






大家好,我是小年,我们都知道 「HashMap」 在 「JDK1.7」 的时候使用了「头插法」作为链表插入的方式,但是插入这种方式在多线程环境下会造成「死链问题」,但是其实 HashMap 在多线程环境下除了死链问题,还有在扩容的时候对象丢失问题,那么本期文章就带大家来看看HashMap是如何造成死链以及在 JDK1.8 中是如何解决死链的
死链问题
分析一个问题我们还是需要通过一个现象来看其本质,那么我们先来看看现象 造成死链的条件无非就两个,一个是在多线程环境下,二个是在扩容的时候
那其实我们在复现这个问题的时候,只要满足这两个条件就可以了,我这边准备了一段代码
public class HashMapDevil {
private static HashMap<Long, Socket> hashMap = new HashMap<Long,Socket>();
public static void main(String[] args) {
for (int i = 0 ; i < 100000 ; i++){
(new Thread(){
@Override
public void run() {
hashMap.put(System.nanoTime(),new Socket());
}
}).start();
System.out.println("========创建第"+i+"个线程");
}
}
}
我这里有一个 Socket 对象,然后我循环创建了十万个线程,这是十万个线程都在做同一个事情,那就是往同一个 Map 里面放这个 Socket 对象
当我们运行这个线程的时候会看到CPU突然飙升到了快200%了,其实这个时候死链已经造成了

这里注意当你在复现这个问题的时候,「JDK的版本一定要是1.7」
当我们看到这个现象后,那么我再来分析一下造成这个问题的原因是啥
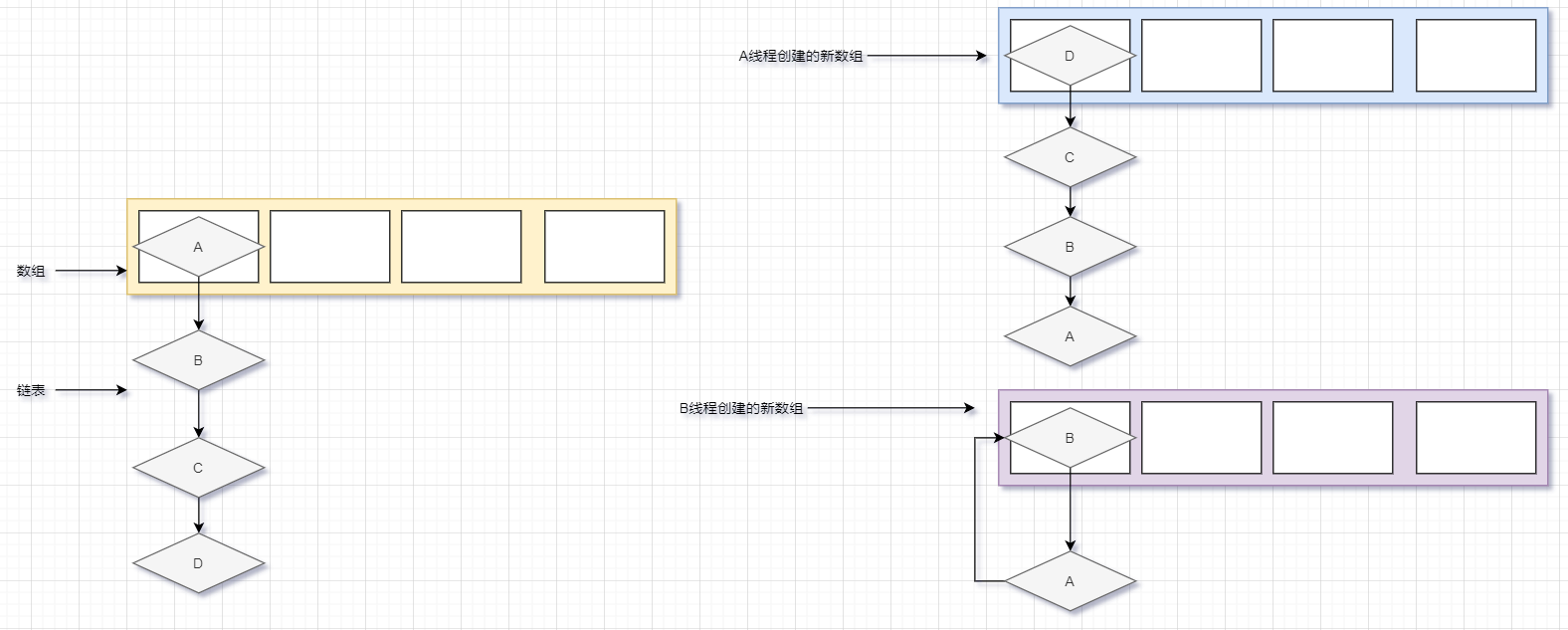
HashMap 在多线程环境下使用就避免不了操作同一个资源,而 HashMap 中的数组就是这些线程共享的资源
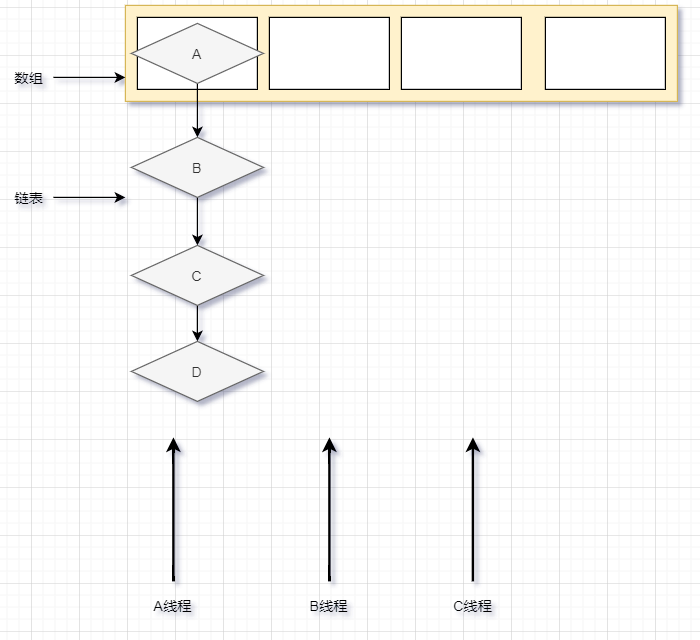
