









生成式人工智能(Generative AI)是指那些能够生成新的、原创性的内容的人工智能系统。与传统的人工智能系统强调模式识别和推理不同,生成式AI专注于创造新的、无监督的数据。
总结了近三个月的工作流,包含视频转绘,SVD,stablezero123,面部高清放大,丝滑变装,起手式,实时绘画等等共计66个工作流
链接:https://pan.quark.cn/s/320387279505
AI绘画关于SD,MJ,GPT,SDXL,Comfyui百科全书(https://yv4kfv1n3j.feishu.cn/docx/MRyxdaqz8ow5RjxyL1ucrvOYnnH)

1.Text2motion
官网
https://ericguo5513.github.io/momask/
这个跟ebsynth的逻辑很相似,或者说平时搭建的工作量里面会利用蒙版固定人物的范围,而不是openpose,因为openpose人物姿态更加生硬,如果让AI自己发挥,蒙版是个最优选择,ipadapter搭配效果也不错。
这是一种新颖的蒙版建模框架,用于生成文本驱动的 3D 人体运动。在MoMask中,采用分层量化方案将人体运动表示为具有高保真细节的多层离散运动标记。从基础层开始,通过向量量化获得一系列运动标记,将递增阶数的剩余标记派生并存储在层次结构的后续层。因此,紧随其后的是两个不同的双向变压器。对于基础层运动令牌,指定了一个掩码转换器来预测随机掩码运动令牌,条件是训练阶段的文本输入。在生成(即推理)阶段,从空序列开始,我们的 Masked Transformer 迭代填充缺失的令牌;随后,残差转换器学习根据当前层的结果逐步预测下一层令牌。大量实验表明,MoMask 在文本到动作生成任务上优于最先进的方法,在 HumanML3D 数据集上的 FID 分别为 0.045(与 T2M-GPT 的 0.141 相比)和 KIT-ML 的 0.228(与 0.514 相比)。MoMask 还可以无缝应用于相关任务,而无需进一步对模型进行微调,例如文本引导的时间修复。
photomaker
官网:https://photo-maker.github.io/
,时长00:32
腾讯的开源产品很多的哈,可能大家一开始没注意,比如应用在controlnet里面的ipadapter,放大算的ESRGAN,这些都是腾讯旗下的开源产品,现在这个Photomaker做真实图片,图像迁移,风格有ipadapter的影子
