避免滥用导致内存问题。在某些特定场景下,如处理大量相似字符串时,合理使用intern()可以带来性能上的提升。
在不同的JVM实现中,字符串常量池的存储位置可能有所不同,但以Oracle HotSpot JVM为例,其发展过程中经历了几次变化:
-
永久代(PermGen):在Java 8及之前的版本中,字符串常量池被存储在永久代(PermGen)中。永久代是JVM内存的一部分,用于存储类元数据、静态变量以及其他只读数据。
-
方法区(Metaspace):从Java 8开始,永久代被废弃,取而代之的是元空间(Metaspace)。字符串常量池被移动到了称为方法区的内存区域。方法区用于存储类的信息、静态变量和常量池等。元空间代替了永久代,避免了永久代的内存溢出问题,因为它使用的是本地内存(Native Memory),而不是虚拟机内存(Heap Memory)。
-
堆区:字符串对象本身(即通过
new String()创建的对象)是存储在Java堆(Heap)中的。堆是JVM用来分配和管理对象内存的区域。
字符串常量池的变迁:
- Java <= 7: 字符串常量池位于永久代(PermGen)。
- Java 8: 字符串常量池被移动到了方法区,并且PermGen被元空间(Metaspace)所取代。
- Java 11: 永久代被彻底移除,元空间成为存储类元数据的唯一区域。
实际影响:
- 内存管理:由于元空间使用的是本地内存,因此不受JVM堆大小的限制,这有助于减少内存溢出的风险。
- 性能调优:了解字符串常量池的位置对于JVM性能调优很重要。例如,字符串常量池的溢出可能导致Full GC,而元空间的大小也需要适当调整以避免OOM(内存溢出)错误。
示例代码:
String str1 = "Hello";
String str2 = "Hello";
String str3 = new String("Hello");
在这个例子中:
str1和str2引用的是字符串常量池中的同一个对象。str3是一个通过new操作符创建的新对象,它位于Java堆中。
HotSpot是Java虚拟机(JVM)的一种流行实现,广泛用于运行Java应用程序。它由Sun Microsystems(现在是Oracle Corporation的一部分)开发,并作为Oracle JDK和OpenJDK的一部分进行分发。HotSpot VM以其性能优化技术而闻名,包括即时编译(JIT)编译器、垃圾回收和逃逸分析。
HotSpot VM使用多种先进技术为Java应用程序提供高性能,包括:
-
内存模型:HotSpot提供了一个先进的内存模型,用于管理对象和类的生命周期。
-
垃圾回收器:它包含了多种垃圾回收器,比如Serial、Parallel、Concurrent Mark Sweep (CMS)、G1等,这些回收器针对不同的应用场景和性能要求进行了优化。
-
即时编译器:HotSpot拥有高效的JIT编译器,能够将字节码即时编译成本地机器代码,提高程序的运行速度。
-
自适应优化器:它能够根据程序运行时的行为动态地进行优化。
-
跨平台支持:HotSpot VM支持JVM规范,能够在多种操作系统上运行,实现“一次编译,到处运行”的特性。
-
可插拔的组件:HotSpot允许开发者根据需要选择不同的JIT编译器和垃圾收集器。
-
性能监控和管理:提供了多种工具和API来监控和管理虚拟机的性能。
HotSpot VM自1997年推出以来一直是Java开发者的首选,并且随着Java语言的发展不断进化和改进。
在HotSpot JVM中,字符串常量池的位置从永久代变为了方法区,并且与元空间相关联。了解这些变化有助于更好地理解JVM的内存管理机制,并对性能调优和故障排查提供帮助。
Java性能优化秘籍:JIT编译、垃圾回收与逃逸分析深度解析
Java语言之所以能够在性能要求极高的应用场景中占据一席之地,JVM的即时编译(JIT)编译器、垃圾回收机制和逃逸分析技术功不可没。本文将深入探讨这三项技术,揭示它们是如何在幕后优化Java程序性能的。
JIT编译器:Java代码的加速器
Java代码首先被编译为字节码,再由JVM执行。JIT编译器的作用是在运行时将热点代码(经常执行的代码)编译为本地机器码,从而提高执行效率。
JIT编译器的工作流程
- 解释执行:JVM首先解释执行字节码,这是一个轻量级的过程。
- 热点代码探测:JVM监控字节码的执行频率,识别出热点代码。
- 编译优化:JIT编译器将热点代码编译为机器码,并进行多种优化。
JIT编译器的类型
- Client Compiler:适用于客户端应用,优化编译时间。
- Server Compiler:适用于服务器应用,优化代码执行效率。
垃圾回收:JVM的内存清洁工
Java的垃圾回收机制负责自动管理内存,回收不再使用的对象,避免了内存泄漏和野指针问题。
垃圾回收的基础
- 对象引用:通过引用链来跟踪对象是否可访问。
- 标记-清除:标记所有不再使用的对象,然后清除。
- 分代收集:新生代和老年代使用不同的垃圾回收策略。
垃圾回收器
- Serial GC:单线程的垃圾回收器,适合小数据量。
- Parallel GC:多线程的垃圾回收器,提高垃圾回收效率。
- CMS:以最小化停顿时间为目标的垃圾回收器。
逃逸分析:JVM的性能优化术
逃逸分析是JVM的一项优化技术,用于确定对象的作用域是否逃逸到方法外部。
逃逸分析的作用
- 栈上分配:如果对象不会逃逸到方法外部,可以分配到栈上,减少垃圾回收的开销。
- 同步省略:如果对象不会逃逸,可以省略同步锁。
- 标量替换:将对象拆解为多个原始类型变量,提高性能。
实际案例演示
以下是一个简单的Java程序示例,展示了一个热点方法,该方法可能会被JIT编译器优化。
public class HotspotExample {
public static void main(String[] args) {
int result = 0;
for (int i = 0; i < 10000000; i++) {
result += i;
}
System.out.println(result);
}
}
在这个例子中,由于循环执行了足够多次,JIT编译器很可能会将循环体编译为优化的机器码。
JIT编译器、垃圾回收和逃逸分析是Java虚拟机优化程序性能的三大法宝。理解它们的原理和工作方式,对于编写高效的Java程序至关重要。希望本文能够为你打开Java性能优化的大门。
HTTP状态码415表示“Unsupported Media Type”,即服务器无法处理请求附带的媒体格式。这个错误通常发生在客户端发送的请求中包含了一个服务器无法识别或不支持的Content-Type头部。以下是一些可能导致HTTP 415错误的原因:
-
请求头中的
Content-Type不正确:如果客户端发送的请求中Content-Type头部设置为服务器不支持的类型,比如application/xml而服务器期望的是application/json,就会导致415错误。 -
请求体格式不正确:即使
Content-Type设置正确,如果请求体中的数据格式与服务器期望的格式不匹配,比如JSON数据格式错误,也会导致415错误。 -
服务器端处理问题:服务器端的代码可能没有正确处理请求体中的数据,或者没有正确地设置
Content-Type响应头。 -
客户端代码错误:客户端在发送请求时可能没有正确设置
Content-Type,或者在发送请求体之前没有正确地序列化数据。
为了解决这个问题,你可以采取以下步骤:
-
检查请求头:确保客户端发送的请求头中的
Content-Type与服务器期望的类型相匹配。 -
检查请求体:确保请求体中的数据格式正确,如果是JSON,确保它是一个有效的JSON对象。
-
