







一、MySQL主从复制过滤
库级过滤
主库支持的过滤选项
# 仅将指定库的相关修改操作记入二进制日志(白名单)
binlog-do-db = DB_NAME
# 忽略指定库的相关操作记录二进制日志,其余的都记入二进制日志(黑名单)
binlog-ignore-db = DB_NAME
1
2
3
4
5
# 仅将指定库的相关修改操作记入二进制日志(白名单)
binlog-do-db=DB_NAME
# 忽略指定库的相关操作记录二进制日志,其余的都记入二进制日志(黑名单)
binlog-ignore-db=DB_NAME
PS: 一般不再主服务器上过滤,虽然可以减少主的开销,但这样会导致二进制日志不完整。
从库支持的过滤选项
# 基于库做白名单过滤;
replicate-do-db = DB_NAME
# 基于库做黑名单过滤;
replicate-ignore-db = DB_NAME
1
2
3
4
5
# 基于库做白名单过滤;
replicate-do-db=DB_NAME
# 基于库做黑名单过滤;
replicate-ignore-db=DB_NAME
一般在从服务器上过滤,但是这样并不会减少主往从复制数据占用带宽。
检查匹配的数据库取决于正在处理的语句的二进制日志格式,如果使用 ROW 格式记录了该语句,则要更改数据的数据库是选中的数据库。如果使用 STATEMENT 格式记录了该语句,则默认数据库(用 USE 语句指定)是选中的数据库。
注意:只有 DML 语句可以使用 ROW 格式记录,DDL 语句始终以 STATEMENT 形式记录,即使是binlog_format=ROW。因此,所有的 DDL 语句总是按照基于 STATEMENT 的复制规则进行过滤,这意味着你在主库执行 SQL 时必须先使用USE语句显式选择缺省数据库,以便应用 DDL 语句。不然当从库使用复制过滤选项时就可能会出现异常情况,比如你会发现由于你在主库执行 SQL(CREATE TABLE db.table …)没有使用 USE 语句时,你的 DDL 语句无法正常在从库执行,而 DML 却可以正常执行,导致从库异常。
库级过滤规则如下图所示:
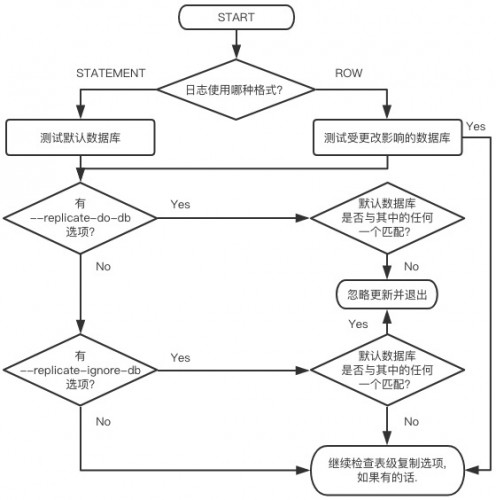
重要:在此阶段允许的语句尚未实际执行,在对所有表级选项 (如果有) 进行检查之前,不会执行该语句, 并且该过程的结果为允许执行该语句。
表级过滤
表级过滤选项,只能在从库设置。
# 基于表做白名单过滤,先在本地创建库,如果有多个表就需要多次使用该选项;
replicate-do-table = db.table
# 基于表做黑名单过滤,先在本地创建库,如果有多个表就需要多次使用该
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