当A线程对这个数组进行扩容的时候,刚好 B 线程也在对这个数组进行扩容,而 A、B 两个线程在扩容的时候会同时创建两个新的数组,注意这两个数组的互不影响的
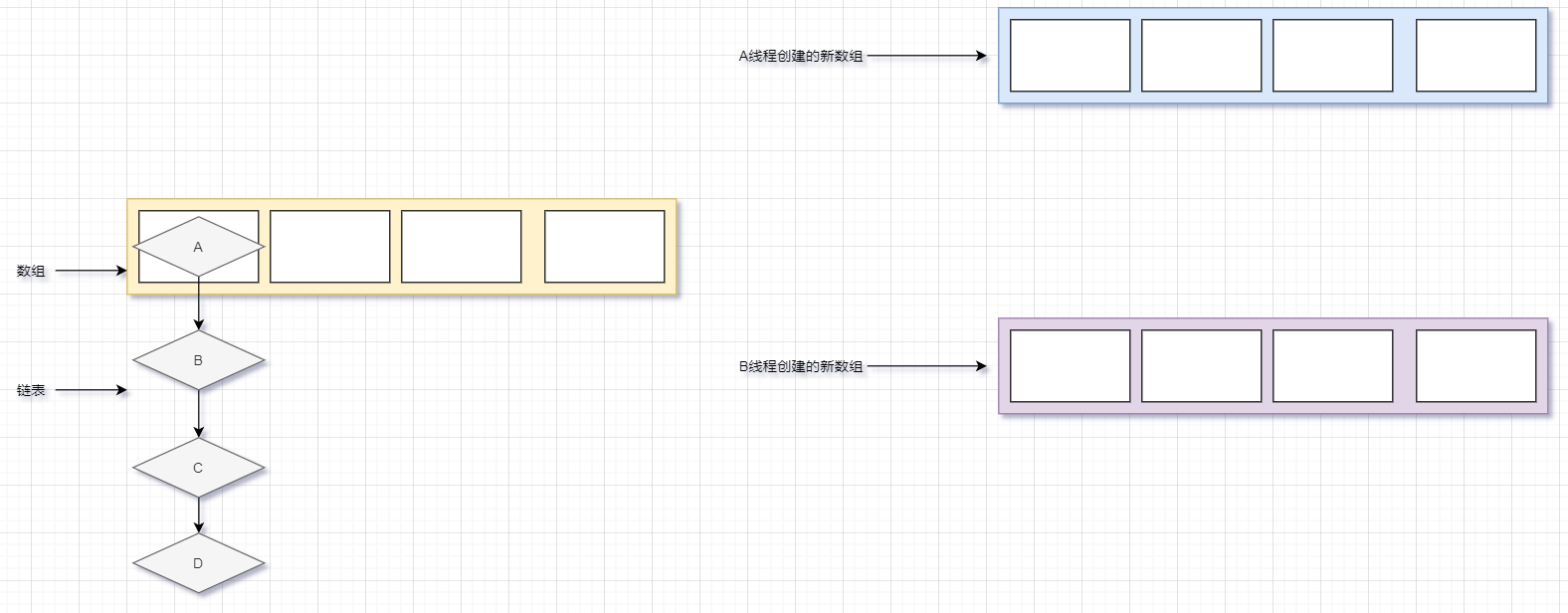
此时A线程率先在新数组中完成了链表的插入,B线程还在执行链表中其他节点的插入
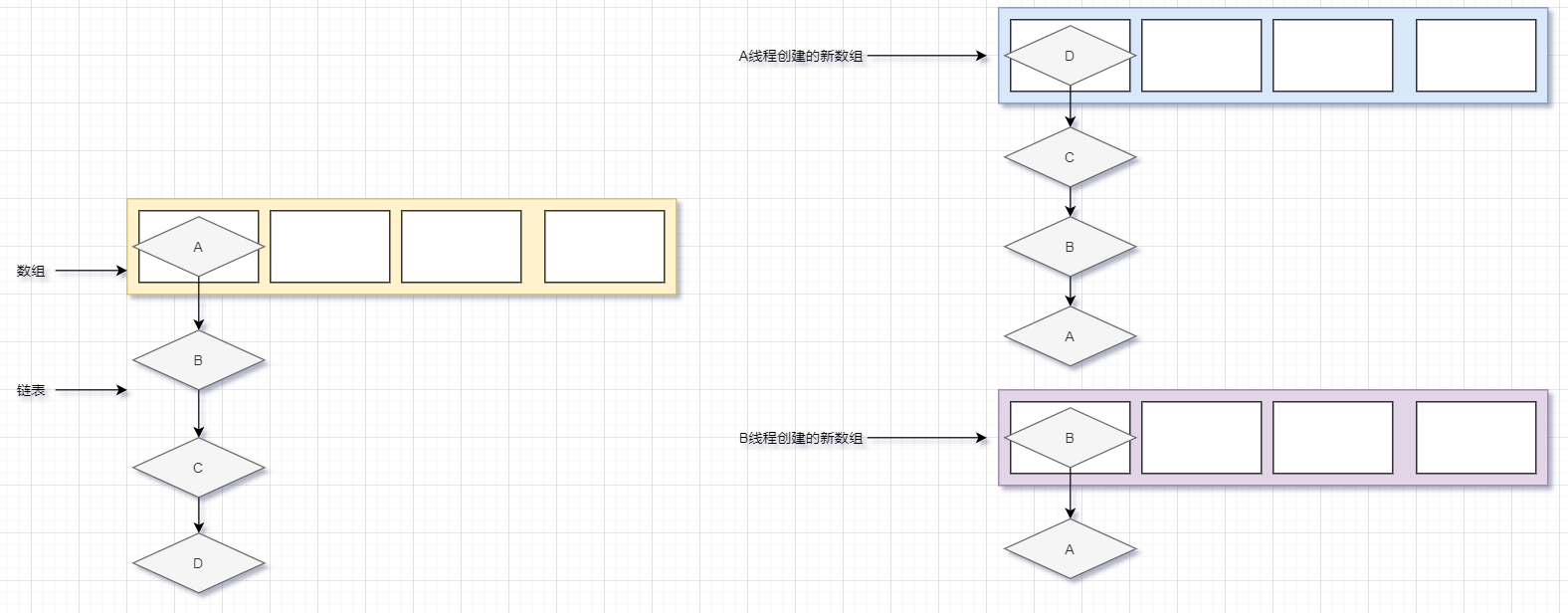
这里注意,关键点来了,因为B节点指针在原来的老数组中本来是指向 C 的,所以此时 B 线程下一个插入的元素本来是 C 节点的,但是因为 A 线程将 B 节点的指针改成了指向 A 节点,所以 B 线程的下一个插入的就是 A 节点,这时候如果 A 节点插入的话,那么 A 节点的指针就直接指向了 B 节点
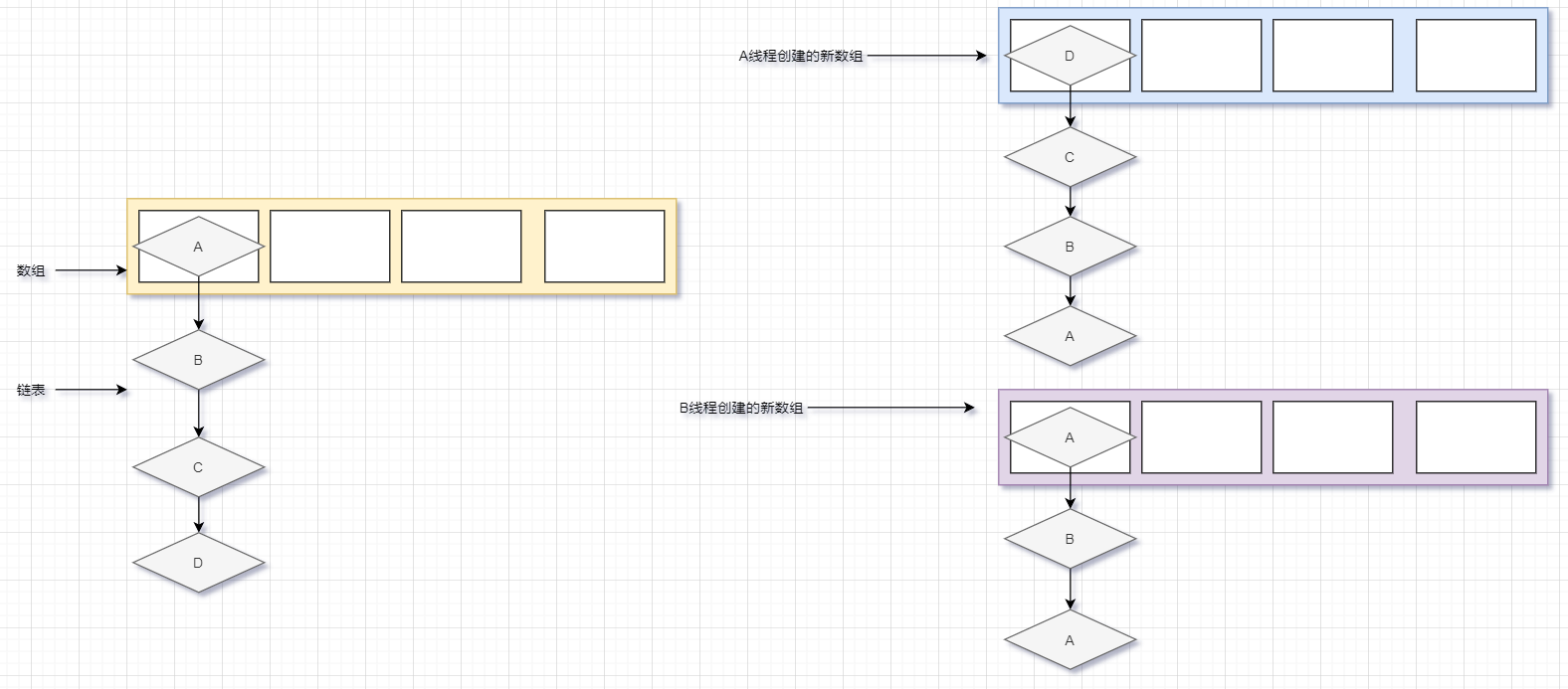
可以看到此时死链就形成了
在源码中,扩容其实是直接调用了resize方法
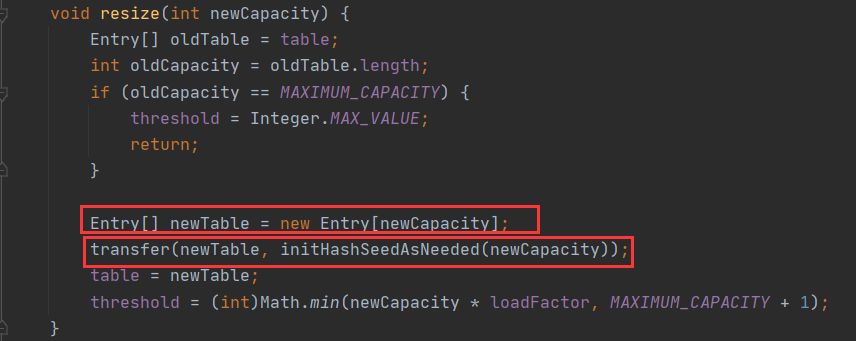