服务器端调试:检查服务器端的日志,查看是否有任何异常或错误信息,这可能会提供为什么服务器无法处理请求的原因。
-
客户端调试:使用浏览器的开发者工具或网络监控工具来检查请求和响应的详细信息,这可以帮助你确定问题所在。
-
与服务器端沟通:如果问题仍然无法解决,可能需要与服务器端的开发人员沟通,了解服务器端的期望和配置。
在参考资料中,有提到在前后端联调时遇到HTTP 415错误的情况,并提供了两种解决方案:后端修改和前端修改❸❺。后端修改指的是去掉@RequestBody注解,前端修改指的是修改请求时的请求头里Content-Type类型为application/json❸❺。
Java参数传递
在Java编程中,参数传递是方法调用的核心机制,它决定了如何将数据传递给方法以及方法如何接收和处理这些数据。深入理解参数传递,对于编写高效、安全和可维护的代码至关重要。本文将带你走进Java参数传递的世界,探索其背后的机制和最佳实践。
参数传递的基本概念
在Java中,方法的参数传递主要有两种形式:值传递和引用传递。
值传递(Pass by Value)
- 基本数据类型:当向方法传递基本数据类型(如int、float、char等)时,实际上是在传递这些值的副本。
- 示例:
public class PassByValueExample {
public static void main(String[] args) {
int num = 10;
swap(num);
System.out.println(num); // 输出依然是 10
}
static void swap(int n) {
n = 20;
}
}
引用传递(Pass by Reference)
- 对象数据类型:对于对象或数组(即引用数据类型),传递的是引用的副本,但副本和原引用都指向同一个对象。
- 示例:
public class PassByReferenceExample {
public static void main(String[] args) {
int[] array = {1, 2, 3};
modifyArray(array);
System.out.println(Arrays.toString(array)); // 输出 [4, 2, 3],数组被修改
}
static void modifyArray(int[] arr) {
arr[0] = 4;
}
}
参数传递的深入分析
自动装箱与拆箱
Java 5引入了自动装箱和拆箱特性,这在参数传递时尤其有用。
public class AutoboxingExample {
public static void main(String[] args) {
Integer integer = 100;
increment(integer);
System.out.println(integer); // 输出 101
}
static void increment(Integer n) {
n = n + 1;
}
}
参数的评估时机
参数的评估是在方法调用之前完成的,这意味着参数表达式在方法调用之前就被求值了。
public class ArgumentEvaluationExample {
public static void main(String[] args) {
int counter = 0;
performActions(incrementCounter(), counter);
}
static int incrementCounter() {
return ++counter;
}
static void performActions(int a, int b) {
// ...
}
}
在这个例子中,counter在方法调用之前被增加了两次,因为参数评估的顺序是未定义的。
参数传递与方法调用的实际应用
可变参数(Varargs)
Java允许方法接受可变数量的参数,这在实践中非常有用。
public class VarargsExample {
public static void printArgs(Object... args) {
for (Object obj : args) {
System.out.println(obj);
}
}
public static void main(String[] args) {
printArgs("Hello", 123, 45.67);
}
}
方法重载与参数传递
方法重载时,参数的类型和数量是区分不同方法的关键。
public class MethodOverloadingExample {
int add(int a, int b) {
return a + b;
}
int add(int a, int b, int c) {
return a + b + c;
}
public static void main(String[] args) {
// 调用不同的add方法
}
}
参数传递是Java程序设计中的基础概念,它直接关系到程序的性能和行为。理解值传递和引用传递的区别,掌握自动装箱、拆箱、可变参数和方法重载等高级特性,对于成为一名优秀的Java开发者至关重要。
Java浮点数之争:float与double的精度对决
引言
在Java编程语言中,浮点数的运用无处不在,无论是在科学计算、图形渲染还是金融分析等领域,float和double类型都扮演着重要角色。然而,两者在精度和使用场景上存在差异,理解这些差异对于编写高效且准确的程序至关重要。本文将深入探讨float与double的精度特性、使用场景以及最佳实践。
浮点数的表示
浮点数是基于IEEE 754标准的二进制浮点数算术标准,它定义了浮点数的存储方式和操作规则。
float:单精度浮点数
- 位数:32位
- 指数位:8位
- 尾数位:23位
- 表示范围:大约±1.4E-45 到 ±3.4E38
double:双精度浮点数
- 位数:64位
- 指数位:11位
- 尾数位:52位
- 表示范围:大约±4.9E-324 到 ±1.8E308
精度比较
由于double比float有更多的尾数位,因此double的精度更高,能表示更大的数值范围,也能更精确地表示小数。
示例代码
public class FloatVsDouble {
public static void main(String[] args) {
float f = 1.123456789f;
double d = 1.123456789d;
System.out.println("Float: " + f); // 输出 Float: 1.1234568
System.out.println("Double: " + d); // 输出 Double: 1.123456789
}
}
在这个示例中,由于float的精度限制,小数点后的某些数字被舍入了。
使用场景
float
- 资源受限的环境:当内存和存储非常宝贵时,如嵌入式系统或移动设备。
- 图形渲染:在图形学中,使用
float可以节省内存,并且人眼对于精度的细微差别不敏感。
double
- 科学计算:需要高精度的场合,如物理模拟、数据分析。
- 金融应用:财务计算中,精度至关重要,通常会使用
double。
性能考量
在某些旧的硬件平台上,float运算可能比double运算更快,因为float的操作更简单。但在现代处理器上,两者的性能差异不大。
注意事项
- 避免魔法数字:不要在代码中直接使用浮点数作为常量,因为这会导致不必要的精度损失。如果需要,使用
BigDecimal。 - 注意溢出:浮点数在接近其表示范围的极限时可能会溢出。
- 舍入误差:浮点数运算可能会导致舍入误差,这在比较浮点数时需要特别注意。
Java中字段绝对不能是公有的为什么?
