






摘要: 文章介绍了使用Kettle将数据导入到AnalyticDB for PostgreSQL,包括使用表输出方式(INSERT)和批量加载方式(COPY)导入到AnalyticDB for PostgreSQL的详细步骤和操作流程。
Kettle简介
Kettle(现也称为Pentaho Data Integration,简称PDI)是一款非常受欢迎的开源ETL工具软件,主要用于数据整合、转换和迁移。Kettle除了支持各种关系型数据库,HBase MongoDB这样的NoSQL数据源外,它还支持Excel、Access这类小型的数据源。并且通过这些插件扩展,kettle可以支持各类数据源。
下图显示了Kettle和ADB for PostgreSQL之间的关系,数据源通过Kettle进行ETL或数据集成操作以后可以和ADB for PostgreSQL进行交互:
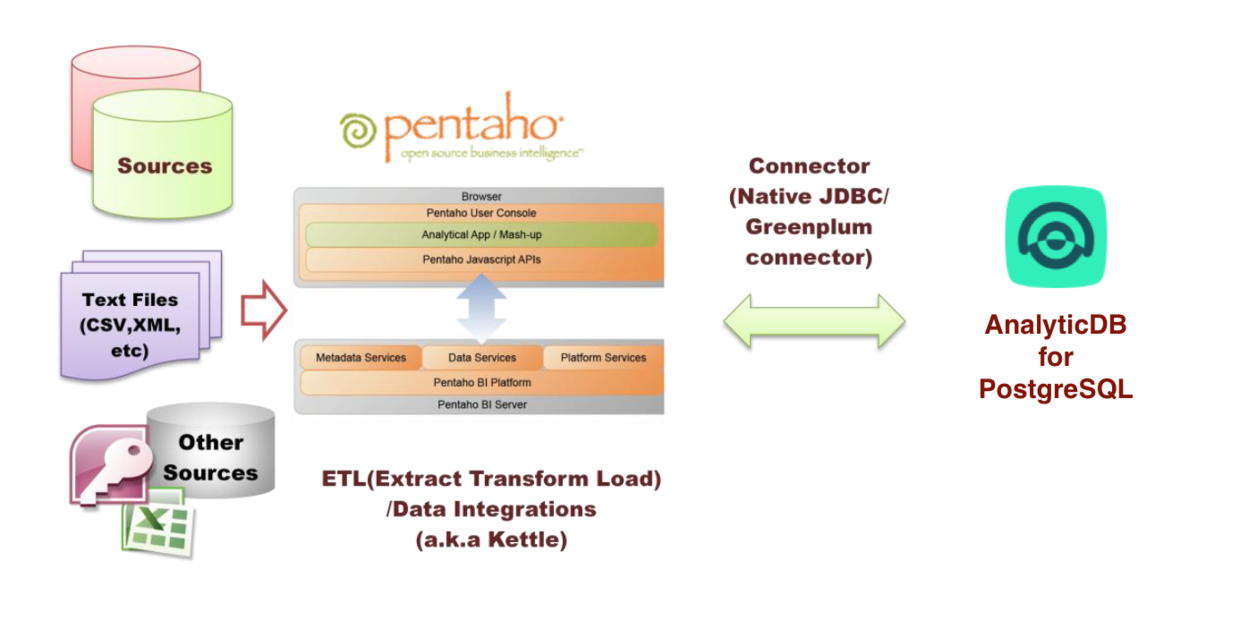
