






解决不断更新的csv文件到Mysql数据库的转存,(解决Kiwi转存数据库问题)
不断更新的csv文件到Mysql数据库转存代码
先说核心思路: 由于csv文件是不断更新的所以我们要设置一个游标,在这里我利用了一个txt文件,第一次读取的时候进行检测,没有就创建一个新的txt文件,并将已读行数设置为0。之后在进行读取文件的时候利用pands的skiprows参数进行跳过。
//这里我们利用cl参数也就是记录的已读代码行数来传参数,表示跳过多少行。
df = pd.read_csv(r'文件位置+文件名.csv', skiprows=int(cl),
header=None,
encoding='gb18030',error_bad_lines=False)
读取数据部分最底下有,在说一下游标的写入,也同样是个txt文本文件,这样能长久保存,每次写的时候选w参数这样能够直接覆盖掉之前的数据。
下面展示一些 内联代码片。
file2 = open(r'文本文件', 'w')
当然我知道这样并不能完全实现自动化,所以还需要利用进程或线程来解决。
下面展示 全部代码。
import pandas as pd
import datetime
import sqlalchemy
# 读取数据当前已经读了多少数据
def countline():
# Python获取系统日期
data = datetime.datetime.now()
data = data.strftime('%Y-%m-%d')
# 判断文件是否存在
try:
file1 = open(r'D:\graduation project\kiwisyslog\Syslogd\Logs\NewSyslogCatchAll-' + data + '-cl.txt', 'r')
print("文件存在,不需要创建")
except:
print('文件不存在创建一个新的文件')
file1 = open(r'D:\graduation project\kiwisyslog\Syslogd\Logs\NewSyslogCatchAll-' + data + '-cl.txt', 'w+')
countline = str(file1.read())
file1.close()
if countline == '':
countline = 0
print(countline)
return countline
# 读法有点粗暴,改用pands来读取数据
# with open('C:/Users/nuo/Desktop/shiyan/log/SyslogCatchAll-2022-10-24_1.csv')as f:
# f_csv = csv.reader(f)
# for row in f_csv:
# print(row)
def cvs_to_mysql():
# Python获取系统日期
data = datetime.datetime.now()
data = data.strftime('%Y-%m-%d')
cl = countline()#获取当前已经读到的行数
try:#这里加try是为了避免没有新的日志出现的时候报错,skiprows跳过全部行后报错。
df = pd.read_csv(r'D:\graduation project\kiwisyslog\Syslogd\Logs\NewSyslogCatchAll-' + data + '.csv', skiprows=int(cl),