在Java编程中,封装是面向对象编程的一个核心原则。封装意味着将对象的内部状态和行为隐藏起来,只通过公共接口暴露给外部世界。然而,在实际开发中,我们经常看到一些类的字段被声明为公有的(public)。这似乎违反了封装的原则,那么为什么字段绝对不能是公有的呢?本文将探讨这个问题,并提供一些最佳实践。
封装的重要性
封装是面向对象编程的四大原则之一,它有以下几个关键点:
-
隐藏实现细节:封装允许开发者隐藏对象的内部实现细节,只暴露必要的接口给外部使用。
-
降低复杂性:通过封装,可以将复杂的实现细节隐藏起来,使得外部调用者不需要关心这些细节,从而简化了使用。
-
提高可维护性:封装可以防止外部代码直接访问和修改对象的内部状态,这样在修改内部实现时,可以减少对其他代码的影响。
-
增强安全性:封装可以防止外部代码直接访问敏感数据,从而提高程序的安全性。
公有字段的问题
尽管公有字段可以简化访问,但它们也带来了一系列的问题:
-
破坏封装性:公有字段直接暴露了对象的内部状态,这违反了封装的原则。
-
增加耦合性:公有字段使得类与使用它的代码之间产生了不必要的耦合,这使得代码更难维护和重用。
-
难以控制访问:公有字段没有访问控制,任何代码都可以直接修改它们,这可能导致数据不一致或错误。
-
缺乏灵活性:如果未来需要修改字段的实现,由于公有字段的直接访问,可能会导致大量代码需要修改。
最佳实践
为了保持封装性,我们应该遵循以下最佳实践:
-
使用私有字段:将所有字段声明为私有(private),这样可以确保它们的封装性。
-
提供公共访问器:通过公共的getter和setter方法来访问和修改私有字段。这样可以在访问和修改字段时添加额外的逻辑,比如验证、日志记录等。
-
使用final和static修饰符:如果字段是常量或静态的,使用final和static修饰符可以提高代码的清晰度和性能。
-
使用注解:使用
@Getter和@Setter等Lombok注解,可以自动生成getter和setter方法,减少样板代码。
虽然公有字段在某些情况下可能看起来很方便,但从长远来看,它们破坏了封装性,增加了代码的耦合性和维护难度。因此,作为高级Java架构师,我们应该坚持使用私有字段,并通过公共访问器来提供对这些字段的访问。这样不仅可以保持代码的整洁和可维护性,还可以为未来可能的变更提供灵活性。记住,封装是面向对象编程的基石,我们应该始终致力于维护和强化这一原则。
抽象类与接口的终极对决**
引言
在Java的面向对象世界里,抽象类和接口是构建灵活、可扩展架构的基石。它们为实现代码复用、解耦和多态性提供了强大的支持。然而,抽象类和接口在概念和用法上有着明显的区别,同时也存在一定的联系。本文将深入探讨抽象类与接口之间的差异、联系以及如何根据项目需求做出恰当选择。
抽象类:部分实现的蓝图
抽象类是一种不能被直接实例化的类。它通常作为其他类的基类存在,提供一些共同的属性和方法实现,同时保留一些抽象方法供子类实现。
特点
- 包含抽象方法:没有方法体,子类必须重写这些方法。
- 包含具体方法:可以有完整的方法实现。
- 单继承:Java中单继承的约束意味着一个类只能继承一个抽象类。
示例代码
public abstract class Animal {
public void eat() {
System.out.println("Eating");
}
public abstract void sound();
}
class Dog extends Animal {
public void sound() {
System.out.println("Woof");
}
}
接口:定义行为的契约
接口是一种完全抽象的概念,它不提供任何实现,只定义了一组方法的签名。
特点
- 不包含实现:所有方法默认是抽象的。
- 多实现:一个类可以实现多个接口。
- 默认方法:Java 8开始,接口可以包含默认方法实现。
- 静态方法:Java 8开始,接口可以包含静态方法。
示例代码
public interface UsbDevice {
void connect();
void disconnect();
default void status() {
System.out.println("Device status is OK");
}
}
class Smartphone implements UsbDevice {
public void connect() {
System.out.println("Connecting to USB");
}
public void disconnect() {
System.out.println("Disconnecting from USB");
}
}
抽象类与接口的区别
- 设计目的:抽象类常用于共享代码,接口用于定义能力。
- 继承与实现:类是继承抽象类的,而接口是要被实现的。
- 数量限制:一个类只能继承一个抽象类,但可以实现多个接口。
- 方法实现:抽象类可以有方法实现,接口不能(Java 8前)。
- 访问修饰符:接口中的方法默认是
public,抽象类中的方法可以有多种访问修饰符。
抽象类与接口的联系
- 都用于多态:允许不同的类对同一消息做出响应。
- 都不能被实例化:必须通过子类或实现类来使用。
- 都包含抽象方法:虽然Java 8后接口可以有默认实现,但仍有抽象方法。
设计选择的考量
- 当关注行为而非状态:选择接口。
- 需要共享代码:选择抽象类。
- 需要固定行为的类层次:选择抽象类。
- 需要实现多个行为集合:选择接口。
抽象类和接口是Java面向对象设计中不可或缺的部分。它们各自有着独特的用途和优势,理解它们的区别和联系对于设计灵活、可维护的系统至关重要。
Java中super知识点梳理
在Java中,super关键字是一个非常重要的概念,它用于引用当前对象的父类对象。super关键字在继承和多态的上下文中扮演着关键角色。本文将详细梳理super关键字的使用场景和相关知识点。
1. 引用父类的成员
在子类中,如果需要引用父类的成员(包括方法、变量和构造器),可以使用super关键字。
1.1 引用父类的变量
class Parent {
int value = 10;
}
class Child extends Parent {
void display() {
System.out.println(super.value); // 输出父类的变量值
}
}
1.2 引用父类的方法
class Parent {
void display() {
System.out.println("Parent display()");
}
}
class Child extends Parent {
void display() {
super.display(); // 调用父类的方法
System.out.println("Child display()");
}
}
2. 调用父类的构造器
在子类的构造器中,可以使用super关键字调用父类的构造器。
class Parent {
Parent() {
System.out.println("Parent Constructor");
}
}
class Child extends Parent {
Child() {
super(); // 调用父类的构造器
System.out.println("Child Constructor");
}
}
3. 调用父类的重写方法
在子类中重写父类的方法时,如果需要在子类的方法中调用父类的实现,可以使用super关键字。
class Parent {
void display() {
System.out.println("Parent display()");
}
}
class Child extends Parent {
void display() {
super.display(); // 调用父类的display()方法
System.out.println("Child display()");
}
}
4. 解决变量隐藏问题
当子类的成员变量与父类的成员变量同名时,子类的变量会隐藏父类的变量。此时,如果需要访问父类的同名变量,可以使用super关键字。
class Parent {
int value = 10;
}
class Child extends Parent {
int value = 20;
void display() {
System.out.println(super.value); // 输出父类的value值
}
}
5. super与this的区别
super关键字用于引用父类的成员,而this关键字用于引用当前对象的成员。在构造器中,this用于调用当前类的其他构造器,而super用于调用父类的构造器。
class Parent {
Parent() {
System.out.println("Parent Constructor");
}
}
class Child extends Parent {
Child() {
this(10); // 调用当前类的另一个构造器
System.out.println("Child Constructor");
}
Child(int value) {
super(); // 调用父类的构造器
System.out.println("Child Constructor with value: " + value);
}
}
6. super的使用场景
- 当子类需要访问父类的成员时。
- 当子类需要调用父类的构造器时。
- 当子类需要调用父类的重写方法时。
- 当子类的成员变量与父类的成员变量同名时。
super关键字在Java中是一个非常重要的概念,它提供了对父类成员的直接访问。正确使用super关键字可以帮助我们编写出更加清晰、可维护的代码。作为高级Java架构师,我们应该深入理解super的使用场景和最佳实践,以便在实际开发中更加有效地利用这一特性。
在Java中,super关键字在多态的上下文中通常用于调用父类的方法实现,即使子类重写了这些方法。这在多态的情况下特别有用,因为子类可以提供自己的方法实现,而super关键字允许子类在需要时调用父类的方法。
多态与方法重写
在Java中,多态是通过继承和方法重写实现的。当一个子类继承自一个父类时,它可以重写父类的方法,提供自己的实现。然而,在某些情况下,子类可能需要在自己的方法实现中调用父类的方法,以保留或增强父类的行为。
使用super调用父类方法
在子类的方法中,可以通过super关键字调用父类的方法。这通常在子类需要在自己的实现中使用父类方法的行为时使用。
class Animal {
public void makeSound() {
System.out.println("Some sound");
}
}
class Dog extends Animal {
@Override
public void makeSound() {
super.makeSound(); // 调用父类的makeSound方法
System.out.println("Bark");
}
}
public class Main {
public static void main(String[] args) {
Dog myDog = new Dog();
myDog.makeSound(); // 输出: Some sound Bark
}
}
在上面的例子中,Dog类重写了Animal类的makeSound方法。在Dog类的makeSound方法中,首先调用了super.makeSound()来执行父类的makeSound方法,然后添加了自己的行为。
super与构造器
在构造器中,super关键字用于调用父类的构造器。这是因为在创建子类对象时,必须先初始化父类的部分。如果子类的构造器没有显式地调用父类的构造器,Java编译器会自动插入对无参构造器的调用。如果父类没有无参构造器,子类必须在构造器中使用super来调用父类的构造器。
class Animal {
public Animal() {
System.out.println("Animal is created");
}
}
class Dog extends Animal {
public Dog() {
super(); // 调用父类的构造器
System.out.println("Dog is created");
}
}
public class Main {
public static void main(String[] args) {
Dog myDog = new Dog();
// 输出: Animal is created
// 输出: Dog is created
}
}
在这个例子中,Dog类的构造器使用super()调用了Animal类的构造器。
super关键字在多态中用于调用父类的方法和构造器。它允许子类在自己的方法实现中保留或增强父类的行为。正确使用super是实现多态和维护代码清晰性的重要部分。在设计类和方法时,应该考虑到何时使用super来调用父类的实现,以确保代码的灵活性和可维护性。
Java中的“重写”与“重载”:双胞胎兄弟的魔法对决!
