







查找文件
fileoperate.h:
#include<iostream>
#include <string>
#include <io.h>
#include <vector>
#include <string.h>
#include <stdio.h>
void getFiles(const std::string& path, std::vector<std::string>& files);fileoprate.cpp:
#include "fileoperate.h"
using namespace std;
void getFiles(const std::string& path, std::vector<std::string>& files)
{
//文件句柄
long long hFile = 0;
//文件信息,_finddata_t需要io.h头文件
struct _finddata_t fileinfo;
std::string p;
int i = 0;
if ((hFile = _findfirst(p.assign(path).append("\\*").c_str(), &fileinfo)) != -1)
{//assign赋值(assign(b, begin, len)从字符串b的第begin个字符向后数len个字符赋给字符串a)
do
{
//如果是文件夹,迭代之
//如果是文件,加入列表
if (!(fileinfo.attrib & _A_SUBDIR))
{
files.push_back(p.assign(path).append("\\").append(fileinfo.name));
}
else {
if (strcmp(fileinfo.name, ".") != 0 && strcmp(fileinfo.name, "..") != 0)
getFiles(p.assign(path).append("\\").append(fileinfo.name), files);
}
} while (_findnext(hFile, &fileinfo) == 0);
_findclose(hFile);
}
}删除文件
fileoperate.h:
void deleteFiles(const std::string& path, const std::string file_suffix);fileoprate.cpp:
void deleteFiles(const std::string& path, const std::string file_suffix) {
long long hFile = 0;
struct _finddata_t fileinfo;
std::string p;
int i = 0;
if ((hFile = _findfirst(p.assign(path).append("\\*").c_str(), &fileinfo)) != -1)
{
do
{
if (!(fileinfo.attrib & _A_SUBDIR))
{
if (string(fileinfo.name).find(file_suffix) != string::npos) {
remove(p.assign(path).append("\\").append(fileinfo.name).c_str());
}
}
else {
if (strcmp(fileinfo.name, ".") != 0 && strcmp(fileinfo.name, "..") != 0)
deleteFiles(p.assign(path).append("\\").append(fileinfo.name), file_suffix);