Kettle支持的数据来源非常丰富,主要包括以下分类:
表输入
文本文件输入
生成记录/自定义常量
获取系统信息
各类格式文件输入
Json输入
以及其他输入
更详细的输入可以从界面中的“核心对象”的“输入”分类中查看。
Kettle支持的表输入来源自数据库连接中使用SQL语句获取,其中数据库连接支持非常丰富的连接方式,包括:
Native(JDBC)连接
ODBC连接
OCI连接
JNDI连接
通过这些连接方式,可以支持连接大多数主流数据库,如Oracle, SQL Server, MySQL, DB2, PostgreSQL, Sybase, Teradata等等,更详细的连接信息可以参考官方文档:https://help.pentaho.com/Documentation/8.2/Setup/Configuration/Define_Data_Connections
Kettle导入到ADB for PostgreSQL
Kettle支持导入到ADB for PostgreSQL的方式
目前,Kettle支持的数据导入到ADB for PostgreSQL的方式有:
导入方式
说明
表输出
(INSERT方式)
采用JDBC作为导入方式 支持批量插入,批量插入使用JDBC的batch insert方法
批量加载
(COPY方式)
采用COPY作为导入方式 对于大表,COPY方式性能达到批量插入性能的10倍左右
表输出(INSERT方式)导入会流过Master节点并做解析之后分布到对应的Segment节点上,这种方式相对较慢并且不适合导入大量数据。批量加载(COPY方式)导入方式比INSERT语句插入多行的效率更高。
以下将分别介绍如何通过这两种方式将外部数据迁移到AnalyticDB for PostgresSQL。
准备工作
使用Kettle将外部数据导入AnalyticDB for PostgresSQL之前,需要完成以下准备工作。
在本地主机中安装kettle