文本到图像生成的最新进展在合成基于给定文本提示的逼真人类照片方面取得了显着进展。然而,现有的个性化生成方法无法同时满足高效率、有前途的身份(ID)保真度和灵活的文本可控性等要求。在这项工作中,我们介绍了PhotoMaker,这是一种高效的个性化文本到图像生成方法,它主要将任意数量的输入ID图像编码到堆栈ID嵌入中,以保存ID信息。这样的嵌入,作为统一的ID表示,不仅可以全面封装同一输入ID的特征,还可以容纳不同ID的特征,以便后续集成。这为更有趣和更实用的应用铺平了道路。此外,为了推动PhotoMaker的训练,我们提出了一个面向ID的数据构建管道来组装训练数据。在通过拟议的管道构建的数据集的滋养下, 与基于测试时微调的方法相比,我们的 PhotoMaker 具有更好的 ID 保留能力,但可显著提高速度、获得高质量的生成结果、强大的泛化能力和广泛的应用。
AI模特商用线上版本
本地版可看下这期,支持本地部署,SD,SDXL全部支持Animatediff v3 又又叒更新?阿里商业模特换衣本地化 Animate Anyone和Outfit Anyone 开源
在线版网址
https://www.xiangjifanyi.com/console/register-invite/009a960d6e294dc2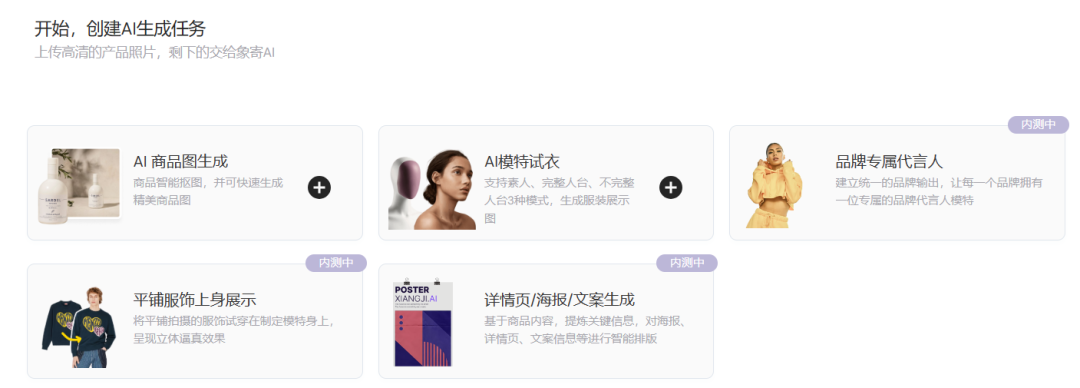
一、上传商品主体
-