}
} while (_findnext(hFile, &fileinfo) == 0);
_findclose(hFile);
}
}写CSV文件
void test_for_write_csv() {
ofstream outFile;
srand(time(0));
outFile.open("test.csv", ios::out | ios::trunc);
if (!outFile) {
cout << "Failed to open the file." << endl;
}
else {
outFile << "index" << "," << "data1" << "," << "data2" << endl;
for (int i = 0; i < 100; i++) {
outFile << i << ","
<< (rand() % (100 - 1 + 1)) + 1 << ","
<< static_cast <float> (rand()) / (static_cast <float> (RAND_MAX / 100)) << endl;
}
}
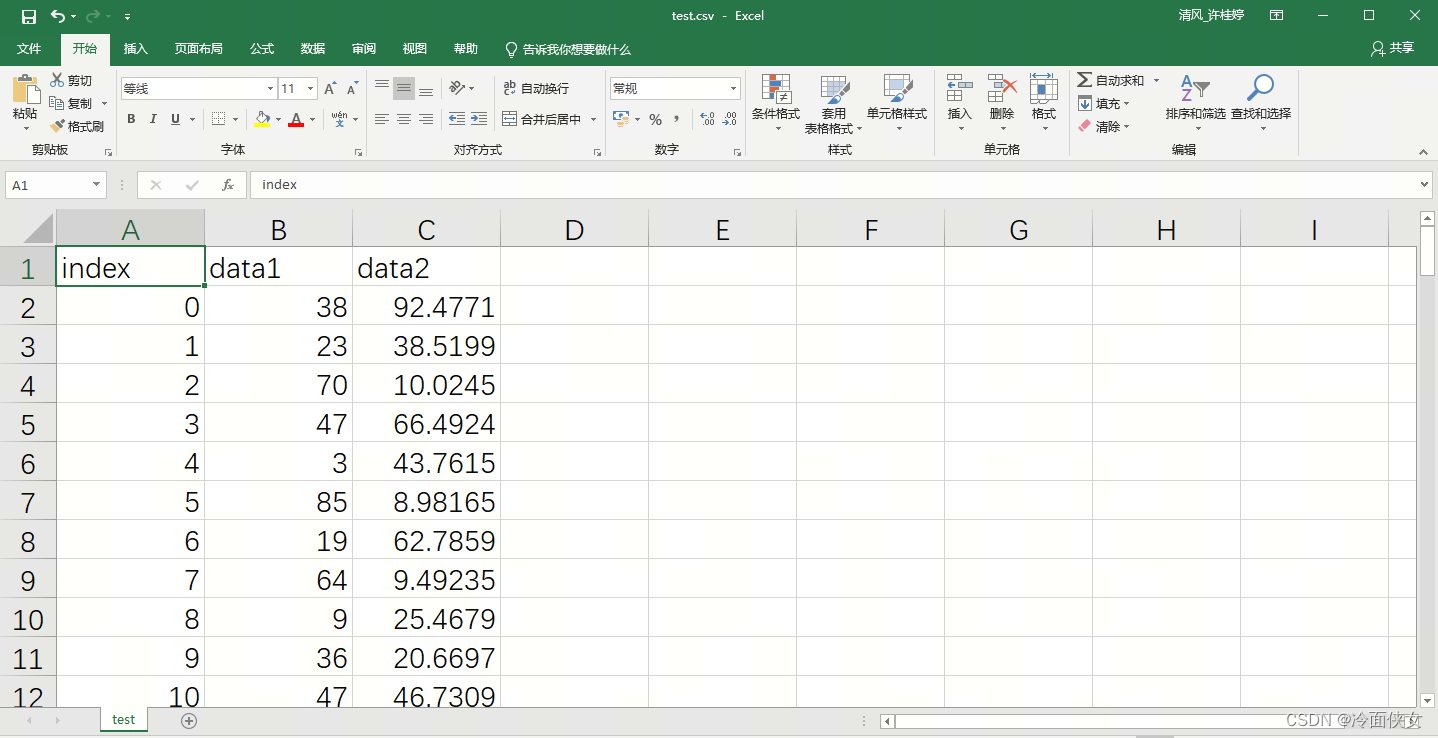
}exe同级文件夹下生成test.csv,内容如下:
- 控制向文件中写入浮点数的格式
如果想控制文件中浮点数的输出格式,需要借助<iomanip>头文件中的I/O 操控器。
示例:
double num = 123.456789;1、固定的小数点格式
使用 std::fixed 和 std::setprecision(n) 可以将浮点数设置为具有固定的小数点位置,并显示 n 位小数。
outFile << std::fixed << std::setprecision(2) << num << std::endl;2、科学计数法,保留四位小数
outFile << std::scientific << std::setprecision(4) << num << std::endl;3、固定宽度为10,固定的小数点格式,保留三位小数
outFile << std::setw(10) << std::fixed << std::setprecision(3) << num << std::endl;- 常用I/O操控器
1. setprecision(n)
• 为浮点数输出设置精度。当与 fixed 或 scientific 一起使用时,它表示小数点后的位数。否则,它表示最大的有效数字。
2. setw(n)
• 设置下一个输出字段的宽度。
3. fixed
• 使用固定的小数点格式显示浮点数。
4. scientific
• 使用科学记数法格式显示浮点数。
5. left
• 设置输出对齐为左对齐。
6. right
• 设置输出对齐为右对齐(这是默认的)。
7. internal
• 使填充字符位于符号和数字之间。
8. setfill(char)
• 用指定的字符填充宽度。
9. resetiosflags(flag)
• 重置指定的 I/O 标志。
10. setiosflags(flag)
• 设置指定的 I/O 标志。
11. boolalpha
• 输出布尔值为 “true” 或 “false”,而不是 “1” 或 “0”。
12. noboolalpha
• 取消 boolalpha 的效果。
13. showbase
• 显示数字的基数前缀。例如,对于十六进制数,显示 “0x”。
14. noshowbase
• 取消 showbase 的效果。
15. showpoint
• 总是显示浮点数小数点及其之后的数字。