可以看到 resize 这个方法会去创建一个新的数组,当 A 、B 线程同时调用到这个方法的时候会去创建两个新的数组,而这个 transfer 方法就是造成死链的罪魁祸首,那么我们再来看看这个方法里面到底做了些什么事
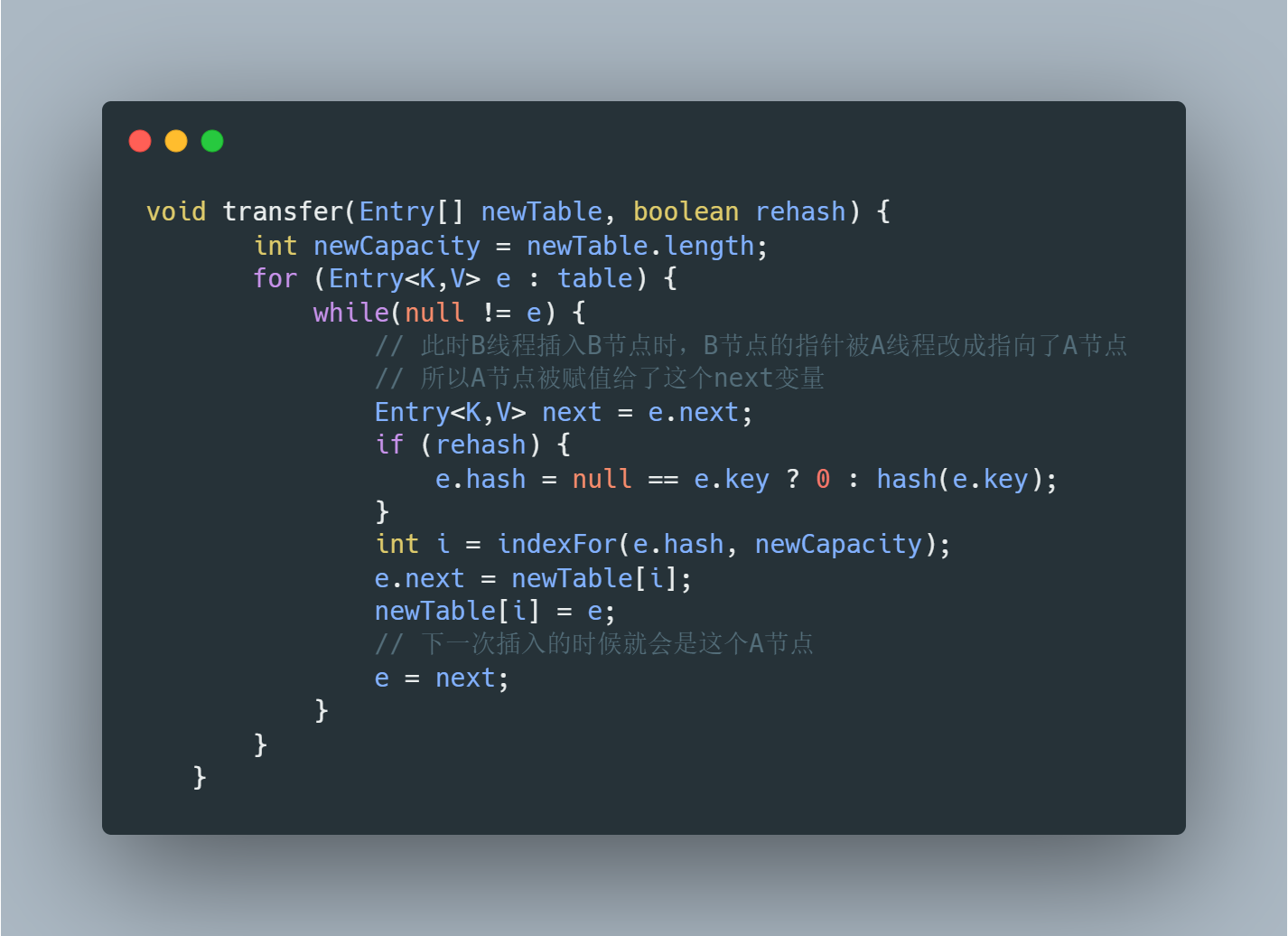
这段代码大致的意思是,先获取当前节点,然后把当前节点的下一个节点赋值给了 「next」 变量,赋完值后再把当前的节点指向新数组中索引所在的那个位置的节点 ,最后再将当前节点放到新数组索引所在的那个位置,其实这一个过程就是头插法的过程
造成死链的主要原因还是因为当某个线程去做链表插入的时候,另外的一个线程把链表节点「指针的指向」修改了,针对上面所画的图的关键点我也写在了注释里,大家可以对照这个注释和上面的图进行理解
搞清楚了死链原因之后,我们再来看看 JDK1.8 是如何解决死链问题的
首先 JDK1.8 将头插法改成了尾插法,保证了节点「指针的顺序」,然后再使用「高低位链表」的方式来辅助解决死链问题