背景干净为佳
-
系统会自动抠图,如果背景过于杂乱,可能需要进行抠图精修
-
如有白底图,可直接上传
-
-
商品图像清晰,忌原图就非常模糊


基于SDXL微调的大模型
基于SDXL微调的大模型SDXLDPO模型发布,可以提升整体生成画质,目前已经开放下载,在SDXL的基础上更加细腻的微调模型,使用记得调整为SDXL生态
链接:https://pan.quark.cn/s/af2d416de90d
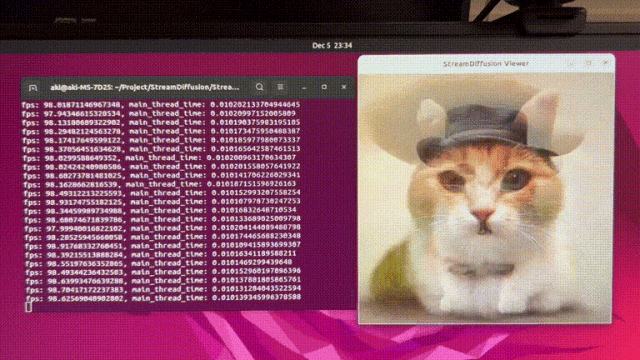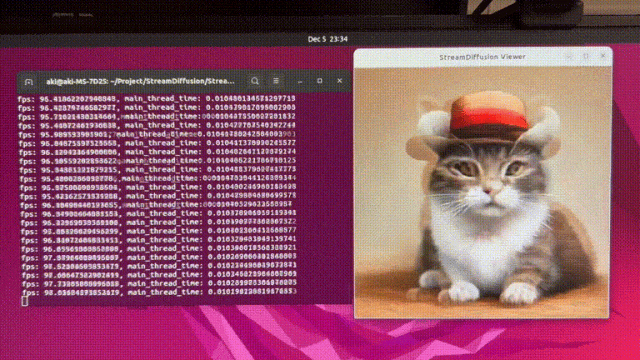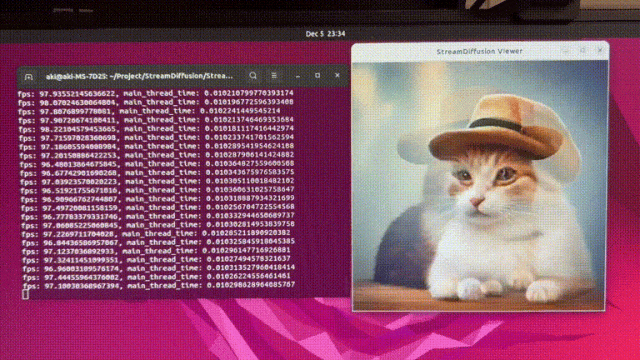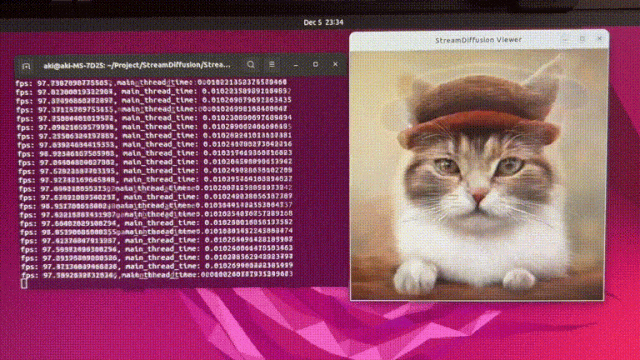
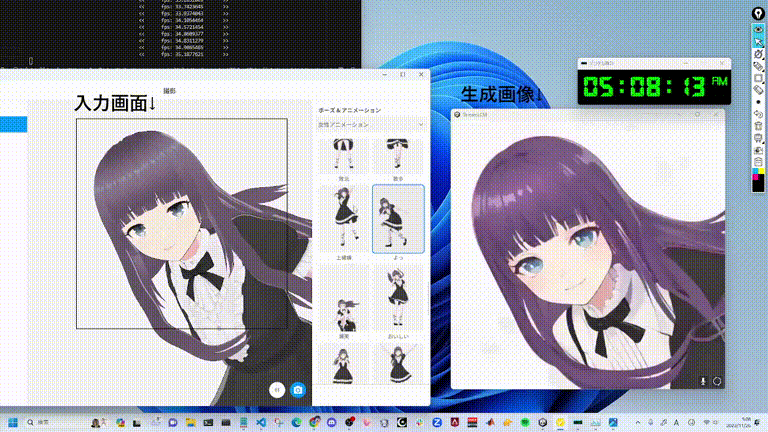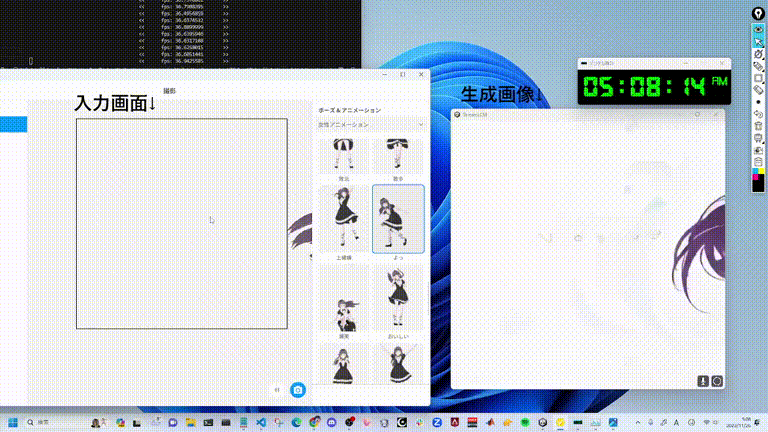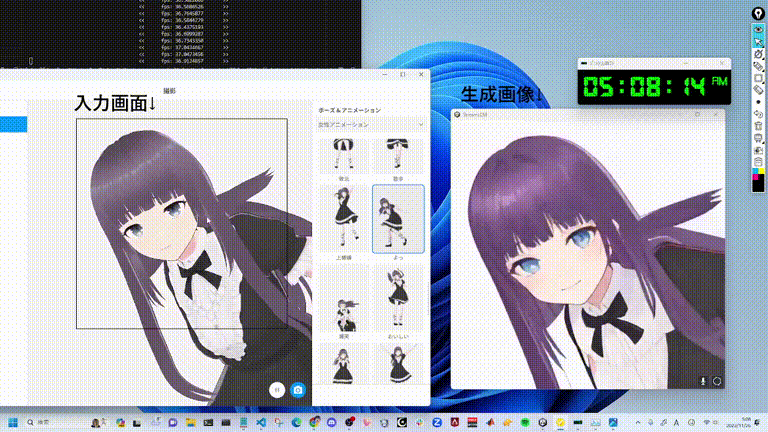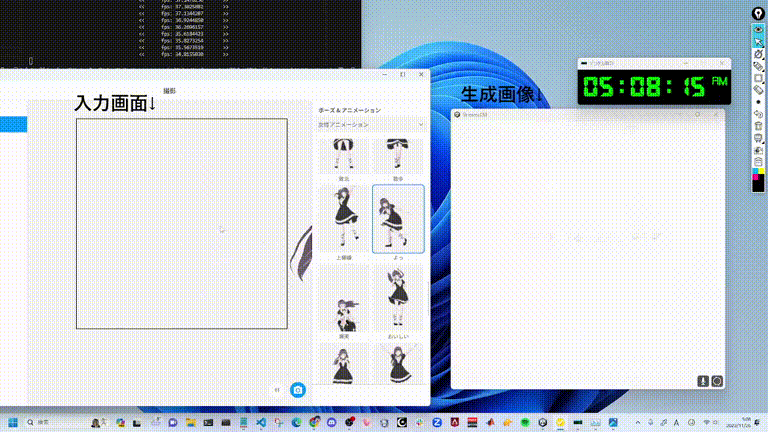
StreamDiffusion