header=None,
encoding='gb18030',error_bad_lines=False)
a = len(df)
b = int(cl) + a
writeline(b)
print(cl)
print(df)
#con 参数为数据库的连接,这里不能用pymysql,pymysql只会傻傻 的一行一行写。可以用sqlalchemy,它能把一整个DataFrame一把梭哈掉。
#if_exists 参数判断是否有重复表名,该参数有3个值:fail表示如果表名重复则不写入,replace表示如果表名重复覆盖原表,append表示追加写入。
#engine = sqlalchemy.create_engine("mysql+pymysql://root:******@localhost:3306/数据库名?charset=utf8")
# df.to_sql(name='表名', con=engine, if_exists='replace', index=True)
engine = sqlalchemy.create_engine("mysql+pymysql://root:admin@localhost:3306/syslog?charset=utf8")
df.columns = ['Date','Time','Priority','Hostname','MsgText']
df.to_sql(name='syslogd6', con=engine, if_exists='append', index=False)
except:
print('当前日志已经全部被读取')
def writeline(countline):
# Python获取系统日期
data = datetime.datetime.now()
data = data.strftime('%Y-%m-%d')
file2 = open(r'D:\graduation project\kiwisyslog\Syslogd\Logs\NewSyslogCatchAll-' + data + '-cl.txt', 'w')
file2.write(str(countline))
file2.close()
cvs_to_mysql()
配置Kiwi(不用Kiwi的小伙伴可自行跳过)
本意是希望通过Kiwi直接将日志转存到数据库中,但是在和逗老师交流过程中发现该功能是付费功能,遂决定自己编写代码来实现该功能。
同时也解决了txt到数据库的转存问题。
逗老师原文链接: link
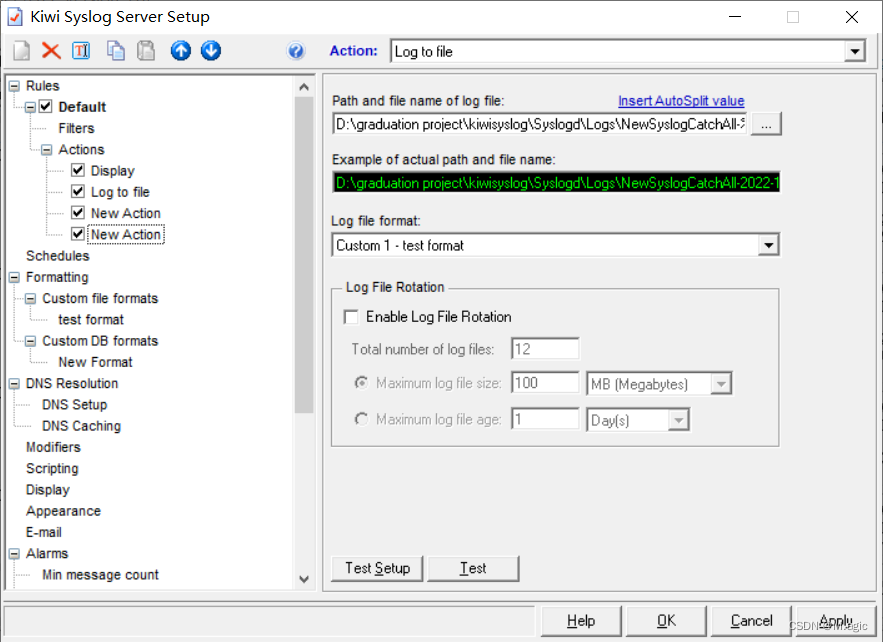
在setup中添加一个new action选择log to file ,我在这里把最后的文件后缀改成了.csv。这样就可以生成csv文件了,格式format部分可以自行设定或选择后面带csv的,这里我自己定义了一个。
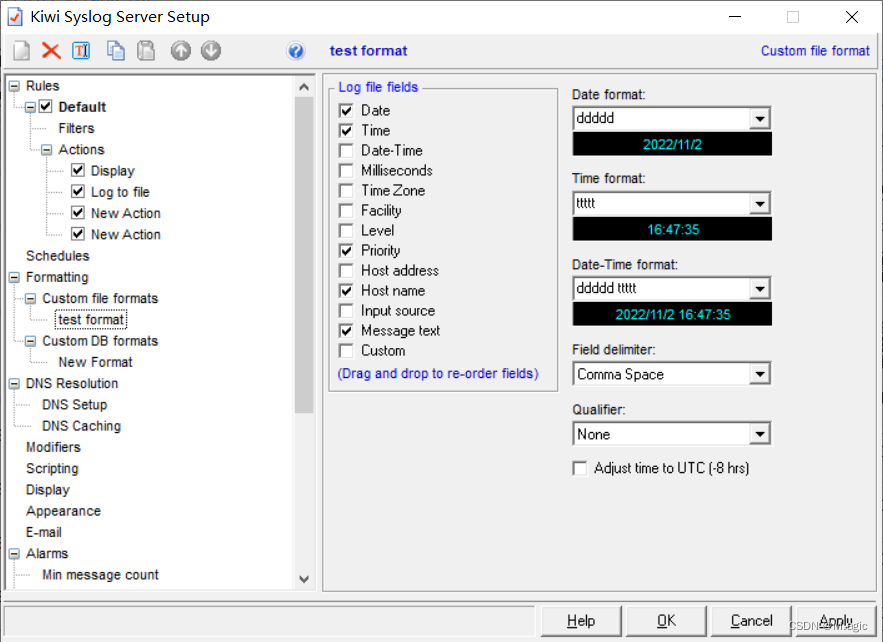
这里我在Formatting里面的Custom file formats 添加了一个自己定义的format,大家可以自己按需选取想要的日志内容,Field delimiter记得选Comma Space。















 4632
4632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