高低位链表就是把数组分为高位和低位,在扩容的时候会用节点的hashCode与旧数组的长度进行取模得出一个值,然后再把节点放到这个值所对应的高低位区间
就举个很简单的例子,假如新数组扩容后长度是 16,那这个新数组会分为两个区间[0~7] 和[8~15],[0~7]为低位,[8~15]为高位,通过节点在旧数组中的hashCode与旧数组的长度取模来判断这个值是否落在高位
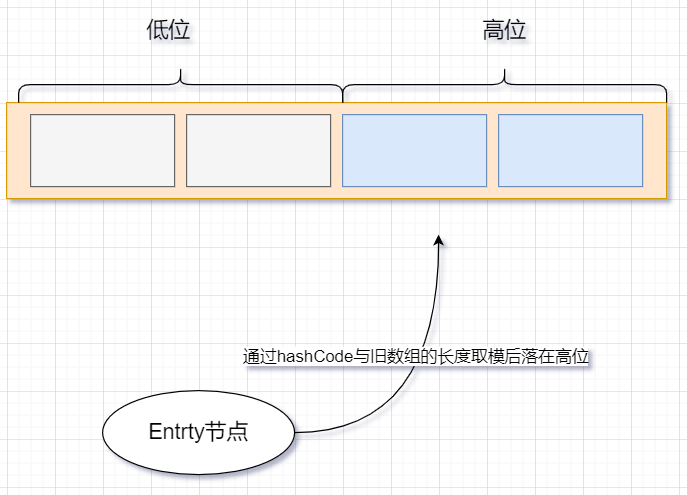
JDK1.8 在扩容的时候不再是一边循环遍历节点一边往新数组里面插入数据了,而且先循环遍历节点拉出一条高位链表和一条低位链表,然后再把这两条链表放到数组对应的位置
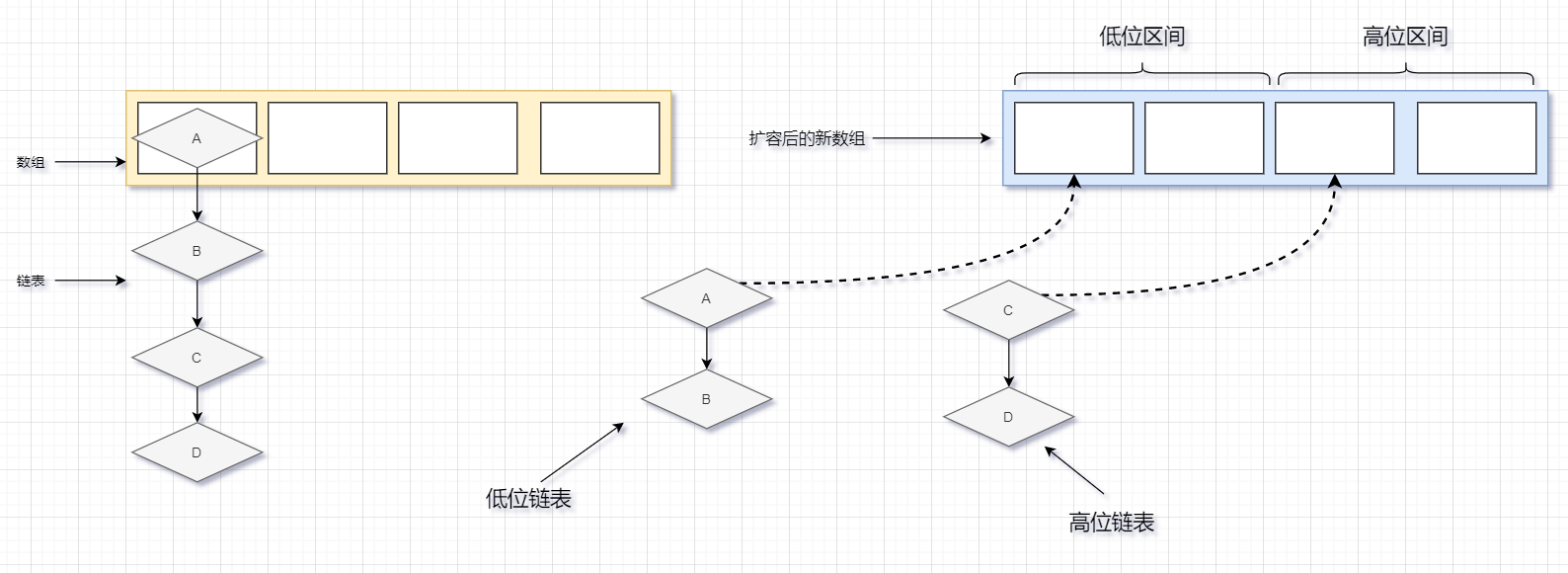
可以看到图中,A、B两个节点通过计算是落在低位区间,所以A和B两个节点会拉成一条低位链表,并且指针是按照顺序指向的,之后再将链表放到数组对应的位置,如果数组只有一个节点,那么它会被直接复制到新数组中对应的位置