https://github.com/cumulo-autumn/StreamDiffusion/tree/main更加丝滑的扩散模型解决方案,StreamDiffusion 是一种创新的扩散流水线,专为实时交互式生成而设计。它为当前基于扩散的图像生成技术引入了显著的性能增强。
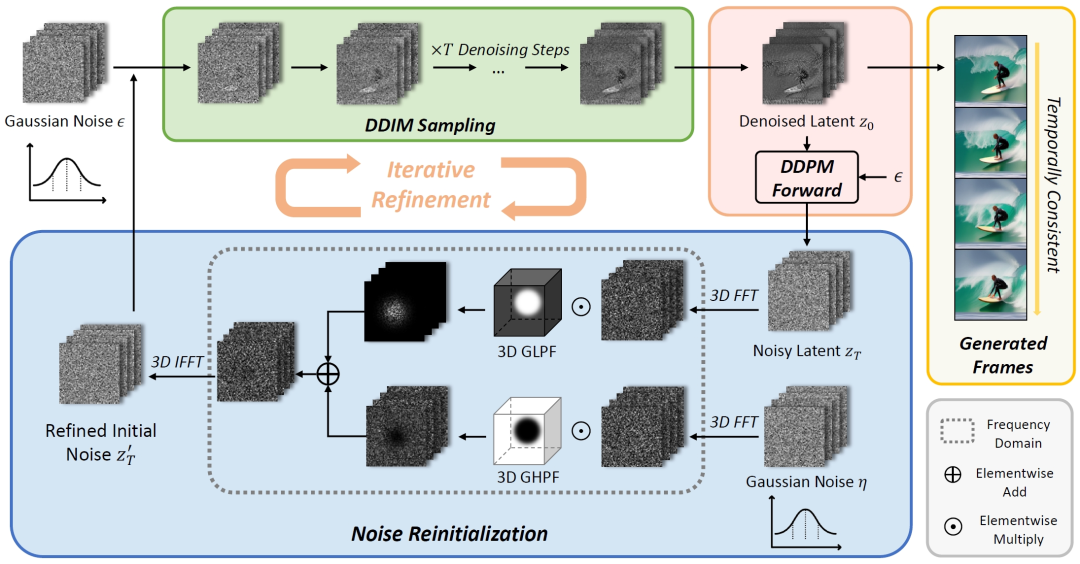
FreeInit
我们提出了FreeInit,这是一种简洁而有效的方法,可以提高扩散模型生成的视频的时间一致性。FreeInit 不需要额外的训练,也没有引入可学习的参数,并且可以在推理时轻松合并到任意视频扩散模型中。
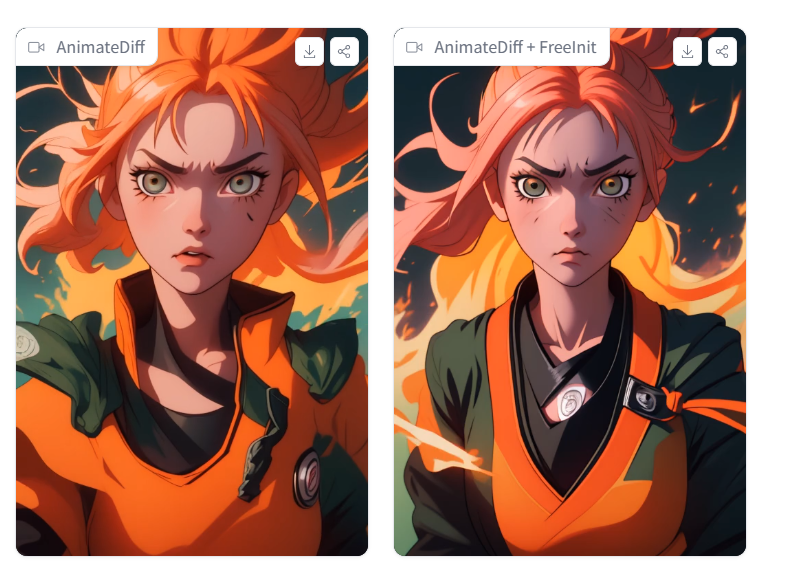
测试提示词:
(2.5D), (ridiculous, incredibly ridiculous, huge file size, super detailed, highresolution, extremely detailed), masterpiece, officiaal art, super high resolution, 1 girl,Naruto IP, ninjutsu, wind, fire, lightning
测试效果


Motion Customization