在AnalyticDB for PostgreSQL中创建目标数据库、模式和表。
表输出方式导入数据到ADB for PostgreSQL
Kettle采用表输出方式,支持使用通用的JDBC接口,从各种数据库源导入到ADB for PostgreSQL中。以下就以MySQL为例说明如何通过JDBC接口导入数据到ADB for PostgreSQL中。
1.在Kettle中新建一个转换。
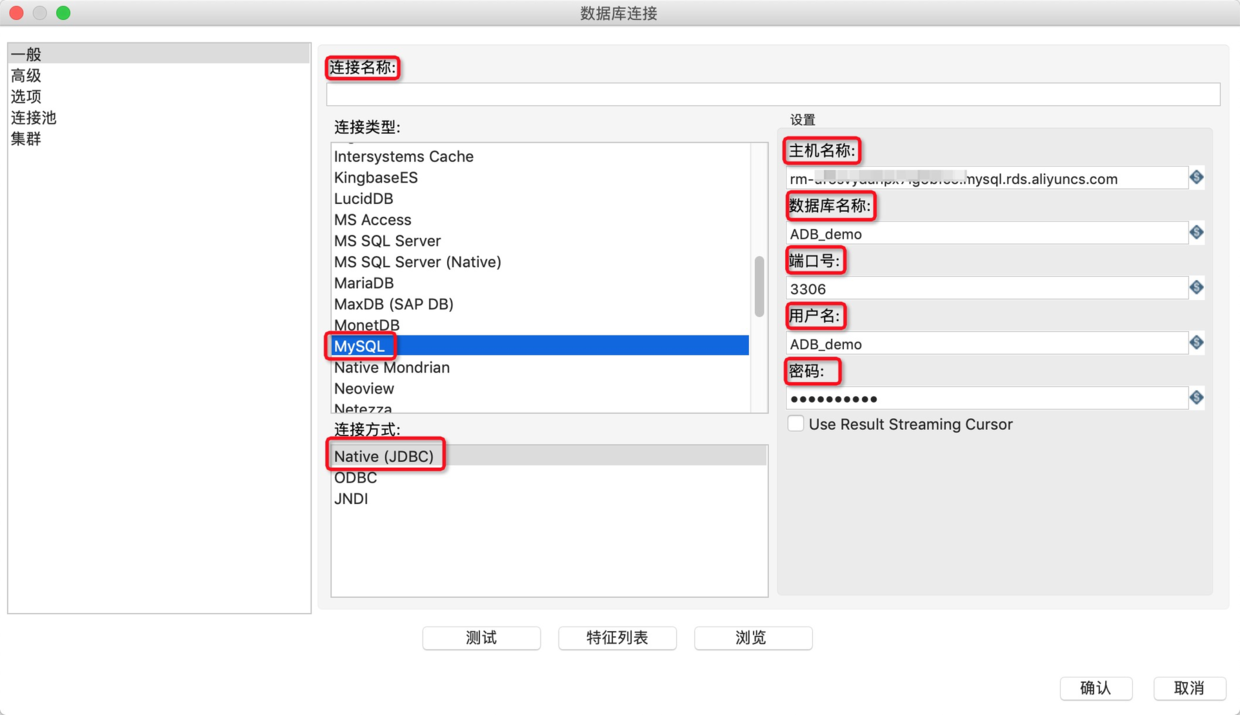
2.在转换中新建一个MySQL数据库连接作为输出源,详细的参数配置如下表所示。
配置参数时,不要勾选Use Result Streaming Cursor。
配置项
说明
连接名称
数据连名
连接类型
选择MySQL
连接方式
选择Native(JDBC)
主机名
MySQL的连接地址
数据库名称
MySQL的数据库名
端口号
连接地址对应的端口号
用户名
用户名
密码
用户密码
3.完成上述参数配置后,单击测试测试连通性,测试通过后单击确认。