知道 JDK1.8 是如何解决死链问题之后,我们再来看看源码
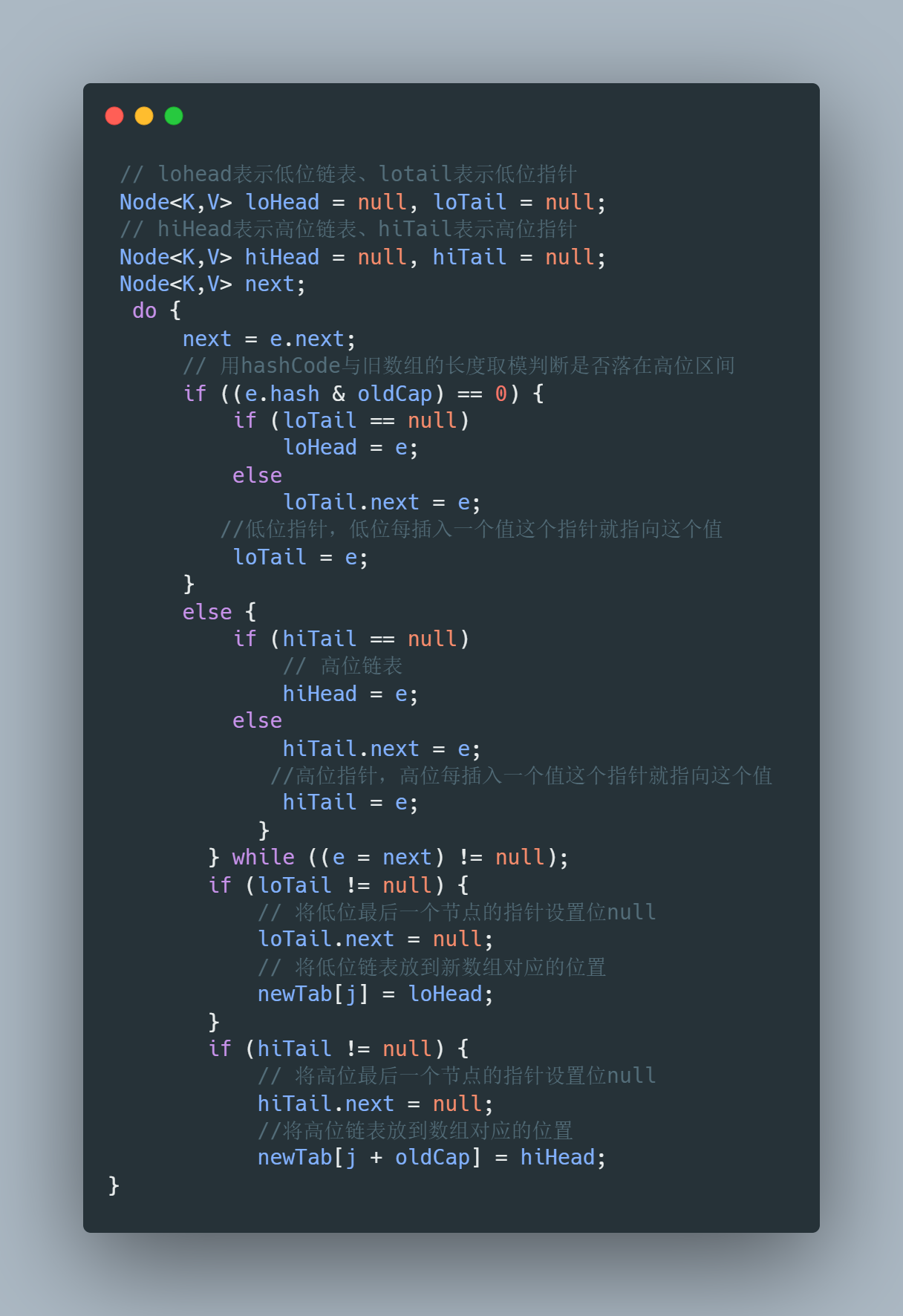
loHead、 hiHead分别对应低位链表、高位链表,loTail、hiTail分别对应低位指针、高位指针
网上有的也把 loTail 和 hiTail 归纳到高低位链表里,但是我更喜欢把它们归纳为高低位指针
为了方便大家能够更好的理解链表的形成,我用低位链表为例子来看看是怎么插入的

首先A节点通过计算后判断出应该放到低位链表中,那此时A节点会直接赋值给 lohead 变量,然后 loTail 指针直接指向A节点,再循环到B节点插入的时候,会通过这个指针找到A节点然后把A节点的指针指向B节点,之后 loTail指针会指向B节点,就这样一直到链表的最后一个节点,这样链表就完成了,最后就直接把链表放到了数组对应的位置
其实这里使用高低位链表除了辅助解决死链外,还有一个就是为了提高链表插入效率问题
对应关键的一些代码解释我也写在了上面代码中的注释里,大家可以结合代码以及我画的这幅图来理解
