







将MapReduce的结果导入到数据库中
有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如要将我们一堆数据的分析结果存储到我们的关系型数据库中以便于在web程序中进行查询显示,这时候我们就需要 mapreduce 与 mysql 进行数据的交互。
-
为了方便 MapReduce 直接访问关系型数据库(Mysql,Oracle),Hadoop提供了DBInputFormat和DBOutputFormat两个类。通过DBInputFormat类把数据库表数据读入到HDFS,根据DBOutputFormat类把MapReduce产生的结果集导入到数据库表中
使用DBOutputFormat和DBInputFormat类与数据库进行交互编写程序会相对来说简单一些。这里以DBOutputFormat说明一下将MapReduce结果输出到mysql数据库中的操作流程。
开发环境
- 物理机:Windows10
- 开发工具:intellij 2017
- hadoop包版本:2.9.1
- mysql驱动版本:5.1.27
一、使用DBOutputFormat将MapReduce输出结果写入到mysql中
- 首先需要自定义一个类(eg:MyDemo),类里的字段跟数据库表中的字段相对应,并且因为该类的对象可能会需要序列化等,所以我该类还需要实现Writable, DBWritable接口覆写相关的read、write等序列化方法。
- 在reduce方法中将我们需要使用的字段封装到我们的自定义类的属性当中,最后将reduce方法的输出key设置为我们自定义的类的类型(eg:MyDemo),再使用context.write()方法进行写出。
- 在job主类中,我们需要进行相关的配置,让程序知道我们要将reduce结果输出到mysql中而不是输出到hdfs中。
1.在job主类中添加 DBConfiguration.configureDB(conf, Driver,
url, user, password); 配置mysql数据相关信息。
2.配置我们自定义的outputformat类,job.setOutputFormatClass(DBOutputFormat.class); 因为在这里我们将数据写入到mysql,所以可以不用配置输出路径了。
3.使用DBOutputFormat.setOutput(job, “log”, “ip”, “count”);指定要输出到mysql的哪个表,要输出哪些字段。
4.如果要将程序打成jar包放到集群上运行,此时有两种选择:
1) .一种是将mysql的驱动包上传的集群中的某个目录下面,并且在job主类中使用 job.addArchiveToClassPath(new Path("/lib/mysql/mysql-connector-java-5.1.18-bin.jar"));将mysql驱动添加到类路径下。
2).第二种是在项目的pom.xml文件中将mysql驱动的scope属性指定为runtime。
注:如果要在idea中进行测试程序能否将结果输出到mysql中,需要去掉属性,或者将该属性值设置为test。并且添加上mysql驱动的版本号!!!否则会报找不到mysql驱动异常!
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
进行完以上步骤以后,就可以使MapReduce程序的输出结果正常的输入到mysql数据库中了。
二、使用自定义outputformat类实现向MySQL写入
使用hadoop提供的DBOutputFormat将MapReduce程序输出结果写入到mysql中,固然是非常容易进行编写操作的,但是也缺乏一定的灵活性,我们可以自定义outputformat类来实现我们的自定义写入MySQL操作!在自定义类中我们可以使用原生的jdbc按自己的需求实现将MapReduce分析结果写入到MySQL中
1. 首先我们要自定义一个MySQLTextOutputFormat类,该类继承至outputformat,覆写它的相关方法,在该类中实现获取数据库连接,向数据库写入数据等相关操作。
2. 在job主类中配置使用自定义outputformat类job.setOutputFormatClass(MySQLTextOutputFormat.class);
3. 如果该程序要打包提交到集群中运行,需要将mysql驱动添加到类路径下:job.addArchiveToClassPath(new Path("/lib/mysql/mysql-connector-java-5.1.27-bin.jar"));
例子展示:
如果对在idea中搭建hadoop运行环境有问题,请访问:idea中搭建hadoop环境
1.创建数据库表
在mysql中创建一张名为wordcount的表,用于存放单词统计后的结果:
DROP TABLE IF EXISTS `wordcount`;
CREATE TABLE `wordcount` (
`word` varchar(255) DEFAULT NULL,
`count` int(10) DEFAULT NULL,
`index` int(10) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`index`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2. 编写一个JDBCUtil类用于获取和关闭数据连接
package com.wp.demo.util;
import java.sql.Connection;
import java.sql.DriverManager;
public class JDBCUtil {
private static final String MYSQL_DRIVER_CLASS = "com.mysql.jdbc.Driver";
private static final String MYSQL_URL =
"jdbc:mysql://localhost:3306/mybatis?userUnicode=true&characterEncoding=UTF-8";
private static final String MYSQL_USERNAME = "root";
private static final String MYSQL_PASSWORD = "wenpan";
/**
* 获取mysql的连接对象
* @return
*/
public static Connection getConnection(){
Connection conn = null;
try {
Class.forName(MYSQL_DRIVER_CLASS);
conn = DriverManager.getConnection(MYSQL_URL,MYSQL_USERNAME,MYSQL_PASSWORD);
}catch (Exception e){
e.printStackTrace();
}
return conn;
}
}
2.编写mapper类
package com.wp.demo.mapper;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class AnasislyTypeMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
private Text k = new Text();
private IntWritable v = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split(" ");
for (String field : fields) {
k.set(field);
v.set(1);
context.write(k,v);
}
}
}
3.编写reducer类进行单词统计
package com.wp.demo.reducer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class AnasislyTypeReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
IntWritable v = new IntWritable();
for (IntWritable value : values) {
count = count + value.get();
}
v.set(count);
context.write(key,v);
}
}
4.编写自定义的outputformat类,将reduce输出结果写入到MySQL中
注:该类是我们向数据库写入的重点操作类,里面最主要的方法是public void write(IntWritable key, IntWritable value),该方法接收reduce方法的输出结果,然后在方法体内进行对数据库的相关操作!!!