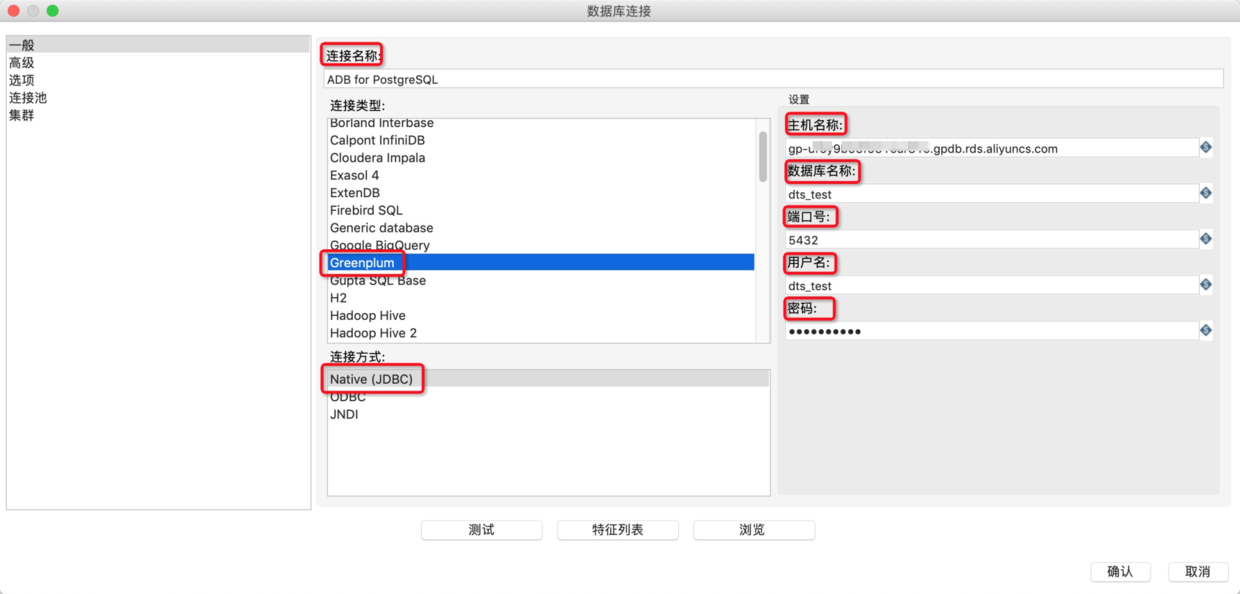
4.在转换中新建一个Greenplum数据库连接作为输入源,详细的参数配置如下表所示。
配置项
说明
连接名称
数据连名
连接类型
选择Greenplum
连接方式
选择Native(JDBC)
主机名
AnalyticDB for PostgreSQL的连接地址
数据库名称
AnalyticDB for PostgresSQL的数据库名
端口号
连接地址对应的端口号
用户名
用户名
密码
用户密码
5.完成上述参数配置后,单击测试测试连通性,测试通过后单击确认。
6.在kettle左侧核心对象的输入中,找到表输入,并将其拖动入到工作区。
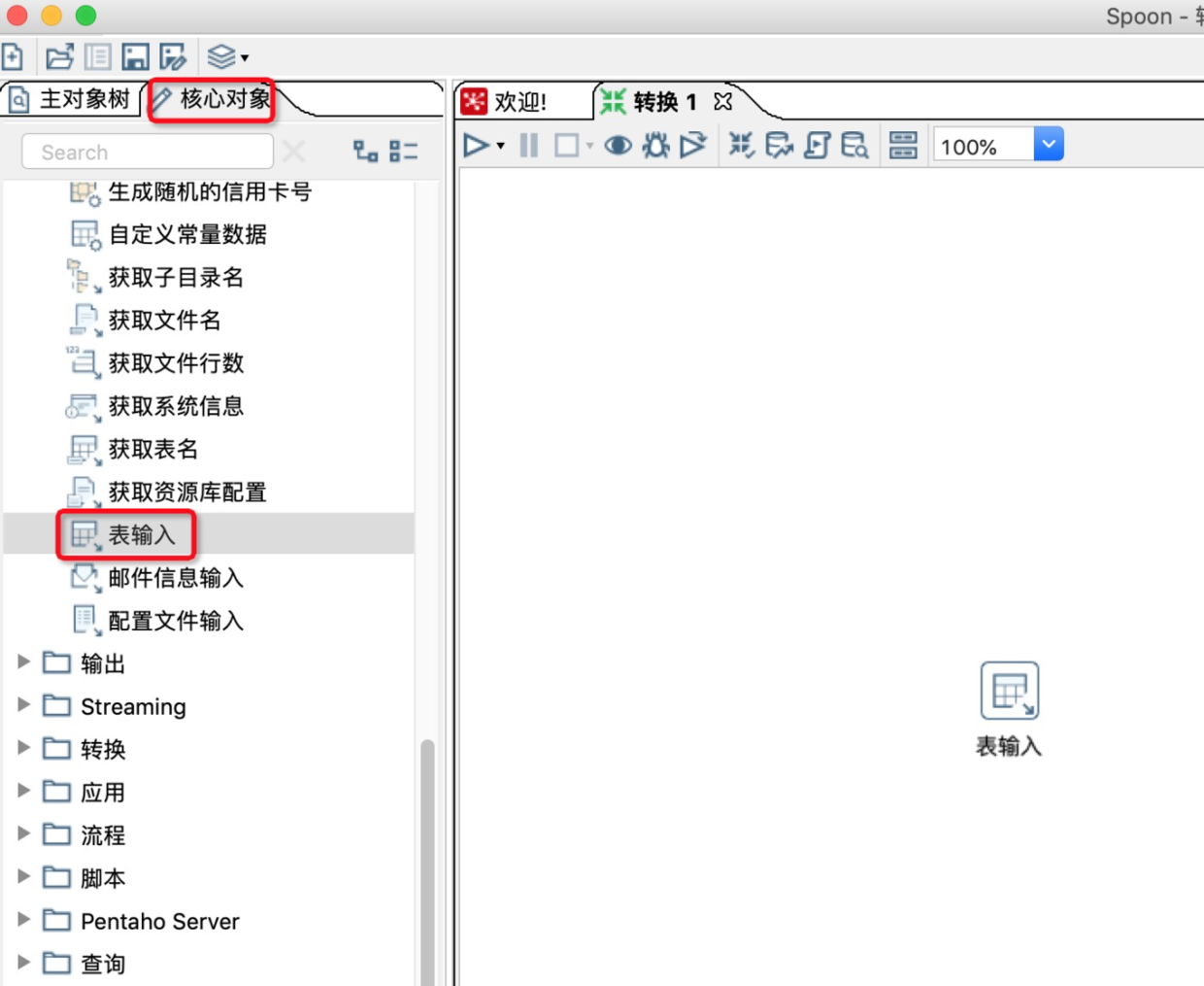
7.双击工作区的表输入,在表输入对话框中进行参数配置。
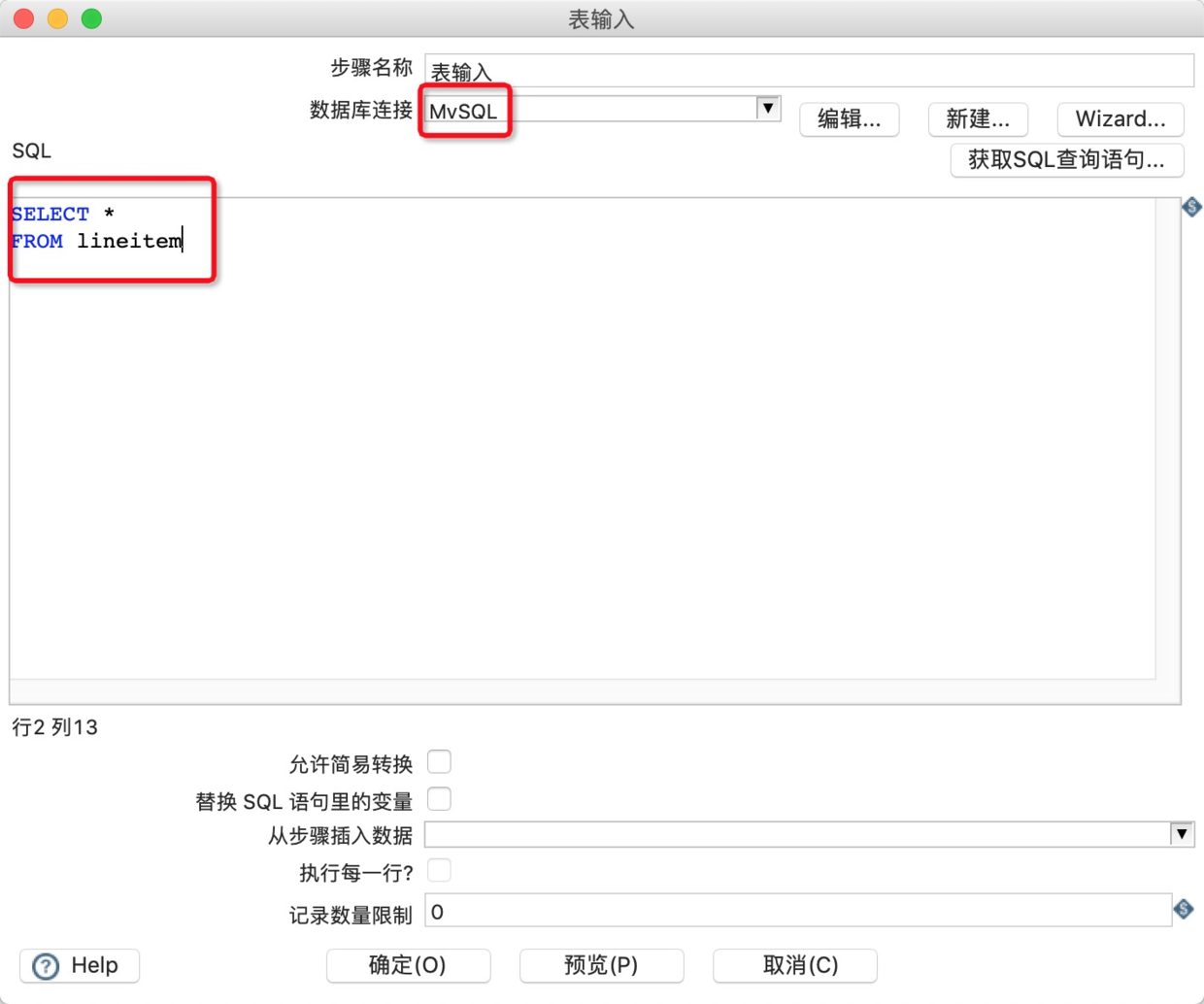