JDK1.8 虽然解决了死链问题,但是 HashMap 还有个重要的问题没有解决,那就是对象丢失,这又是怎么一回事呢,继续往下看
对象丢失
什么是对象丢失呢,就是有两个线程同时享有的资源,一个线程将另外一个线程设置的共享资源的对象信息覆盖了,从而造成了对象的丢失
我这边给大家举个例子吧
我们有 A 、B两个线程,A线程put了一个值--put("a","a线程"),在put值的时候发现需要扩容了,那么此时A线程会去调用resize方法进行扩容,我们知道在调用resize方法的时候会去创建一个新的数组,而这个新的数组是被一个局部变量引用着,恰好此时B线程也put了一个值--put("b","b线程"),因为a线程还没有扩容完,所以此时B线程也会去调用resize方法进行扩容并且创建一个新的数组被另外的一个局部变量给引用着
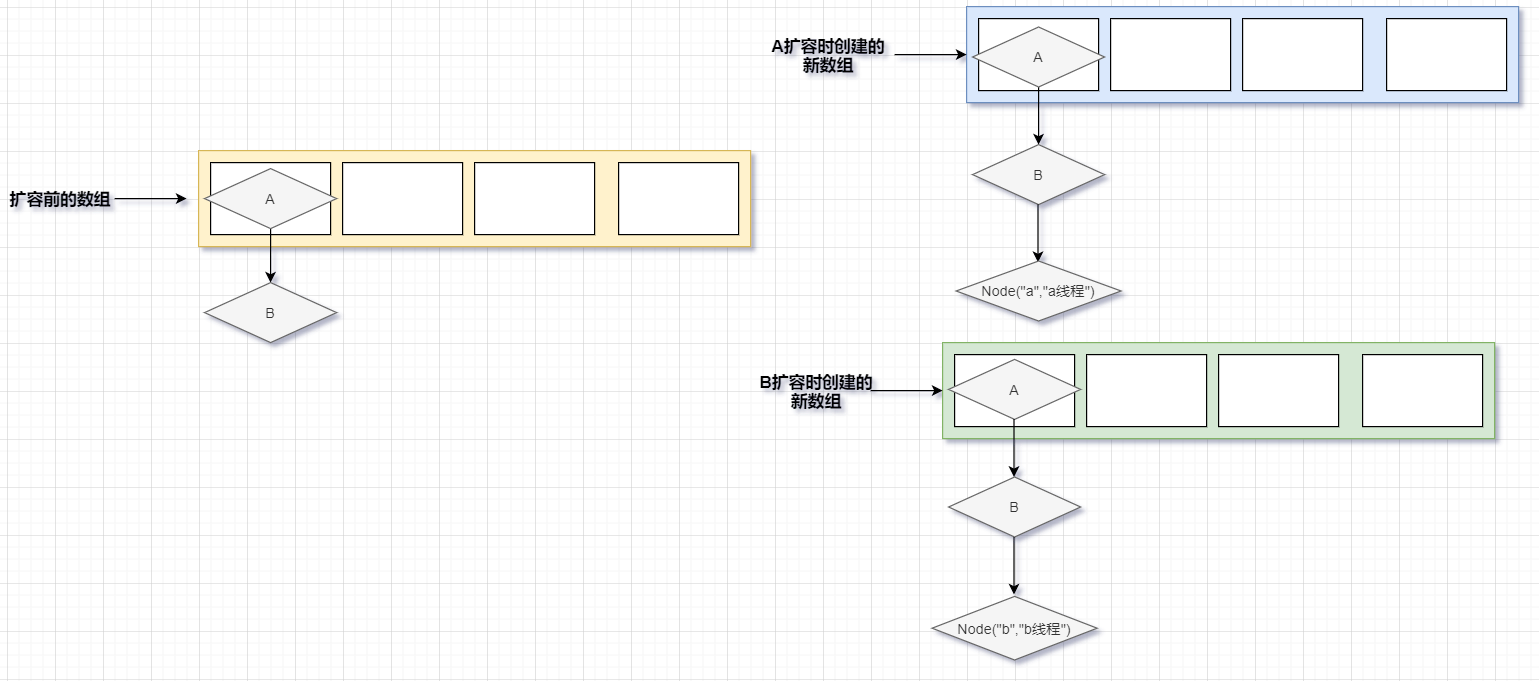
当A线程扩容完成之后,会把老的数组替换成新的数组,而此时的B线程还在扩容中
当B线程扩容完之后,也会进行替换,而这个替换就会把之前A创建数组给替换了