package com.wp.demo.format;
import com.wp.demo.util.JDBCUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* 将数据写入到mysql
*/
public class MySQLTextOutputFormat extends OutputFormat<Text,IntWritable> {
protected static class MySQLRecordWriter extends RecordWriter<Text,IntWritable> {
private Connection connection = null;
public MySQLRecordWriter(){
//获取资源
connection = JDBCUtil.getConnection();
}
/**
* 输出数据,通过jdbc写入到mysql中
* @param key :reduce方法写出的key
* @param value :reduce方法写出的value值
* @throws IOException
* @throws InterruptedException
*/
@Override
public void write(Text key, IntWritable value) throws IOException, InterruptedException {
PreparedStatement pstat = null;
System.out.println("写入数据库!");
try {
String insertSQL = "insert into wordcount(word,count)" +
" values(?,?)";
pstat = connection.prepareStatement(insertSQL);
//取得reduce方法传过来的key
String type = key.toString();
String count = value.toString();
pstat.setString(1,type);
pstat.setInt(2,Integer.parseInt(count));
//执行向数据库插入操作
pstat.executeUpdate();
}catch (SQLException e){
e.printStackTrace();
}finally {
if(pstat != null){
try {
pstat.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
/**
* 释放资源
* @param taskAttemptContext
* @throws IOException
* @throws InterruptedException
*/
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
if(connection != null){
try {
connection.close();
}catch (SQLException e){
e.printStackTrace();
}
}
}
}
//@Test
public void test(){
MySQLRecordWriter tt = new MySQLRecordWriter();
Connection con = JDBCUtil.getConnection();
System.out.println("+++++++++++++" + con);
}
@Override
public RecordWriter<Text, IntWritable> getRecordWriter(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
return new MySQLRecordWriter();
}
@Override
public void checkOutputSpecs(JobContext jobContext) throws IOException, InterruptedException {
}
//下面这段代码,摘抄自源码
private FileOutputCommitter committer = null;
public static Path getOutputPath(JobContext job) {
String name = job.getConfiguration().get("mapred.output.dir");
return name == null?null:new Path(name);
}
@Override
public OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException {
if(committer == null){
Path output = getOutputPath(context);
committer = new FileOutputCommitter(output, context);
}
return committer;
}
}
5.在job配置类中进行指定使用自定义的outputformatformat类
package com.wp.demo.tool;
import com.wp.demo.format.MySQLTextOutputFormat;
import com.wp.demo.mapper.AnasislyTypeMapper;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.wp.demo.reducer.AnasislyTypeReducer;
public class AnasislyTypeTool {
public static void main(String[] args) throws Exception {
//使用windows上的本地路径进行测试
args = new String[]{"E:\\input\\demoinput\\hello1.txt"};
Configuration conf = new Configuration();
//获取job对象
Job job = Job.getInstance(conf);
//设置jar包
job.setJarByClass(AnasislyTypeTool.class);
//关联mapper和reducer
job.setMapperClass(AnasislyTypeMapper.class);
job.setReducerClass(AnasislyTypeReducer.class);
//设置map输出数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置最终输出数据类型kv
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//outputformat输出到mysql中,自定义输出类
job.setOutputFormatClass(MySQLTextOutputFormat.class);
//添加mysql驱动到类路径下,提交到集群时需要使用
//job.addArchiveToClassPath(new Path("/lib/mysql/mysql-connector-java-5.1.27-bin.jar"));
//设置输入输出文件路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//因为要输出到mysql中所以不用配置输出路径
//FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交到yarn集群
job.waitForCompletion(true);
}
}
6.pom.xml文件依赖如下:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.9.1</version>
</dependency>
<!--提交到集群时使用-->
<!--<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>-->
<!--https://mvnrepository.com/artifact/mysql/mysql-connector-java-->
<!--idea中测试使用-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
7.在idea中进行运行测试
1.运行结果图
2.查看数据库数据
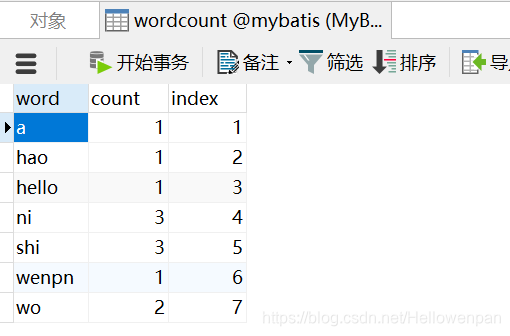
以上就是将MapReduce执行后的结果数据写入到mysql中的两种方式,一种是使用hadoop官方提供的DBOutputFormat类去实现,第二种就是自定义一个outputformat类使用jdbc将MapReduce执行后的结果写入到数据库。个人比较喜欢第二种方式!














 5586
5586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