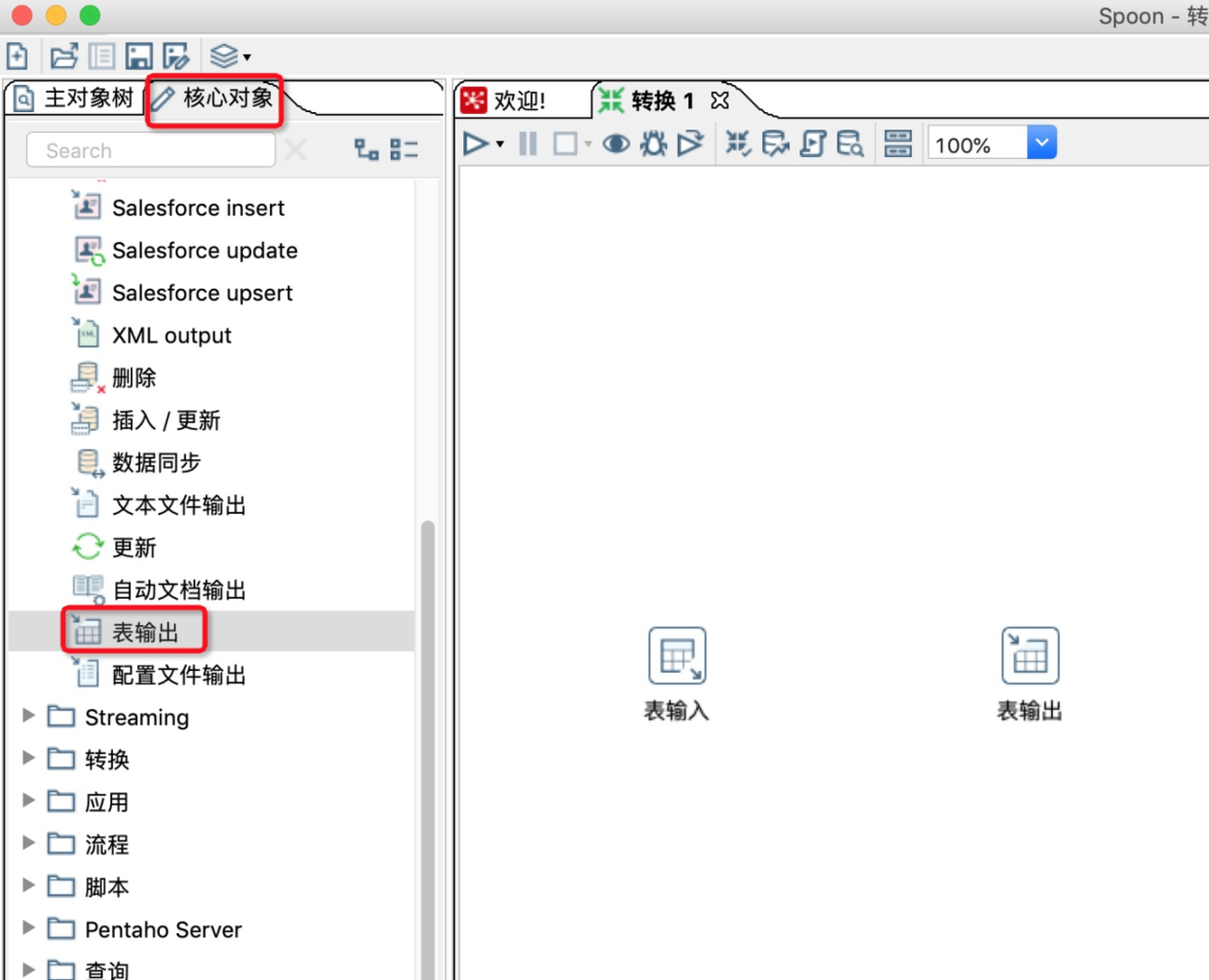
8.在Kettle左侧核心对象的输出中,找到表输出,并将其拖动入到工作区。
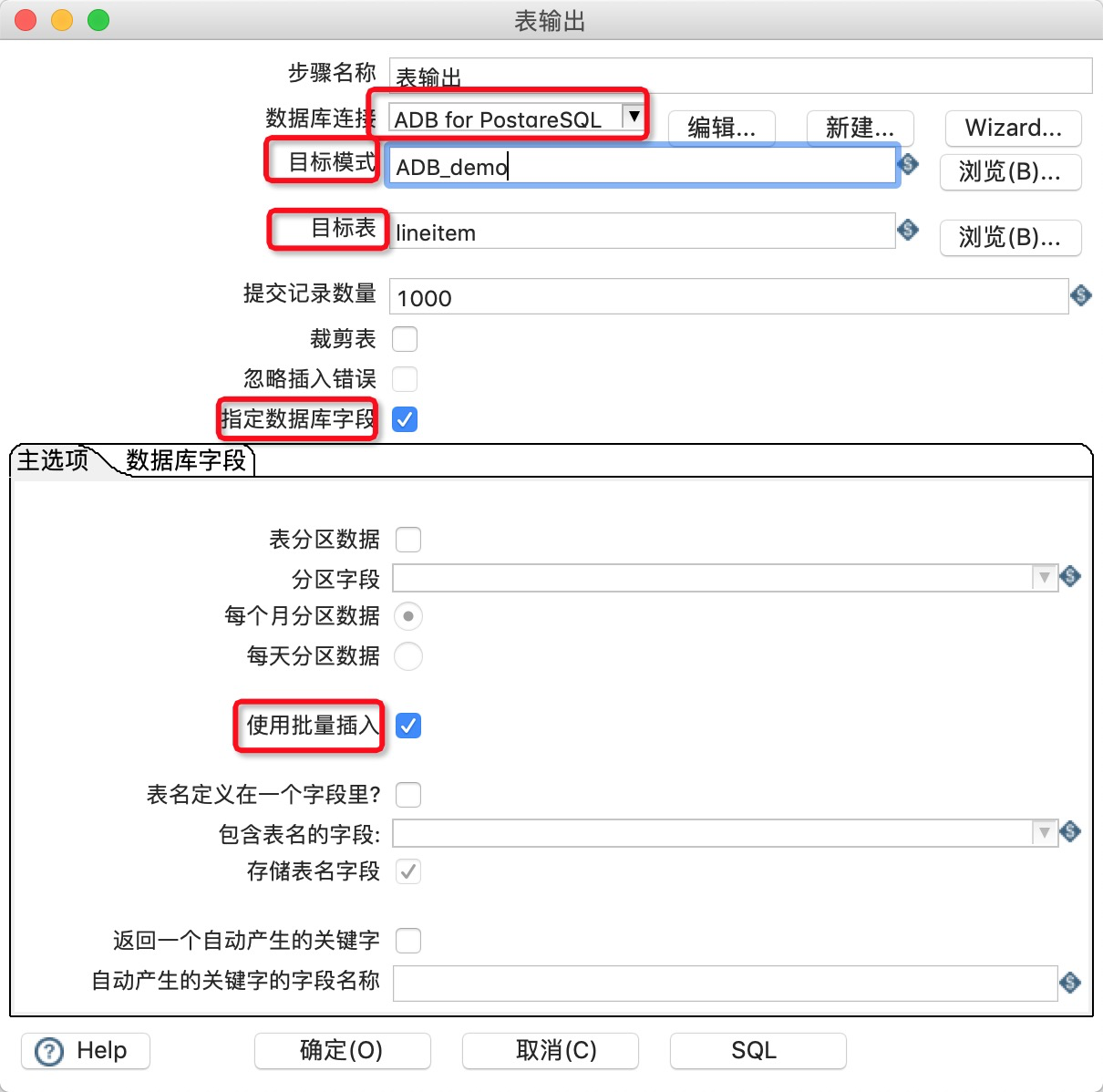
9.双击工作区的表输出,在表输出对话框中进行参数配置。
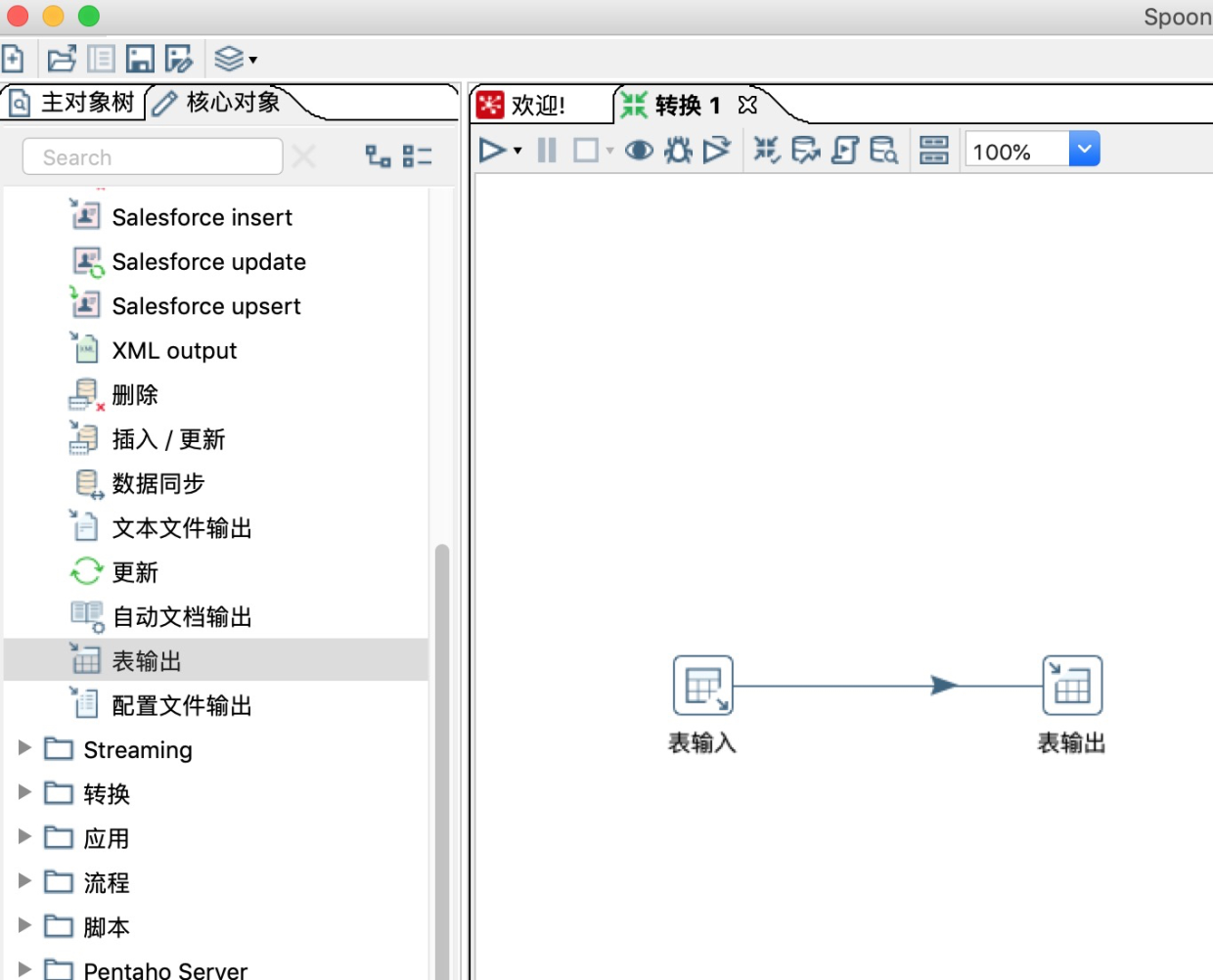
10.新建一条表输入到表输出的连接线。
11.单击白色三角箭头运行转换,观察运行日志和运行状态。
待MySQL数据成功导入AnalyticDB for PostgreSQL后,您就可以使用AnalyticDB for PostgreSQL进行数据分析。
批量加载方式导入数据到ADB for PostgreSQL
Kettle支持使用批量加载方式(COPY方式)导入数据到ADB for PostgreSQL中。下面步骤举例说明通过从外部文件中批量加载数据到ADB for PostgreSQL中。