16. noshowpoint
• 取消 showpoint 的效果
17. showpos
• 显示正数前的 ‘+’ 符号。
18. noshowpos
• 取消 showpos 的效果。
19. uppercase
• 以大写形式显示科学计数法中的 ‘E’ 和十六进制数的字母。
20. nouppercase
• 取消 uppercase 的效果。
读CSV文件
目标是从上面存储的test.csv文件中读取某一列,例如data1的数据到某个数组中。首先介绍一些需要使用到的库函数:
FILE *fopen(const char *filename, const char *mode)
【描述】
使用给定的模式 mode 打开 filename 所指向的文件
【参数】
- filename -- 字符串,表示要打开的文件名称。
- mode -- 字符串,表示文件的访问模式,可以是以下表格中的值:
模式 描述 "r" 打开一个用于读取的文件。该文件必须存在。 "w" 创建一个用于写入的空文件。如果文件名称与已存在的文件相同,则会删除已有文件的内容,文件被视为一个新的空文件。 "a" 追加到一个文件。写操作向文件末尾追加数据。如果文件不存在,则创建文件。 "r+" 打开一个用于更新的文件,可读取也可写入。该文件必须存在。 "w+" 创建一个用于读写的空文件。 "a+" 打开一个用于读取和追加的文件。 【返回值】
该函数返回一个 FILE 指针。否则返回 NULL,且设置全局变量 errno 来标识错误。
int feof(FILE *stream)
【描述】
测试给定流 stream 的文件结束标识符。
【参数】
stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
【返回值】
当设置了与流关联的文件结束标识符时,该函数返回一个非零值,否则返回零。
char *fgets(char *str, int n, FILE *stream)
【描述】
从指定的流 stream 读取一行,并把它存储在 str 所指向的字符串内。当读取 (n-1) 个字符时,或者读取到换行符时,或者到达文件末尾时,它会停止,具体视情况而定。
【参数】
str -- 这是指向一个字符数组的指针,该数组存储了要读取的字符串。
n -- 这是要读取的最大字符数(包括最后的空字符)。通常是使用以 str 传递的数组长度。
stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了要从中读取字符的流。
【返回值】
如果成功,该函数返回相同的 str 参数。如果到达文件末尾或者没有读取到任何字符, str 的内容保持不变,并返回一个空指针。如果发生错误,返回一个空指针。
int fseek(FILE *stream, long int offset, int whence)
【描述】
设置流 stream 的文件位置为给定的偏移 offset,参数 offset 意味着从给定的 whence 位置查找的字节数
【参数】
stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
offset -- 这是相对 whence 的偏移量,以字节为单位。
whence -- 这是表示开始添加偏移 offset 的位置。它一般指定为下列常量之一:
常量 描述 SEEK_SET 文件的开头 SEEK_CUR 文件指针的当前位置 SEEK_END 文件的末尾 【返回值】
如果成功,则该函数返回零,否则返回非零值。
int sscanf(const char *str, const char *format, ...)
