







作者:梁伟雄
作者简介:Spark爱好者
前置知识
在我们一起学习Spark之前,我们需要先了解Spark在整个Hadoop生态圈的位置。如下图(图片来源于网络,如有侵权请告知删除):
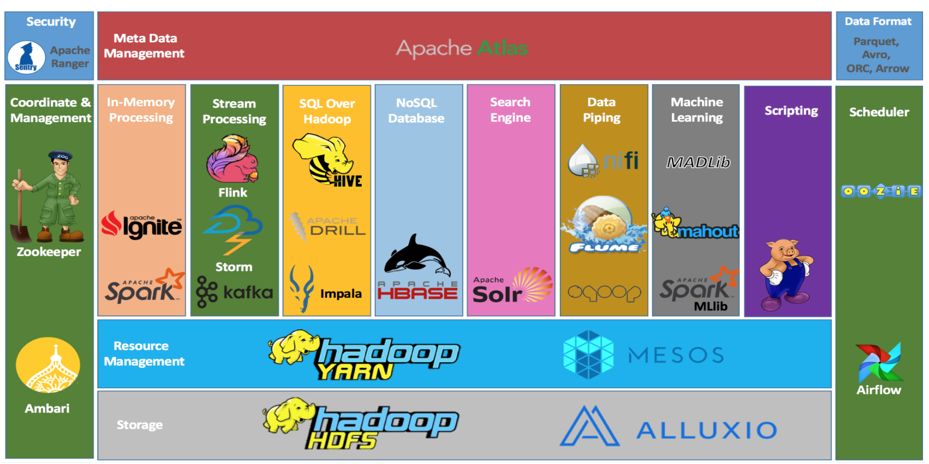
上图自下而上描绘了数据在整个Hadoop生态圈的流转过程。首先,我们会通过Flume、Sqoop、DataX等数据采集工具把数据从数据源抽取到HDFS分布式文件系统并以三副本的形式保存。这里的数据源有很多种,如日志、数据库等。存储在HDFS上的数据要发挥其价值,需要相关的工具来对数据进行处理(包括ETL、分析、计算等),继而得到各种业务指标、报表或者数据产品。而上述所提到的相关的工具可以是Spark、MapReduce等。
Spark大数据计算引擎,可以对大规模数据集进行基于内存的分布式计算。但熟悉数仓建模的朋友会更加偏向于使用Hive来构建整个数仓体系,并且Hive的稳定性及其易用性(使用HQL代替MapReduce来处理问题)也是Hive至今仍在大数据领域占有重大话语权的主要原因。在Spark发展的过程中,Spark和Hive之间的整合就从未间断,从一开始的Shark到后面的Spark SQL。目前,Hive使用的场景基本都可以使用Spark来替代。Hive更多的用于T+1的场景,而Spark更加灵活,数据处理速度会更快,对时间要求高的业务场景可以考虑Spark的使用。
当然,整个Hadoop生态圈除了HDFS存储引擎以及Spark计算引擎,还包括以下组件:资源调度系统YARN,负责资源的申请和调度,作业调度系统如Oozie、Azkaban、Airflow、DophinScheduler等,Zookeeper集群协调管理,消息队列如Kafka。其他组件,这里就不一一细说。下面通过一个例子把上面所提到的大数据组件串联起来。比如说:
直接使用Spark读取MySQL、日志等数据源,也可以使用Fl
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1644
1644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