1.在Kettle中新建一个转换。
2.在转换中新建一个文本文件输入作为输出源。
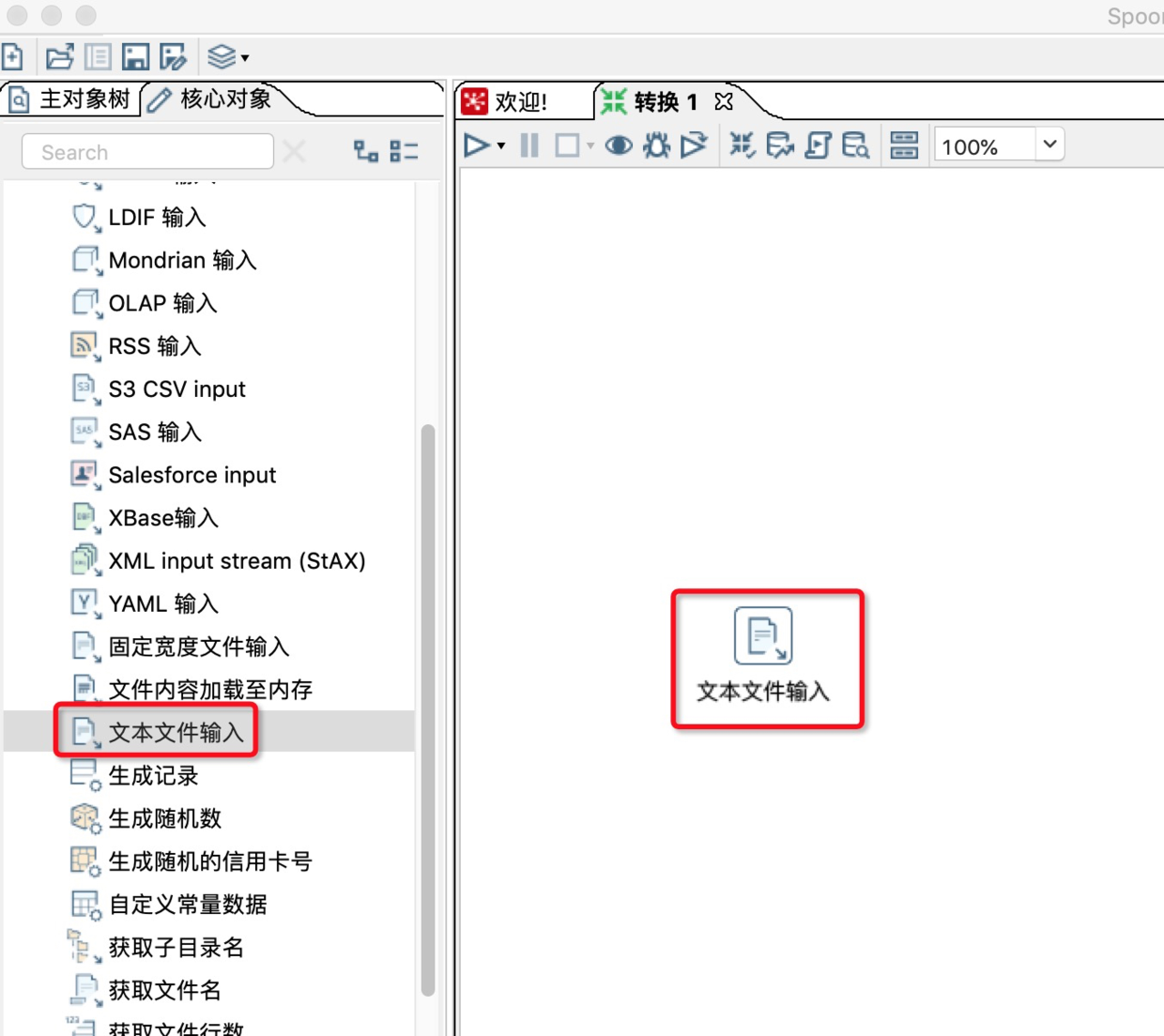
3.双击文本文件输入的图表,选择输入的文本文件。
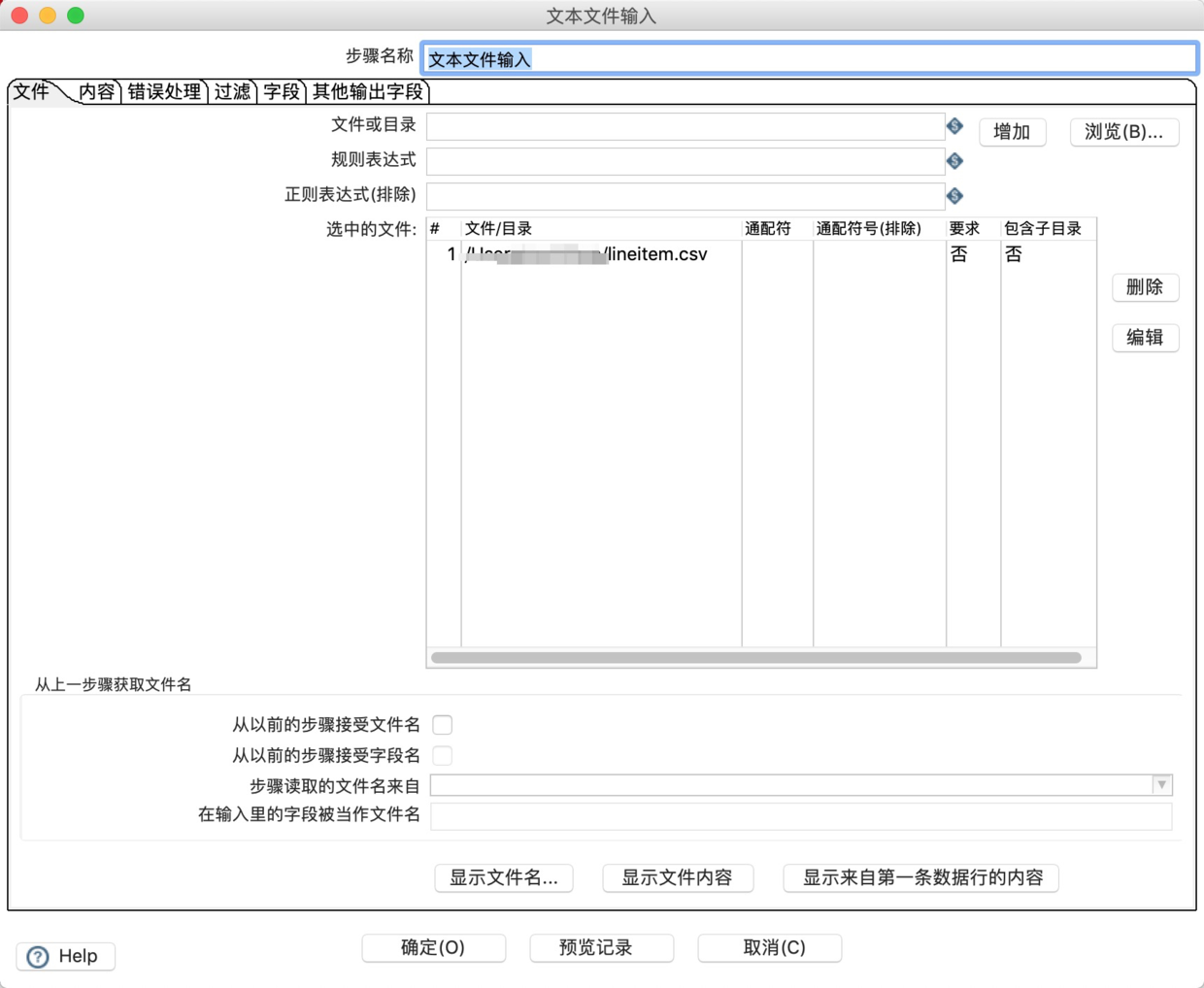
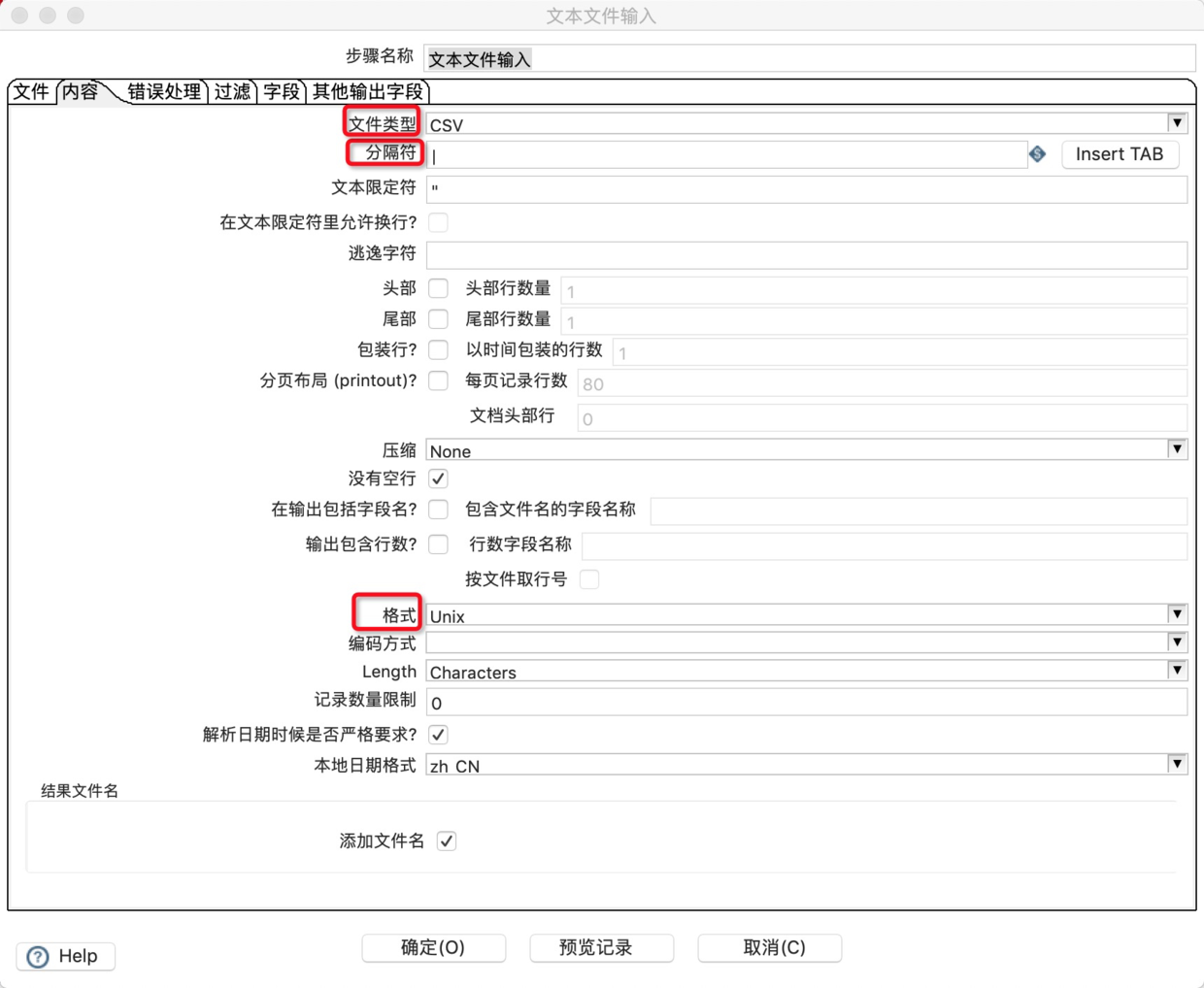
4.在“内容”选项卡中配置输入文件的分隔符。
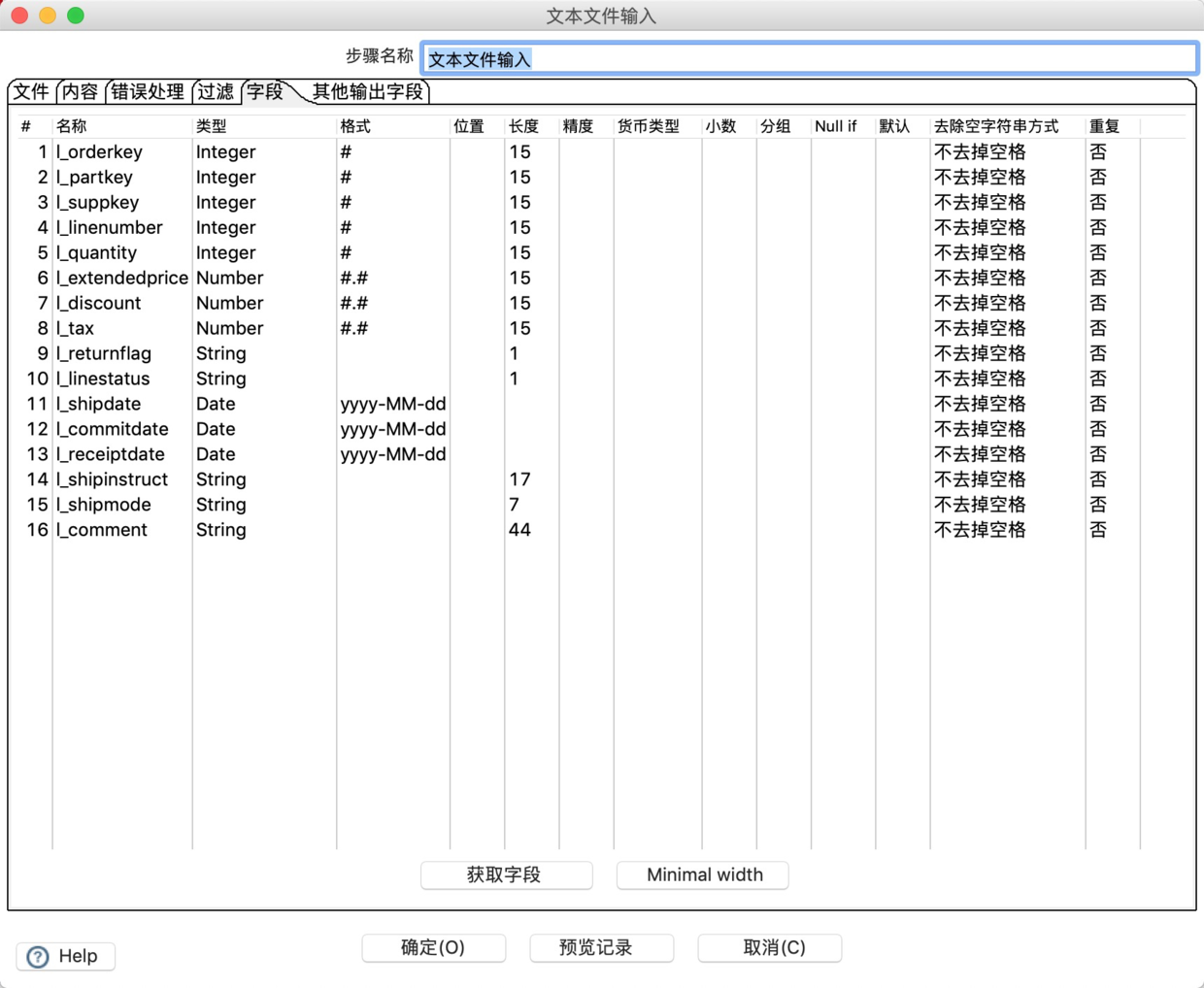
5.在“字段”选项卡定义输入文件表中的字段。
6.在转换中新建一个Greenplum数据库连接作为输入源,详细的参数配置如下表所示。
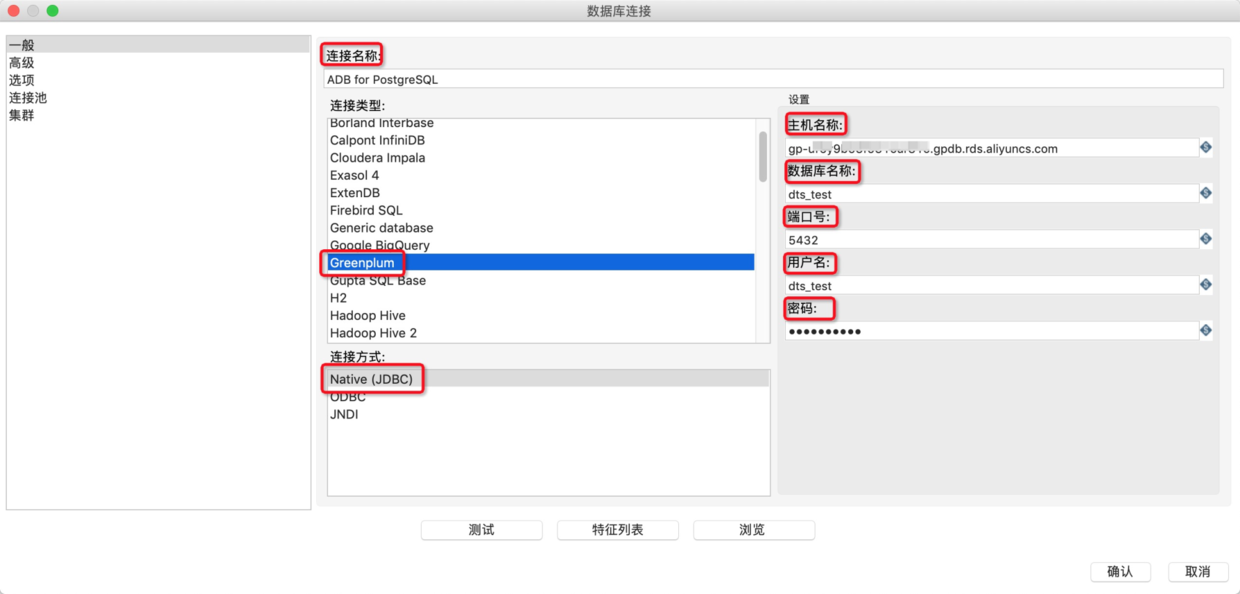
7.完成上述参数配置后,单击测试测试连通性,测试通过后单击确认。
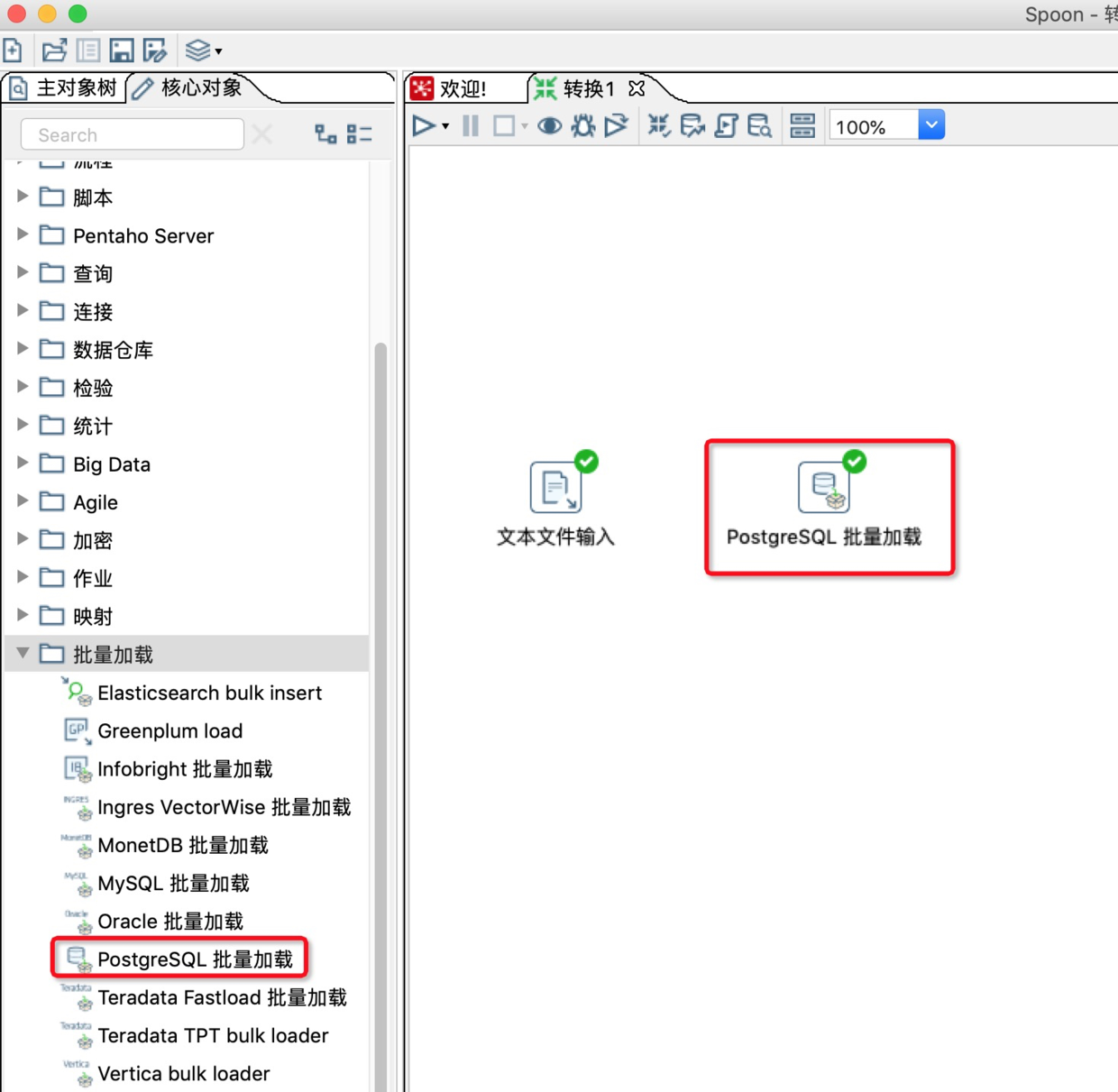