在Java的世界里,有两个非常相似却又截然不同的概念——重写(Override)和重载(Overload)。它们就像是双胞胎兄弟,名字相近,但性格迥异。今天,就让我们一起揭开它们的神秘面纱,看看它们是如何在Java的魔法世界中施展它们的魔法的。
重写(Override):继承的魔法
重写,也被称为方法覆盖,是面向对象编程中一个非常重要的概念。它允许子类提供一个特定于自己的实现,来替换父类中的方法。这就像是一场魔法对决,子类通过重写父类的方法,展示出自己独特的魔法。
class Animal {
public void makeSound() {
System.out.println("Some sound");
}
}
class Dog extends Animal {
@Override
public void makeSound() {
System.out.println("Bark");
}
}
public class Main {
public static void main(String[] args) {
Dog myDog = new Dog();
myDog.makeSound(); // 输出: Bark
}
}
在这个例子中,Dog类重写了Animal类的makeSound方法,当创建Dog对象并调用makeSound方法时,会执行Dog类中的实现,而不是Animal类中的实现。
重载(Overload):多态的盛宴
重载,又称为方法重载,是指在同一个类中可以有多个同名方法,只要它们的参数列表不同即可。这就像是一场盛宴,同一个菜肴可以根据不同的食材和烹饪方法,呈现出不同的风味。
class Calculator {
public int add(int a, int b) {
return a + b;
}
public double add(double a, double b) {
return a + b;
}
public int add(int a, int b, int c) {
return a + b + c;
}
}
public class Main {
public static void main(String[] args) {
Calculator calc = new Calculator();
System.out.println(calc.add(1, 2)); // 输出: 3
System.out.println(calc.add(1.5, 2.5)); // 输出: 4.0
System.out.println(calc.add(1, 2, 3)); // 输出: 6
}
}
在这个例子中,Calculator类有三个add方法,它们的参数列表不同,因此可以共存。当调用add方法时,编译器会根据传入的参数类型和数量来决定调用哪个方法。
重写与重载的区别
虽然重写和重载都涉及到方法的名称,但它们的本质是不同的:
- 重写:发生在继承关系中,子类重写父类的方法,方法名、参数列表和返回类型必须相同。
- 重载:发生在同一个类中,方法名相同,但参数列表不同,返回类型可以不同。
当然可以。重写(Override)和重载(Overload)是Java中两个非常重要的概念,它们在不同的场景下有不同的应用。下面我将通过具体的例子来说明它们的使用场景。
重写(Override)的使用场景
重写通常用于实现多态性,即子类可以提供特定于自己的实现来替换父类中的方法。这在继承关系中非常常见,尤其是在设计框架和库时。
场景一:框架设计
假设我们正在设计一个图形用户界面(GUI)框架,其中有一个Button类,它有一个draw方法用于绘制按钮。现在我们想要创建一个ImageButton类,它继承自Button类,并重写draw方法来绘制一个带有图片的按钮。
class Button {
public void draw() {
System.out.println("Drawing a simple button.");
}
}
class ImageButton extends Button {
@Override
public void draw() {
System.out.println("Drawing an image button with an image.");
}
}
public class Main {
public static void main(String[] args) {
Button button = new Button();
ImageButton imageButton = new ImageButton();
button.draw(); // 输出: Drawing a simple button.
imageButton.draw(); // 输出: Drawing an image button with an image.
}
}
在这个例子中,ImageButton类重写了Button类的draw方法,以提供特定的实现。
场景二:库扩展
在使用第三方库时,我们可能需要扩展库中的类的功能。重写允许我们这样做,而不会破坏库的现有功能。
class LibraryClass {
public void performAction() {
System.out.println("Performing a default action.");
}
}
class ExtendedClass extends LibraryClass {
@Override
public void performAction() {
System.out.println("Performing an extended action.");
}
}
public class Main {
public static void main(String[] args) {
LibraryClass libraryInstance = new LibraryClass();
ExtendedClass extendedInstance = new ExtendedClass();
libraryInstance.performAction(); // 输出: Performing a default action.
extendedInstance.performAction(); // 输出: Performing an extended action.
}
}
在这个例子中,ExtendedClass重写了LibraryClass的performAction方法,以提供额外的功能。
重载(Overload)的使用场景
重载允许我们在同一个类中创建多个同名方法,只要它们的参数列表不同。这在提供灵活性和方便性方面非常有用。
场景一:方法的多种用途
假设我们有一个calculate方法,它可以根据不同的参数执行不同的计算。
class Calculator {
public int calculate(int a, int b) {
return a + b;
}
public double calculate(double a, double b) {
return a + b;
}
public int calculate(int a, int b, int c) {
return a + b + c;
}
}
public class Main {
public static void main(String[] args) {
Calculator calculator = new Calculator();
System.out.println(calculator.calculate(1, 2)); // 输出: 3
System.out.println(calculator.calculate(1.5, 2.5)); // 输出: 4.0
System.out.println(calculator.calculate(1, 2, 3)); // 输出: 6
}
}
在这个例子中,calculate方法被重载了三次,以适应不同的参数类型和数量。
场景二:构造器重载
构造器重载允许我们根据不同的参数列表创建对象。
class Person {
private String name;
private int age;
public Person(String name) {
this.name = name;
this.age = 0;
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
public class Main {
public static void main(String[] args) {
Person person1 = new Person("Alice");
Person person2 = new Person("Bob", 30);
}
}
在这个例子中,Person类有两个构造器,一个接受一个参数,另一个接受两个参数。这允许我们根据需要创建Person对象。
在Java中,@HotSpotIntrinsicCandidate注解是JDK源码中使用的一个特殊注解,它与HotSpot虚拟机的内部优化机制有关。这个注解的作用是指示HotSpot虚拟机中的某些方法可能会被优化为特定于CPU的指令,从而提高性能。
具体来说,当一个方法被标记为@HotSpotIntrinsicCandidate时,它表明该方法可能会有一个高效的实现,这个实现是基于特定CPU指令集的。在运行时,HotSpot虚拟机会尝试使用这些高效的实现来替换标准的Java方法调用,以减少方法调用的开销并提高执行效率。