在fileoperate.h中增加一个结构体声明如下,该结构体用来记录数组的长度、数组中存取数据的类型以及数组本身。
enum ARRAY_DATA_TYPE {
TYPE_U8,
TYPE_FLOAT
};
typedef struct {
ARRAY_DATA_TYPE data_type;
unsigned int data_len;
void* p_data;
}DATA_ARRAY_TYPE_S;函数实现如下:
bool read_csv_data(const char* p_tile, DATA_ARRAY_TYPE_S* p_data, const char* p_save_path)
{//从p_save_path的csv文件中,将p_tile列的数据记录到p_data的数组中
bool ret = false;
char line_str[512] = { 0 };
bool findFlag = false;
unsigned char dataColumn = 0;//记录p_tile列的索引
unsigned int dataLen = 0; //记录整个文件有多少行
unsigned int dataLen_tmp = 0;//记录p_tile列有多少行
unsigned int index = 0;
int scanf_n = 0;
int data_tmp = 0;
char* line_str_arr[40] = { 0 };
if ((p_tile == nullptr) || (p_data == nullptr) || (p_save_path == nullptr)) {
return false;
}
FILE* fp = fopen(p_save_path, "r");
if (fp == nullptr) {
return false;
}
//获取整个文件的行数
while (!feof(fp)) {//判断文件是否结束,是返回非0,否返回0
fgets(line_str, 512, fp);
dataLen++;
}
if (dataLen <= 3)
return false;
p_data->data_len = dataLen;
//为p_data的数组申请内存
dataLen_tmp = 0;
if ((p_data->data_type == TYPE_U8)) {
p_data->p_data = malloc(sizeof(unsigned char) * dataLen);
dataLen_tmp = sizeof(unsigned char) * dataLen;
}
else {
p_data->p_data = malloc(sizeof(float) * dataLen);
dataLen_tmp = sizeof(float) * dataLen;
}
if (p_data->p_data == nullptr)
return false;
//p_data初始化
memset(p_data->p_data, 0, dataLen_tmp);
//读取位置移至文件开头
fseek(fp, 0, SEEK_SET);
//读取标题行
memset(line_str, 0, 512);
fgets(line_str, 512, fp);
memset(line_str_arr, 0, sizeof(char*) * 40);
char* str1 = strtok(line_str, ",");
if (str1 != nullptr) {
line_str_arr[0] = str1;
for (int i = 1; i < 40; i++) {
str1 = strtok(nullptr, ",");
if (str1 == nullptr)
break;
line_str_arr[i] = str1;
}
}
else {
goto read_csv_data_exit;
}
//找到p_tile所在列
findFlag = false;
dataColumn = 0;
for (int i = 0; i < 40; i++) {
if ((line_str_arr[i] != nullptr) && (!memcmp(p_tile, line_str_arr[i], strlen((char*)p_tile)))) {
findFlag = true;
dataColumn = i;
}
}
if (findFlag == false) {
goto read_csv_data_exit;
}
index = 0;
for (int i = 0; (i < p_data->data_len) && (!feof(fp)); i++) {
memset(line_str, 0, 512);
fgets(line_str, 512, fp);
memset(line_str_arr, 0, sizeof(char*) * 40);
if (strlen(line_str) == 0)
continue;
char* str1 = strtok(line_str, ",");
if (str1 != nullptr) {
line_str_arr[0] = str1;
for (int j = 1; j < 40; j++) {
str1 = strtok(nullptr, ",");
if (str1 == nullptr)
break;
line_str_arr[j] = str1;
}
}
else {
continue;
}
if (line_str_arr[dataColumn] == nullptr) {
goto read_csv_data_exit;
}
data_tmp = 0;
if (p_data->data_type == TYPE_U8) {
scanf_n = sscanf(line_str_arr[dataColumn], "%d", &data_tmp);
((unsigned char*)(p_data->p_data))[index] = data_tmp;
}
else {
scanf_n = sscanf(line_str_arr[dataColumn], "%f", &((float*)(p_data->p_data))[index]);
}
if (scanf_n == 1) {
index++;
}
}
p_data->data_len = index;
if (p_data->data_len == 0) {
goto read_csv_data_exit;
}
ret = true;
read_csv_data_exit:
fclose(fp);
if (ret == false) {
free(p_data->p_data);
p_data->p_data = nullptr;
p_data->data_len = 0;
}
return true;
}
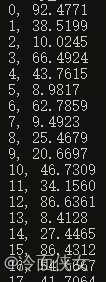
void test_for_read_csv() {
DATA_ARRAY_TYPE_S csv_data = { TYPE_FLOAT, 0, nullptr};
read_csv_data("data2", &csv_data, "test.csv");
for (int i = 0; i < csv_data.data_len; i++) {
printf("%d, %.4f\n", i, ((float*)(csv_data.p_data))[i]);
}
}















 1608
1608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









