






MapReduce输出结果保存到MySQL
MapReduce输出结果保存到MySQL
文章目录代码编写思路
代码实现Map类
输出数据表的javaBean类
Reduce类
Job类
jar包运行前准备
运行jar包
代码编写思路
以词频统计案例为例,说明如何把MapReduce的输出结果保存到MySQL中。Map任务基本不变,主要把实现聚焦在Reduce的输出上。Reduce任务的输出的key为相应的输出数据表的javaBean类实现,该类需要实现org.apache.hadoop.io.Writable的Writable接口和org.apache.hadoop.mapreduce.lib.db的DBWritable接口,value为null,即空值。
代码实现
Map类
package mapreduce_demo.mapreduce4;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.io.Text;
public class Map extends Mapper{
@Override
public void map(LongWritable key,Text value,Mapper.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for(int i = 0;i
context.write(new Text(words[i]), new IntWritable(1));
}
}
}
输出数据表的javaBean类
package mapreduce_demo.mapreduce4;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;
import org.apache.hadoop.io.Text;
public class KeyWordTable implements Writable,DBWritable{
private String keyword;
private int sum;
public KeyWordTable() {
super();
}
public KeyWordTable(String keyword,int sum) {
super();
this.keyword = keyword;
this.sum = sum;
}
public String getKeyword() {
return keyword;
}
public void setKeyword(String keyword) {
this.keyword = keyword;
}
public int getSum() {
return sum;
}
public void setSum(int sum) {
this.sum = sum;
}
//实现Writable接口
public void write(DataOutput out) throws IOException {
out.writeInt(this.sum);
out.writeUTF(this.keyword);
}
public void readFields(DataInput in) throws IOException {
this.sum = in.readInt();
this.keyword = in.readUTF();
}
//实现DBWritable
//java获取mysql的数据,得到的ResultSet 集合,索引是从1开始
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1,this.keyword);
statement.setInt(2,this.sum);
}
/**DBWritable
* get data from resultset.And set in your fields
* @param resultSet
* @throws SQLException
*/
public void readFields(ResultSet resultSet) throws SQLException {
this.keyword = resultSet.getString(1);
this.sum = resultSet.getInt(2);
}
}
Reduce类
package mapreduce_demo.mapreduce4;
import java.io.IOException;
import org.apache.commons.lang.ObjectUtils.Null;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class Red extends Reducer{
@Override
public void reduce(Text key,Iterable values,Reducer.Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable val:values) {
sum += val.get();
}
KeyWordTable keywordTable = new KeyWordTable(key.toString(),sum);
context.write(keywordTable,NullWritable.get());
}
}
Job类
package mapreduce_demo.mapreduce4;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
public class App {
public static String driverClass = "com.mysql.jdbc.Driver";
public static String dbUrl = "jdbc:mysql://Master:3306/mydatabase";
public static String userName = "root";
public static String passwd = "root";
public static String inputFilePath = "hdfs://Master:9000/usr/local/hadoop/input_demo4";
public static String tableName = "keyword";
public static String [] fields = {"keyword","total"};
public static void main(String[] args) {
Configuration conf = new Configuration();
DBConfiguration.configureDB(conf,driverClass,dbUrl,userName,passwd);
try {
Job job = Job.getInstance(conf);
job.setJarByClass(App.class);
job.setMapOutputValueClass(IntWritable.class);
job.setMapOutputKeyClass(Text.class);
job.setMapperClass(Map.class);
job.setReducerClass(Red.class);
job.setJobName("MyWordCountDB");
FileInputFormat.setInputPaths(job,new Path(inputFilePath));
DBOutputFormat.setOutput(job,tableName,fields);
job.waitForCompletion(true);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
代码编写完毕后把项目打成jar包,上传到Hadoop集群中的Master节点下
jar包运行前准备
登录MySQL,创建相应的数据表
CREATE TABLE `keyword` (
`keyword` varchar(10) NOT NULL,
`total` int(10) NOT NULL
)
把MySQL的驱动jar包上传到Hadoop的各个节点下的hadoop安装目录/share/hadoop/common/lib目录下。否则会报出jave.io.IOException:com.mysql.jdbc.Driver异常。
运行jar包
hadoop jar /usr/local/code/mapreduce_demo4.jar
jar包运行完毕后登录到MySQL,查看相应的数据表
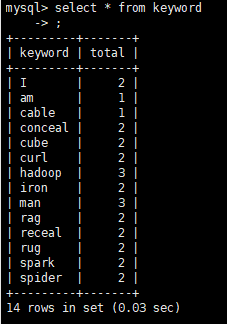
MapReduce输出结果成功存储到MySQL中
MapReduce输出结果保存到MySQL相关教程














 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