例如,String类中的indexOf方法就是一个被标记为@HotSpotIntrinsicCandidate的方法。当调用String.indexOf方法时,如果传入的字符串只包含Latin1字符,HotSpot虚拟机可能会使用一个特定于CPU的实现来执行这个方法,而不是使用Java字节码解释器来执行。
需要注意的是,虽然方法被标记为@HotSpotIntrinsicCandidate,但这并不意味着在所有情况下都会使用这种优化。实际上,这种优化是否发生取决于多种因素,包括JVM的版本、运行时的配置以及具体的硬件平台等。此外,即使方法被标记为@HotSpotIntrinsicCandidate,在解释器级别(Interpreter)也不会有这种优化。
总结来说,@HotSpotIntrinsicCandidate注解是Java中用于指示方法可能被HotSpot虚拟机优化的一个标记,它有助于提高特定方法的执行效率,但这种优化是否实际发生还需要考虑具体的运行时环境和条件❷❸❹。
在Java中,标记为@IntrinsicCandidate的方法通常是指那些在HotSpot虚拟机中可能被优化为特定于CPU的指令的方法。这些方法通常是一些非常基础且频繁被调用的操作,如基本类型的算术运算、数组操作等。通过将这些方法标记为@IntrinsicCandidate,HotSpot虚拟机可以在运行时根据具体的硬件平台和JVM配置,选择是否使用特定的优化实现来替换标准的Java方法调用。
以下是一些常见的被标记为@IntrinsicCandidate的方法:
-
基本类型的算术运算:如
int和long类型的加法、减法、乘法和除法等。 -
数组操作:如
System.arraycopy()方法,它用于高效地复制数组。 -
字符串操作:如
String类中的charAt()、length()等方法。 -
数学运算:如
Math类中的sin()、cos()、sqrt()等方法。 -
对象操作:如
Object类中的hashCode()、equals()等方法。
需要注意的是,虽然方法被标记为@IntrinsicCandidate,但这并不意味着在所有情况下都会使用这种优化。实际上,这种优化是否发生取决于多种因素,包括JVM的版本、运行时的配置以及具体的硬件平台等。此外,即使方法被标记为@IntrinsicCandidate,在解释器级别(Interpreter)也不会有这种优化。
总结来说,@IntrinsicCandidate注解是Java中用于指示方法可能被HotSpot虚拟机优化的一个标记,它有助于提高特定方法的执行效率,但这种优化是否实际发生还需要考虑具体的运行时环境和条件➊❷❸❹❺❻。
在Java中,查看哪些方法被优化通常需要使用特定的工具和方法。由于Java的即时编译器(JIT)在运行时对热点代码进行优化,因此在运行时查看哪些方法被优化是比较困难的。不过,有一些工具和方法可以帮助我们了解哪些方法可能被优化了:
-
使用JVM参数:
你可以通过设置JVM参数来获取JIT编译器的编译信息。例如,使用-XX:+PrintCompilation参数可以在JVM运行时打印出编译的方法信息。 -
使用JITWatch:
JITWatch是一个可视化的工具,可以帮助你分析JVM的即时编译行为。它通过分析JVM的编译日志文件(通常由-XX:+PrintCompilation参数生成),提供了一个图形界面来查看哪些方法被编译了,以及编译的类型和原因。 -
使用JFR(Java Flight Recorder):
Java Flight Recorder是JDK提供的一个性能分析工具,它可以记录JVM运行时的详细信息。通过分析JFR记录的数据,你可以了解哪些方法被编译,以及编译的性能数据。 -
使用JMC(Java Mission Control):
Java Mission Control是与JFR配合使用的工具,它提供了一个图形界面来分析JFR记录的数据。你可以使用JMC来查看哪些方法被编译,以及编译的性能数据。 -
使用JIT编译器的调试选项:
一些JIT编译器提供了调试选项,允许你查看编译的方法和编译的详细信息。例如,使用-XX:+PrintInlining参数可以打印出方法内联的信息。 -
使用JIT编译器的分析工具:
一些JIT编译器提供了专门的分析工具,如HotSpot的hsdis工具,它可以提供反汇编的代码,帮助你了解编译后的代码。
请注意,这些工具和方法可能需要一定的专业知识来理解和分析输出的数据。如果你不熟悉这些工具,可能需要查阅相关的文档或寻求专业人士的帮助。
由于这些工具和方法可能会随着JVM版本的更新而发生变化,建议查阅你所使用的JVM版本的官方文档,以获取最新的信息和使用指南。
Java中的Object
在Java中,Object类位于类继承层次结构的顶端,所有的类默认继承java.lang.Object类。Object类提供了一些通用的方法,这些方法为所有对象提供了基本的操作。以下是Object类的一些主要方法:
-
protected Object clone()- 创建并返回该对象的一个副本。默认实现抛出CloneNotSupportedException。 -
boolean equals(Object obj)- 指示其他对象是否与此对象相等。通常用于比较对象的内容。 -
protected void finalize()- 当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。用于在对象被回收前进行清理。 -
Class<?> getClass()- 返回此对象的运行时类。 -
int hashCode()- 返回该对象的哈希码值。通常与equals()方法配合使用,以保证相等的对象有相同的哈希码。 -
void notify()- 唤醒在此对象监视器上等待的单个线程。 -
void notifyAll()- 唤醒在此对象监视器上等待的所有线程。 -
String toString()- 返回该对象的字符串表示。 -
void wait()- 导致当前线程等待,直到另一个线程调用此对象的notify()或notifyAll()方法。 -
void wait(long timeout)- 导致当前线程等待,直到另一个线程调用此对象的notify()或notifyAll()方法,或者超过指定的超时时间。 -
void wait(long timeout, int nanos)- 导致当前线程等待,直到另一个线程调用此对象的notify()或notifyAll()方法,或者超过指定的超时时间,或者超过nanos额外的纳秒。
这些方法被提供的原因如下:
- 通用性:为所有对象提供一组基本操作,无需重复实现。
- 多态:允许通过超类类型引用调用子类对象特有的行为(如通过
Object引用调用clone())。 - 安全性:如
wait()和notify()方法,提供了线程间通信的机制。 - 便利性:如
toString()和equals()方法,为对象的字符串表示和比较提供了默认实现,方便开发者重写以适应具体需求。 - 辅助功能:如
hashCode()方法,支持对象在哈希表中的存储和检索。 - 清理:如
finalize()方法,尽管不推荐使用,但为对象提供了执行清理操作的机会。
示例代码
public class ExampleObject {
public static void main(String[] args) {
Object obj = new Object();
System.out.println("Object hash code: " + obj.hashCode());
System.out.println("Object class: " + obj.getClass().getName());
System.out.println("Object as string: " + obj.toString());
}
}
在这个示例中,我们创建了一个Object实例,并调用了hashCode()、getClass()和toString()方法。
理解Object类提供的这些方法对于Java开发者来说非常重要,因为它们是Java语言的基石,并且在编写和维护代码时经常会用到。通过这些方法,Java确保了不同类的对象能够进行基本的交互和操作。
在Java编程中,比较两个对象是否相等是一个常见的任务。开发者经常使用==运算符和equals()方法来进行比较,但它们在功能和用途上有着本质的区别。本文将深入探讨equals()与==的区别、联系以及在不同场景下的应用。
==运算符:引用的比较
==运算符用于比较两个对象的引用是否相同,即它们是否指向内存中的同一个对象。
示例代码
String s1 = new String("hello");
String s2 = s1;
System.out.println(s1 == s2); // 输出 true,因为 s1 和 s2 指向同一个对象
equals()方法:逻辑相等的比较
equals()方法用于比较两个对象的逻辑相等性,即比较它们的属性值是否相等。默认情况下,Object类的equals()方法比较对象的引用,但通常需要被重写以实现具体的比较逻辑。
示例代码
String s3 = new String("hello");
String s4 = new String("hello");
System.out.println(s3.equals(s4)); // 输出 true,因为内容相等
equals()与==的区别
比较内容:equals()比较对象的逻辑相等性,==比较对象的引用是否相同。