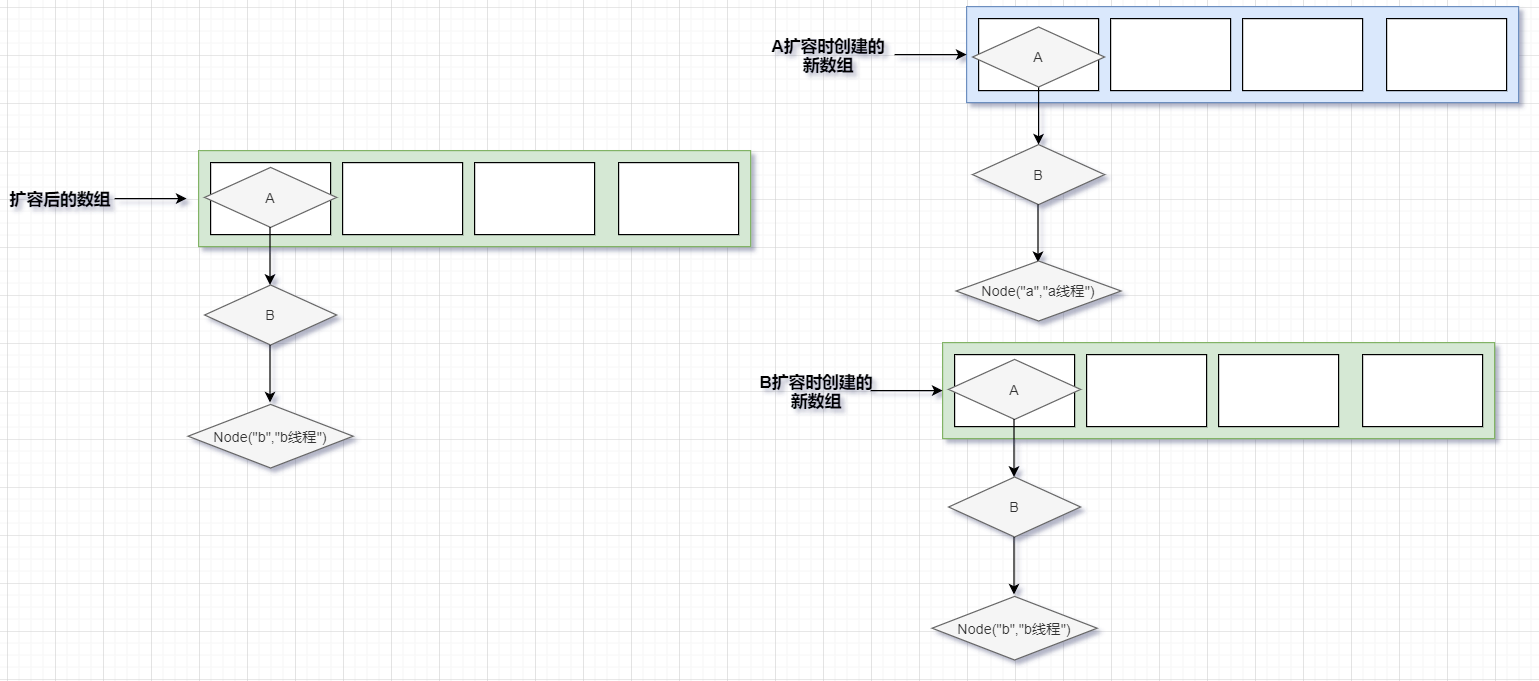
那这个替换问题就出来了,可以看到,当B线程把新创建的数组替换完之后,A线程put的那个值也就被覆盖了
那此时扩容后的数组就相当于丢失了A线程put的那个值
虽然 JDK1.8 解决了死链问题,但是对于对象丢失这个问题依然存在,所以我们在多线程环境下尽量的使用线程安全的Map类,如HashTable、ConcurrentHashMap等
总结
HashMap通过采用尾插法以及高低位拉链表来解决死链问题,尾插法保证了链表扩容后的节点是有序的,高低位链表很好的保证了链表插入的速度以及查询速度,尽管解决了死链问题,但是HashMap的对象丢失问题依然存在,我们在多线程环境下,尽量的使用线程安全的Map类
好了,本期文章就到这里了,如果喜欢的话,请留言点赞哦














 961
961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