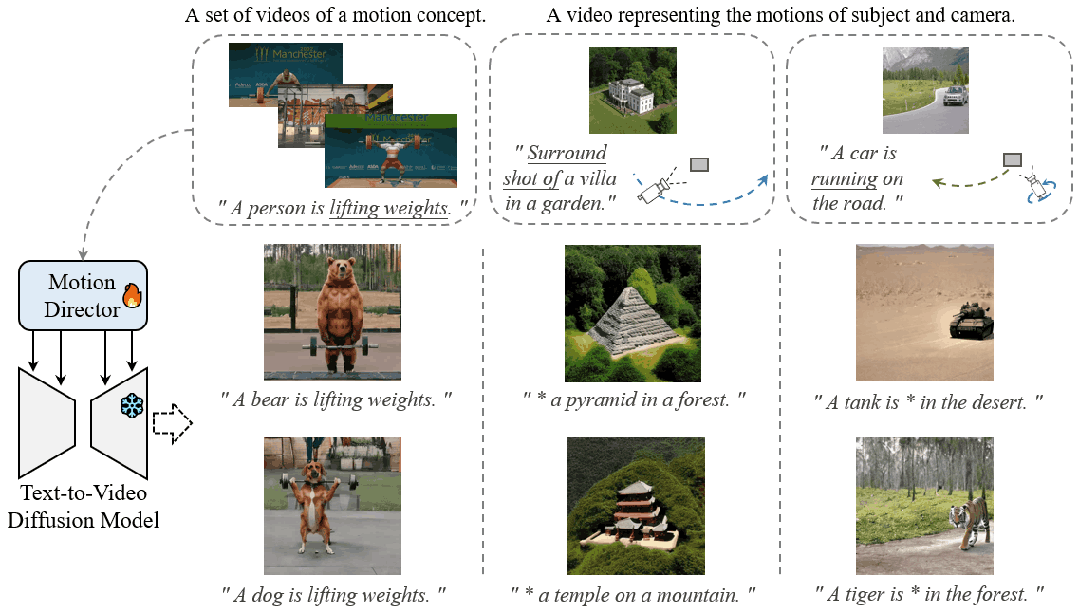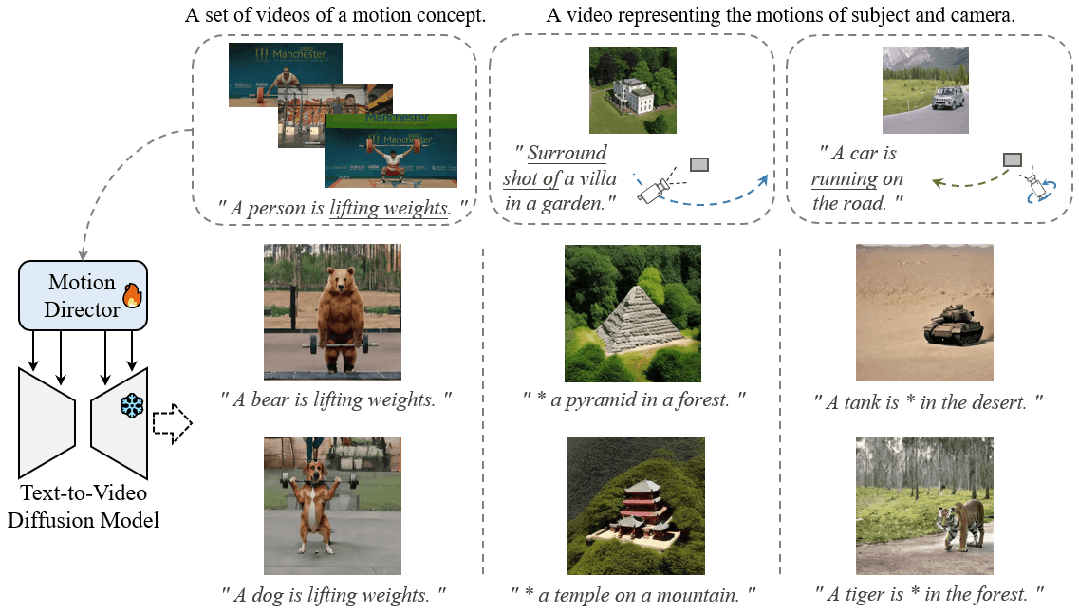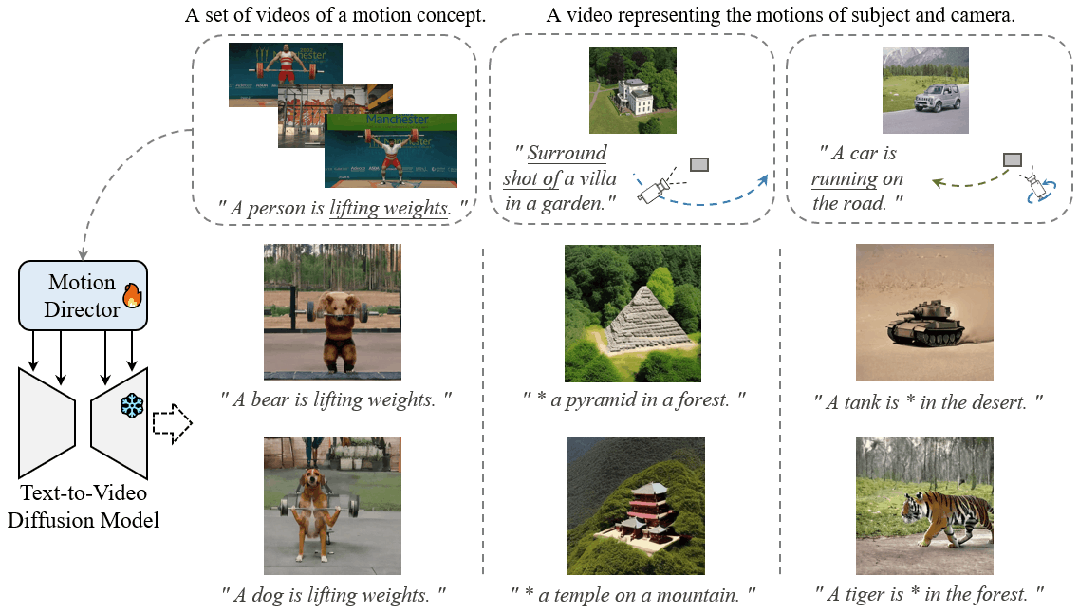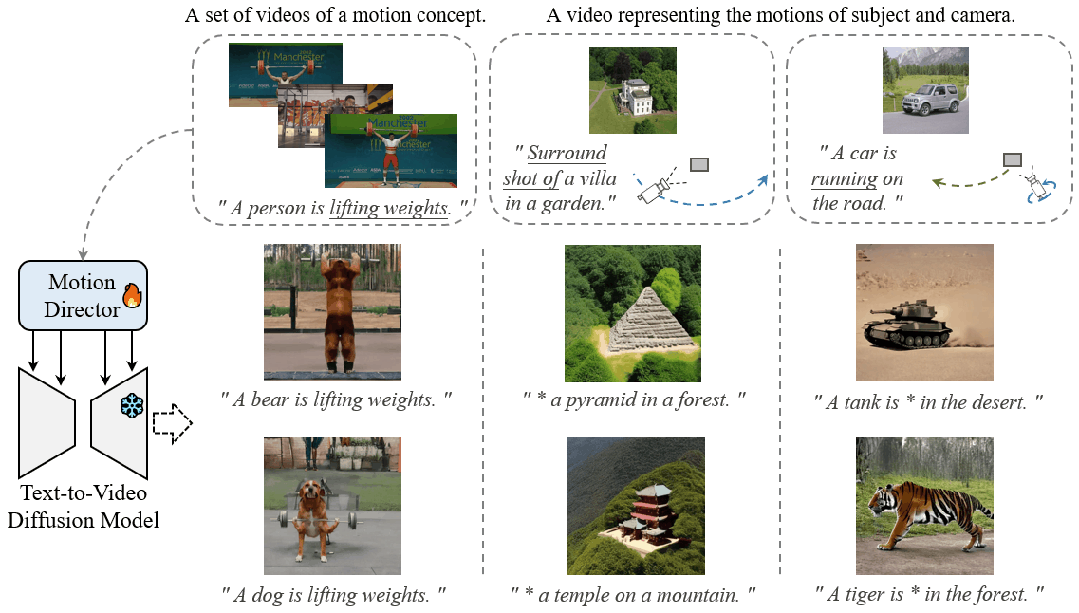
大规模预训练扩散模型在不同的视频生成中表现出了卓越的能力。给定一组具有相同运动概念的视频剪辑,运动定制的任务是调整现有的文本到视频扩散模型,以生成具有此运动的视频。例如,生成一个视频,让汽车在特定的摄像机运动下以规定的方式移动以制作电影,或者制作一个说明熊如何举重的视频来激励创作者。已经开发了用于自定义主题或风格等外观的适应方法,但尚未探索运动。扩展运动定制的主流适配方法非常简单,包括全模型调优、附加层的参数高效调优和低秩自适应 (LoRA)。然而,通过这些方法学到的运动概念往往与训练视频中的有限外观相结合,因此很难将定制的运动推广到其他外观。为了克服这一挑战,我们提出了 MotionDirector,它采用双路径 LoRA 架构,将外观和运动的学习解耦。此外,我们设计了一种新的外观偏倚时间损失,以减轻外观对时间训练目标的影响。实验结果表明,所提方法能够为自定义动作生成不同外观的视频。我们的方法还支持各种下游应用,例如将不同的视频分别与它们的外观和运动混合,以及使用自定义运动对单个图像进行动画处理。我们的代码和模型权重将发布。
,时长02:19
超多AI合集已整理到https://yv4kfv1n3j.feishu.cn/docx/MRyxdaqz8ow5RjxyL1ucrvOYnnH
文档更新
2万字comfyui教程、AI模特、AI换脸、AI抠图、AI制作PPT、AI音频、AI视频、AI物体消除
后台回复【起飞】获取加速插件下载地址
往期精彩内容
春晚龙辰辰被质疑AI * 微软Copilot上手体验 | Playground v2 发布 它在生成效果上比SDXL强2.5倍
炸裂 |谷歌推出GPT4劲敌Gemini大模型 多模态实时性 Bard支持试用
AI绘画的6种方式将你的显卡性能拉满体验SDXL 这一种你绝对没听过
重大更新!!!4G显存就能跑SDXL ?SD1.7或将对F8优化merge
Baichuan2400万免费Tokens+ 向量数据库免费实例,限量领取,不要错过!
Stability videoAI 的生成视频模型 | 盘点OpenAI 的瓜一次吃个够


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