- 重写:
equals()方法可以被重写以实现具体的比较逻辑,而==运算符不能被重写。 - 类型限制:
==可以用于比较原始数据类型,而equals()只能用于对象。 - 一致性:使用
equals()时,需要遵循等价关系的几个原则,如自反性、对称性、传递性和一致性。
equals()与==的联系
- 对象引用:如果两个对象的引用相同,那么
equals()和==都会返回true。 - 非重写情况:如果没有重写
equals()方法,那么equals()实际上比较的是对象的引用,与==运算符相同。
重写equals()方法的最佳实践
- 重写
hashCode():如果重写了equals(),也应该重写hashCode(),保证相等的对象有相同的哈希码。 - 检查
null:在比较前检查对象是否为null。 - 实例of类:确保对象是正确的类型。
- 使用
instanceof:在进行类型转换前,使用instanceof检查对象的实际类型。
实际案例演示
以下是一个正确重写equals()和hashCode()的示例。
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
Person person = (Person) obj;
return age == person.age && name.equals(person.name);
}
@Override
public int hashCode() {
int result = name.hashCode();
result = 31 * result + age;
return result;
}
public static void main(String[] args) {
Person p1 = new Person("John", 30);
Person p2 = new Person("John", 30);
System.out.println(p1.equals(p2)); // 输出 true
}
}
正确理解和使用equals()与==对于编写正确的对象比较逻辑至关重要。开发者应该根据比较的目的选择适当的方法,并确保遵守相关的编程原则。
Java对象拷贝:深拷贝与浅拷贝的深度解析
在Java编程中,对象的拷贝是一个常见的操作,尤其是当需要复制一个对象以保持状态的独立性时。拷贝分为深拷贝和浅拷贝,它们在对象的复制行为上有着本质的不同。本文将深入探讨深拷贝与浅拷贝的区别、联系以及如何在Java中实现它们。
浅拷贝:表面的复制
浅拷贝只复制对象本身,而不复制对象引用的对象。如果对象的属性包含对其他对象的引用,那么浅拷贝会共享这些引用。
示例代码
public class ShallowCopyExample {
static class Person {
private String name;
private Address address; // 引用类型
public Person(String name, Address address) {
this.name = name;
this.address = address;
}
// Getters and setters
}
static class Address {
private String city;
public Address(String city) {
this.city = city;
}
// Getters and setters
}
public static void main(String[] args) {
Address address = new Address("New York");
Person p1 = new Person("John", address);
Person p2 = new Person("Jane", p1.address); // 浅拷贝,共享address引用
p2.address.city = "Los Angeles";
System.out.println(p1.address.city); // 输出 "Los Angeles",p1和p2的address引用了同一个对象
}
}
深拷贝:彻底的复制
深拷贝会递归复制对象以及对象引用的所有对象,直到所有引用的对象都复制完毕。深拷贝创建了对象的一个完全独立副本。
示例代码
public class DeepCopyExample {
// Person 和 Address 类定义与上文相同
static class DeepCopyPerson extends Person {
public DeepCopyPerson(Person original) {
super(original.name); // 复制基本类型
this.address = new Address(original.address.city); // 复制引用类型
}
}
public static void main(String[] args) {
Address address = new Address("New York");
Person p1 = new Person("John", address);
Person p2 = new DeepCopyPerson(p1); // 深拷贝
p2.address.city = "Los Angeles";
System.out.println(p1.address.city); // 输出 "New York",p1和p2的address是不同的对象
}
}
深拷贝与浅拷贝的区别
- 复制深度:浅拷贝只复制对象本身,而深拷贝复制对象及其所有引用的对象。
- 对象引用:浅拷贝后的对象共享了原始对象的引用,深拷贝则不共享。
- 开销:深拷贝比浅拷贝有更大的性能开销,因为它需要复制更多的对象。
深拷贝与浅拷贝的联系
- 目的:两者都用于复制对象,以保持状态的独立性或避免外部修改影响原始对象。
- 实现:深拷贝通常通过递归复制实现,而浅拷贝可能只需要复制对象本身。
实现深拷贝的注意事项
- 递归复制:确保深拷贝递归地复制了所有层级的引用对象。
- 循环引用:注意处理对象间的循环引用,避免无限递归。
- 性能考虑:深拷贝可能会消耗更多的资源,特别是在对象图复杂或对象较大时。
在Java中,深拷贝与浅拷贝各有其适用场景。选择使用哪种拷贝方式取决于对象的结构和程序的需求。理解它们的区别对于编写正确的、高效的Java程序至关重要。
Java中的“魔法咒语”:关键字的力量!
在Java的世界里,有一群特殊的词汇,它们拥有着神秘的力量,能够引导程序的流程,定义数据的结构,甚至改变程序的行为。这些词汇就是Java中的关键字。今天,我将带你揭开这些“魔法咒语”的神秘面纱,看看它们是如何在Java的魔法世界中施展它们的力量的。
1. 数据类型关键字
Java中的数据类型关键字定义了变量的类型,它们告诉编译器变量可以存储什么类型的数据。
int age = 25; // 整型关键字
double pi = 3.14; // 浮点型关键字
boolean isStudent = true; // 布尔型关键字
String name = "Alice"; // 字符串关键字
2. 控制流程关键字
控制流程关键字控制程序的执行流程,它们决定了代码的执行顺序。
if (age >= 18) {
System.out.println("You are an adult.");
} else {
System.out.println("You are a minor.");
}
for (int i = 0; i < 5; i++) {
System.out.println("Loop iteration " + i);
}
while (condition) {
// 循环体
}
do {
// 循环体
} while (condition);
3. 异常处理关键字
异常处理关键字帮助我们处理程序运行时可能出现的错误。
try {
// 可能抛出异常的代码
} catch (ExceptionType e) {
// 处理异常
} finally {
// 无论是否发生异常都会执行的代码
}
4. 类和对象关键字
类和对象关键字定义了Java程序的基本结构。
class MyClass {
// 类定义
}
MyClass myObject = new MyClass(); // 创建对象
5. 访问修饰符关键字
访问修饰符关键字控制类、方法和变量的访问级别。
public class PublicClass {
// 公共类
}
private void privateMethod() {
// 私有方法
}
6. 继承和多态关键字
继承和多态关键字允许我们创建可扩展和可重用的代码。
class Animal {
// 父类
}
class Dog extends Animal {
// 子类
}
7. 同步关键字
同步关键字用于控制对共享资源的并发访问。
synchronized void synchronizedMethod() {
// 同步方法
}
8. 断言关键字
断言关键字用于调试和测试,它允许我们验证程序的假设。
assert condition : "Assertion failed";
Java中的关键字是构建程序的基石。它们不仅定义了程序的结构和行为,还提供了控制程序流程的强大工具。作为高级Java架构师,我们应该深入理解这些关键字的使用和它们背后的原理,以便在实际开发中更加有效地利用这一特性。现在,你已经掌握了Java中的“魔法咒语”,是时候在你的代码中施展它们了!