8.在Kettle左侧核心对象的批量加载中,找到PostgreSQL批量加载,并将其拖动入到工作区。
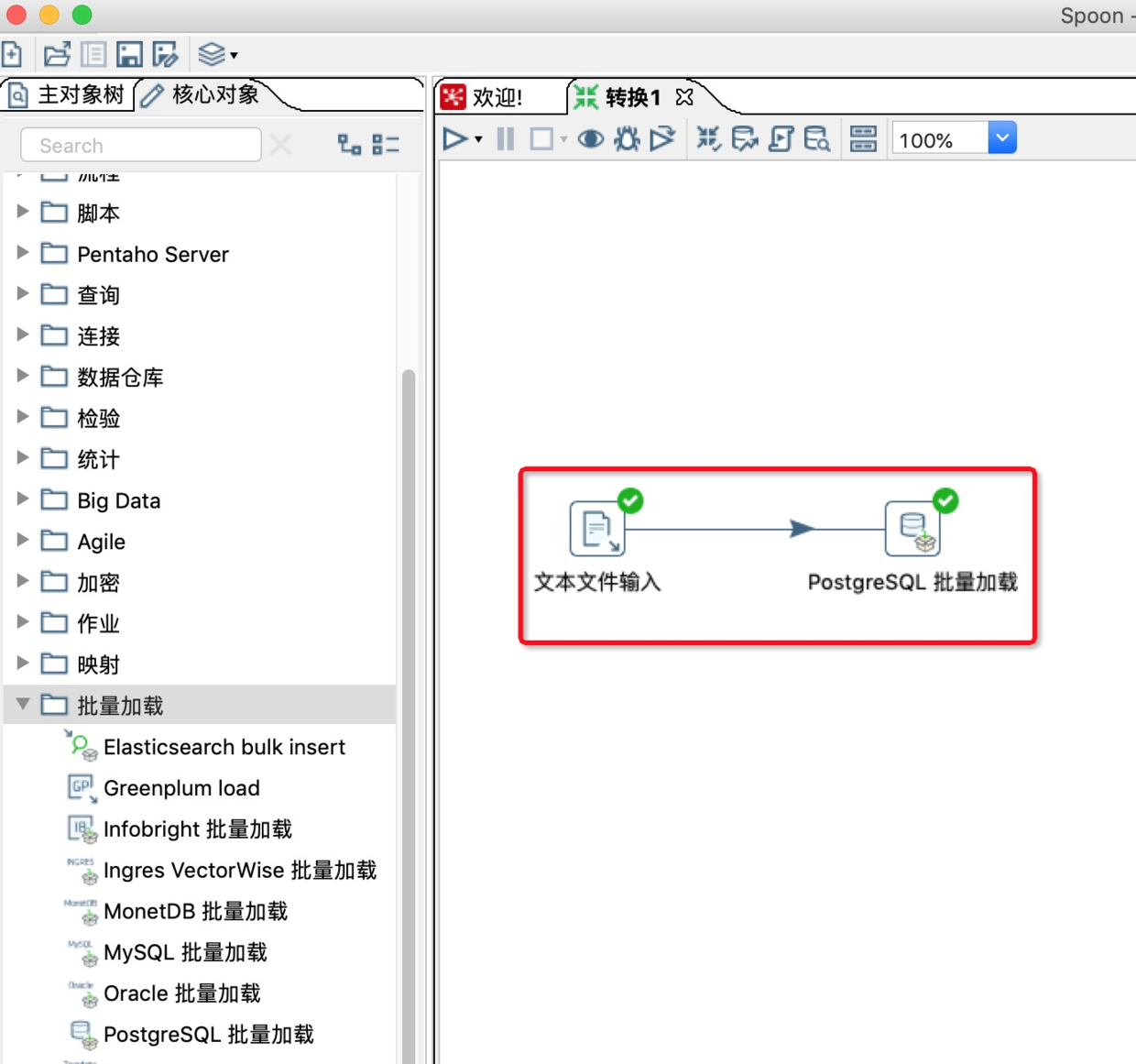
9.新建一条文件输入到PostgreSQL批量记载的连接线。
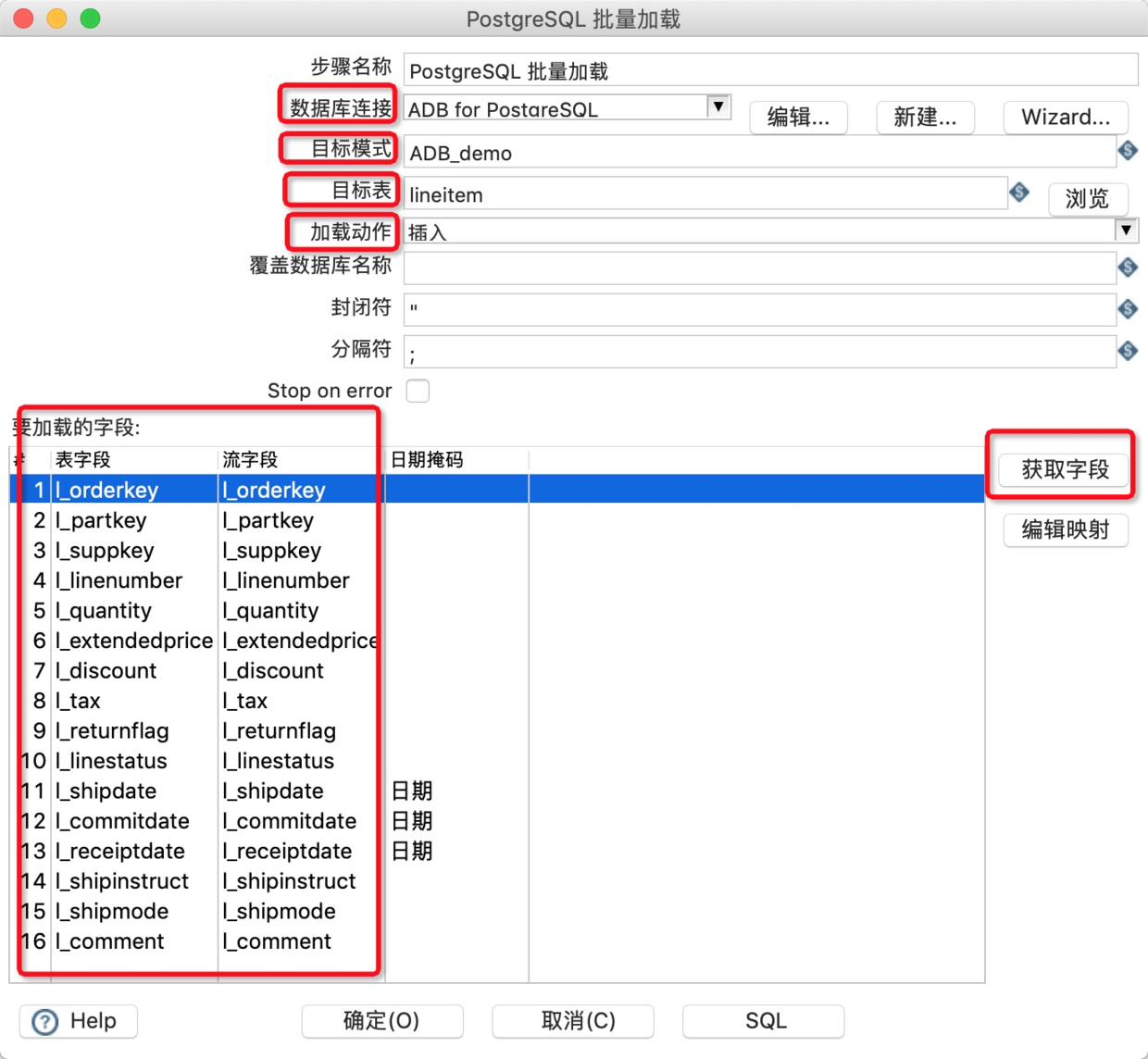
10.双击工作区的PostgreSQL批量加载图表,在批量加载对话框中进行参数配置:
11.单击白色三角箭头运行转换,观察运行日志和运行状态
待数据成功导入AnalyticDB for PostgreSQL后,您就可以使用AnalyticDB for PostgreSQL进行数据分析。
本文作者:陆封
本文为云栖社区原创内容,未经允许不得转载。














 511
511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