JRE(Java Runtime Environment)和JDK(Java Development Kit)都是Java平台的核心组成部分,但它们的角色和用途有所不同。
JRE(Java Runtime Environment)
JRE是Java运行时环境,它是运行已编译Java程序所需的最小环境。JRE包含了Java虚拟机(JVM)和运行Java应用程序所需的核心类库。然而,JRE不包含开发Java应用程序所需的编译工具和软件。
JRE的主要特点:
- 运行Java程序:允许用户运行Java应用程序。
- 包含JVM:提供Java虚拟机来执行Java字节码。
- 不包含开发工具:不包括编译器(javac)或其他开发工具。
- 适用于终端用户:通常安装在不打算进行Java开发的机器上。
JDK(Java Development Kit)
JDK是Java开发工具包,它包含了JRE的所有内容,并且还包括了开发Java应用程序所需的编译器、工具和库。JDK是为Java开发者设计的,它允许开发者编译、测试和调试Java应用程序。
JDK的主要特点:
- 开发Java程序:提供了编译器(javac)和运行工具(java)。
- 完整的类库:包含了JRE的所有类库,以及额外的开发相关类库。
- 开发工具:包括调试器、打包工具(如jar)、自动生成文档的工具(如javadoc)等。
- 适用于开发者:是专业开发者的标准配置。
JRE与JDK的区别:
- 用途:JRE用于运行Java应用程序,而JDK用于开发Java应用程序。
- 内容:JDK包含了JRE的全部内容,并且还有编译器、调试器、工具和更多的库。
- 大小:JDK的体积比JRE大,因为它包含了更多的工具和库。
- 安装:如果你需要开发Java应用程序,你应该安装JDK;如果你只需要运行Java应用程序,安装JRE就足够了。
示例:
假设你想运行一个Java Web应用程序:
- 作为用户:你可能只需要安装JRE,因为你只需要运行由服务器提供的Java应用程序。
- 作为开发者:你需要安装JDK来编译、调试和打包你的Java应用程序。
选择JRE或JDK取决于你的具体需求。如果你是一名Java开发者,那么JDK是必需的。如果你只是想运行Java应用程序,JRE就足够了。
**
Java 中应该使用什么数据类型来代表价格?
**
在Java中表示价格时,选择合适的数据类型对于确保精度和避免潜在的舍入误差非常重要。以下是几种可用于表示价格的数据类型,以及它们的适用场景:
1. float 和 double
float 和 double 是Java中的两种浮点数类型,分别对应单精度和双精度浮点数。尽管它们可以用来表示价格,但通常不推荐这样做,因为浮点数使用IEEE 754标准表示,这可能导致不可预知的舍入误差。
2. BigDecimal
BigDecimal 是Java数学包中的一个类,它提供了对任意精度定点数的表示。BigDecimal 能够非常精确地处理很大的数值或非常小的数值,并且可以控制舍入行为,这使得它成为表示价格的理想选择。
示例代码:
BigDecimal price = new BigDecimal("19.99");
BigDecimal taxRate = new BigDecimal("0.07");
BigDecimal totalPrice = price.add(price.multiply(taxRate));
System.out.println("Total Price: " + totalPrice);
3. int 或 long
如果价格总是以最小的货币单位(如分、厘)表示,可以使用 int 或 long 类型来存储价格。这种方法避免了浮点数的舍入误差,但需要在执行货币计算时手动处理转换。
示例代码:
int priceInCents = 1999; // 实际价格为 $19.99
int taxInCents = 700; // 7% 税,表示为 700 分
int totalPriceInCents = priceInCents + (priceInCents * taxInCents / 100);
System.out.println("Total Price: $" + totalPriceInCents / 100.0);
4. String
在某些情况下,如果计算逻辑由外部系统处理,或者你只需要显示价格而不进行计算,可以使用 String 类型来表示价格。
**- 当精度是关键,且价格需要参与计算时,推荐使用 BigDecimal。
- 如果价格以最小单位表示,并且计算简单,可以使用
int或long。 - 如果只需要显示价格而不进行计算,可以使用
String。**
在金融和货币计算中,精度至关重要,因此 BigDecimal 是最安全的选择。务必避免使用 float 和 double 来处理涉及金钱的计算。

在Java中,++ 操作符本身是否线程安全取决于它的使用上下文。++ 是一个语句,可以是前缀(++i)或后缀(i++)形式。
简单场景下的线程安全
对于简单的自增操作,如果一个线程在执行它,并且没有其他线程会观察或修改这个变量,那么这个操作是线程安全的。
竞争条件
问题出现在多个线程尝试同时修改同一个变量时,这种情况下,++ 操作符可能会引入竞争条件。例如:
public class Counter {
private int count = 0;
public void increment() {
count++;
}
}
如果多个线程同时调用 increment() 方法,那么 count 变量的值可能不会按预期增加。这是因为自增操作实际上涉及几个步骤:
- 读取
count的当前值。 - 将该值增加1。
- 将增加后的值写回
count。
当多个线程并发执行这些步骤时,它们可能会读取相同的初始值,导致最终写回的值低于预期。
解决线程安全问题
为了使 ++ 操作符在多线程环境中线程安全,可以使用以下几种方法:
- 同步代码块:使用
synchronized关键字同步代码块。
public synchronized void increment() {
count++;
}
- 原子类:使用
AtomicInteger或其他原子类,它们提供了线程安全的递增操作。
import java.util.concurrent.atomic.AtomicInteger;
public class Counter {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet();
}
}
- 锁:使用
ReentrantLock或其他锁机制来保护临界区。
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class Counter {
private int count = 0;
private Lock lock = new ReentrantLock();
public void increment() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
}
++ 操作符在单线程环境中是线程安全的,但在多线程环境中需要额外的同步措施来保证线程安全。使用 synchronized、原子类或锁可以确保递增操作在并发环境中的线程安全。
-
什么是Java虚拟机(JVM),它在Java平台中扮演什么角色?
- JVM是一个可以执行Java字节码的虚拟计算机。它为Java程序提供了一个独立于硬件和操作系统的平台。
-
解释Java内存模型(JMM)以及它的重要性。
- JMM定义了Java程序中各种变量的访问规则,确保了在多线程环境下的内存一致性。
-
如何判断一个对象是否可垃圾回收?
- 当一个对象没有任何引用指向它时,它就变得可垃圾回收。垃圾收集器会在适当的时候回收这样的对象。
-
垃圾收集算法有哪些,它们是如何工作的?
- 常见的垃圾收集算法包括标记-清除、复制、标记-整理和分代收集。每种算法都定义了如何识别、标记和回收不再使用的对象。
-
如何选择合适的垃圾收集器?
- 根据应用程序的需求,如延迟敏感度、吞吐量、内存占用等,选择合适的垃圾收集器。
-
解释强引用、软引用、弱引用和虚引用的区别。
- 强引用是最常见的,只要存在就不会被回收。软引用、弱引用和虚引用在垃圾回收时有被回收的可能,它们用于更细粒度的内存管理和优化。
-
什么是类加载器,Java中有哪些类加载器?
- 类加载器负责加载类文件。Java中有引导类加载器、扩展类加载器和应用程序类加载器。
-
双亲委派模型是什么,它有什么优势?
- 双亲委派模型是一种类加载器的搜索策略,确保了Java核心类的唯一性和安全性。
-
如何实现一个自定义的类加载器?
- 通过继承
java.lang.ClassLoader类并重写findClass和loadClass方法来实现。
- 通过继承
-
解释Java中的多态和如何实现多态。
- 多态是对象可以有多种形式的特性。在Java中,多态通过方法重写和接口实现来完成。
-
抽象类和接口有什么区别?
- 抽象类可以有具体的方法实现,而接口不能。一个类可以实现多个接口,但只能继承一个抽象类。
-
如何设计一个Java API?
- 设计Java API时要考虑清晰性、一致性、可扩展性和文档。
-
解释Java反射机制以及如何使用它?
- 反射允许程序在运行时查询和操作类的对象,包括获取类的实例、构造器、方法和字段。
-
动态代理和静态代理有什么区别?
- 动态代理是在运行时创建的,而静态代理是在编译时创建的。
-
什么是Java注解,它们是如何工作的?
- 注解是一种特殊的接口,用于在源代码中添加元数据。它们可以被反射机制读取。
-
什么是依赖注入,它有什么好处?
- 依赖注入是一种设计模式,用于减少对象之间的耦合,提高代码的可测试性和可维护性。
-
解释Java中的同步和异步。
- 同步操作是阻塞的,而异步操作是非阻塞的。同步通常用于简单的操作,异步用于可能需要很长时间的操作。
-
如何在Java中创建线程安全的代码?
- 通过使用同步代码块、锁、原子变量或并发集合来确保线程安全。
-
解释Java中的Executor框架。
- Executor框架提供了一种管理线程和任务的机制,允许开发者以一种更灵活和强大的方式来处理并发。
-
什么是Fork/Join框架,它是如何工作的?
- Fork/Join框架是一种用于并行任务执行的框架,它通过将任务分割成更小的子任务来实现工作窃取算法。
-
什么是Fork/Join框架,它是如何工作的?
-
解释Java中的Callable和Future接口。
-
如何避免死锁?
-
解释Java中的synchronized和java.util.concurrent包。
-
什么是不可变对象,它有什么优势?
-
解释Java中的线程局部变量。
-
如何在Java中实现生产者-消费者问题?
-
解释Java中的BlockingQueue。
-
解释Java中的线程池参数。
-
如何在Java中实现一个简单的线程池?
-
解释Java中的ReadWriteLock。
-
什么是乐观锁和悲观锁?
-
解释Java中的StampedLock。
-
解释Java中的原子操作类。
-
如何在Java中实现一个无锁编程?
-
解释Java中的并发集合类。
-
解释CopyOnWriteArrayList的工作原理。
-
解释ConcurrentHashMap的工作原理。
-
解释Java中的ThreadLocal变量。
-
解释Java中的Phaser和Barrier同步辅助类。
-
解释Java中的CountDownLatch和CyclicBarrier。
-
解释Java中的CompletableFuture。
-
解释Java中的中断机制。
-
如何在Java中处理线程中断?
-
解释Java中的中断状态和中断请求。
-
解释Java中的中断传播。
-
解释Java中的中断处理。
-
解释Java中的中断源。
-
解释Java中的守护线程。
-
解释Java中的用户线程。
-
解释Java中的线程组。
-
解释Java中的线程优先级。
-
解释Java中的线程状态。
-
解释Java中的线程调度。
-
解释Java中的线程栈。
-
如何监控Java应用程序的线程状态?
-
解释Java中的堆和栈的区别。
-
解释Java中的直接内存。
-
解释Java中的OutOfMemoryError。
-
解释Java中的StackOverflowError。
-
解释Java中的Java堆和元空间的区别。
-
解释Java中的垃圾收集器的日志。
-
如何分析Java垃圾收集器的日志?
-
解释JVM的参数调优。
-
解释JVM的内存泄漏。
-
如何诊断Java中的内存泄漏?
-
解释Java中的类卸载。
-
解释Java中的类加载机制。
-
解释Java中的字节码。
-
解释Java字节码的验证过程。
-
解释Java字节码的执行过程。
-
解释Java中的即时编译(JIT)。
-
解释Java中的热点代码。
-
解释Java中的编译器优化。
-
解释Java中的逃逸分析。
-
解释Java中的编译器白名单。
-
解释Java中的编译器优化阈值。
-
解释Java中的编译器指令重排。
-
解释Java中的动态编译。
-
解释Java中的静态编译。
-
解释Java中的AOT编译。
-
解释Java中的JIT编译。
-
解释Java中的分层编译。
-
解释Java中的C1和C2编译器。
-
解释Java中的Graal编译器。
-
解释Java中的编译器性能分析。
-
解释Java中的编译器监控。
-
解释Java中的编译器诊断工具。
-
解释Java中的JVM监控工具。
-
解释Java中的JVM性能计数器。
-
解释Java中的JVM诊断命令。
-
解释Java中的JVM性能分析。
-
解释Java中的JVM性能调优。
-
解释Java中的JVM故障排查。
-
解释Java中的JVM内存模型。
-
解释Java中的JVM启动参数。
-
解释Java中的JVM工具。
-
解释Java中的JVM日志。
-
解释Java中的JVM配置。
-
解释Java中的JAR文件。
-
解释Java中的WAR文件。
-
解释Java中的EAR文件。
-
解释Java中的JNLP文件。
-
解释Java中的JDBC。
-
解释Java中的JPA。
-
解释Java中的ORM。
-
解释Java中的Hibernate。
-
解释Java中的Spring框架。
-
解释Java中的Spring Boot。
-
解释Java中的依赖注入。
-
解释Java中的控制反转。
-
解释Java中的面向切面编程(AOP)。
-
解释Java中的Spring AOP。
-
解释Java中的Spring MVC。
-
解释Java中的Spring Security。
-
解释Java中的Spring Data。
-
解释Java中的Spring Cloud。
-
解释Java中的微服务架构。
-
解释Java中的服务发现。
-
解释Java中的服务注册。
-
解释Java中的API网关。
-
解释Java中的配置中心。
-
解释Java中的断路器模式。
-
解释Java中的微服务监控。
-
解释Java中的微服务测试。
-
解释Java中的微服务部署。
-
解释Java中的微服务版本控制。
-
解释Java中的微服务安全。
-
解释Java中的微服务事务管理。
-
解释Java中的RESTful API。
-
解释Java中的SOAP服务。
-
解释Java中的XML。
-
解释Java中的JSON。
-
解释Java中的Web服务。
-
解释Java中的Web容器。
-
解释Java中的Servlet。
-
解释Java中的Filter。
-
解释Java中的Listener。
-
解释Java中的JSP。
-
解释Java中的EL表达式。
-
解释Java中的JSTL。
-
解释Java中的Taglib。
-
解释Java中的MVC架构。
-
解释Java中的设计模式。
-
解释Java中单例模式。
-
解释Java中的工厂模式。
-
解释Java中的建造者模式。
-
解释Java中的原型模式。
-
解释Java中的适配器模式。
-
解释Java中的桥接模式。
-
解释Java中的组合模式。
-
解释Java中的装饰器模式。
-
解释Java中的外观模式。
-
解释Java中的享元模式。
-
解释Java中的代理模式。
-
解释Java中的模板方法模式。
-
解释Java中的观察者模式。
-
解释Java中的状态模式。
-
解释Java中的策略模式。
-
解释Java中的命令模式。
-
解释Java中的职责链模式。
-
解释Java中的中介者模式。
-
解释Java中的迭代器模式。
-
解释Java中的访问者模式。
-
解释Java中的备忘录模式。
-
解释Java中的解释器模式。
-
解释UML类图。
-
解释UML序列图。
-
解释UML用例图。
-
解释UML组件图。
-
解释UML部署图。
-
解释UML活动图。
-
解释UML状态图。
-
解释软件设计原则。
-
解释SOLID原则。
-
解释DRY原则。
-
解释KISS原则。
-
解释YAGNI原则。
-
解释LOD原则。
-
解释开放/封闭原则。
-
解释里氏替换原则。
-
解释接口隔离原则。
-
解释依赖倒置原则。
-
解释迪米特法则。
-
解释Java中的反模式。
-
解释Java中的代码重构。
-
解释Java中的代码审查。
-
解释Java中的性能优化。
-
解释Java中的数据库连接池。
-
解释Java中的数据库事务。
-
解释Java中的数据库索引。
-
解释Java中的SQL注入。
-
解释Java中的XSS攻击。
-
解释Java中的CSRF攻击。
-
解释Java中的加密算法。
-
解释Java中的哈希算法。
-
解释Java中的数字签名。
-
解释Java中的OAuth。
-
解释Java中的SSL/TLS。
-
解释Java中的网络编程。
-
解释Java中的并发编程模型。















 18万+
18万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









