






最近失恋了,恶心的厉害。面容憔悴来上班, 有点晕。早日走出。
前天实习下班跑了个导入程序,如果正常进行,起码要五六个小时。今天来发现才导入了几百万个,崩了。
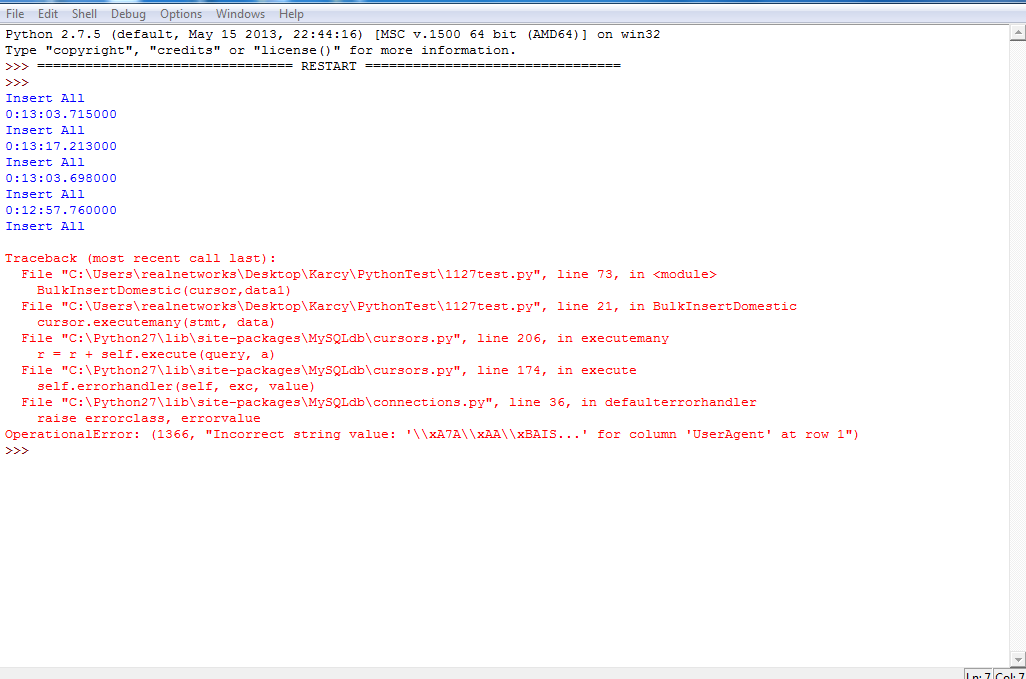
就是那样。 一看又是编码问题,忧伤啊。之前碰到过一次,没解决,最后为了快,用英文回避了。没想到该来的总要来啊。。。
学了很久通信原理,信号系统什么的,对编码有一定了解,但对计算机编码还是一头雾水。
What the hell .
编码:
1.普通字符串与unicode转换
无论是什么平台什么编码格式都能转换为unicode格式。
1.以utf8编码方式把字符串转换为unicode:
1 'aaa'.decode('utf8')
注意:这样写已经表示'aaa'是一个unicode格式的字符串了,等同于
u'aaa'.decode('utf8')
如果全部是英文字符或者数字,则utf8与gbk输出结果一致,而且带不带u都一样
2.汉字
把普通中午字符串转换为unicode;注意:此时字符串前不能加u,而且汉字编码只能写gbk或者gb2312等
1 '也有'.decode('gbk')
把上面的结果再转成gbk
1 u'\u4e5f\u6709'.encode('gbk')
或者 转成utf8
1 u'\u4e5f\u6709'.encode('utf8')
3 总结
decode是解码为unicode编码。encode编码。
utf8不等于unicode。
>>> 'aaa'.decode('utf8')
u'aaa'
>>> unicode('aaa', 'utf8')
u'aaa'
>>> 'aaa'.decode('utf8')
u'aaa'
>>> u'aaa'.decode('utf8')
u'aaa'
>>> '也有'.decode('gbk')
u'\u4e5f\u6709'
>>> print u'\u4e5f\u6709'.encode('gbk')
也有>>> u'\u4e5f\u6709'.encode('gbk')'\xd2\xb2\xd3\xd0'
>>> u'\u4e5f\u6709'.encode('utf8')'\xe4\xb9\x9f\xe6\x9c\x89'
你会看到这两个汉字在gbk和utf8编码格式下的字符,这里不多研究了(utf8汉字编码比gbk多一个字符)
特别注意:utf8编码、gbk编码的原型加上u然后再转unicode是错误写法,肯定转不了,要先去掉u,用str()处理去掉u。
>>> urllib.unquote(str(s)).decode('utf8')
u'\u957f\u6625\u5e02'
>>> print urllib.unquote(str(s)).decode('utf8')
长春市
4.utf8和UNICODE的关系:
这个问题简单的说主要要区分清楚
unicode的string,和包含unicode编码内容的普通string的区别。
比如
#-*- coding=utf-8 -*-
s1="你好" #普通的string
s2=u"你好" #unicode的string
s3=s1.decode('utf-8') #把普通的string转换成unicode的string
真正的unicode其实只是对文字的一个唯一编码,utf-8,utf-16都是这个编码到文件的一种实现方式。
是的,unicode准确说是一个字符编码表,而utf-32,utf-16,utf-8是unicode这个字符编码表的传输方式。比如 UTF-8 (UCS Transformation Format — 8-bit
一般所谓的unicode 其实是utf-16,双字节或者4字节。
utf-8是多字节。
unicode和utf-8直接可以直接根据固定规则相互转换;而像unicode 或utf-8 到gbk 转换,在windows 下,需要查codepage, 速度很慢(相对于前面的公式转换)
言归正传,怎么解决这个问题?
mysql 语句 alterdatabaseyourdatabasecharactersetutf8;
show variables like 'character%' 查看数据库的编码
引用
1 .alert database tuanplus character set utf8
2 .alter table address convert to character set utf8
出现这个异常是mysql问题,而非python的问题,这是因为mysql的字段类型是utf-xxx, 而在mysql中这些utf-8数据类型只能存储最多三个字节的字符,而存不了包含四个字节的字符。
有两个办法可以解决此问题:
修改mysql数据表的字段类型为utf8mb4,不过这个类型只有在mysql 5.5之后才可以支持
删除4字节的utf8字符,然后再保存
上述方法在我的情况下并不适用,重建数据库也不能解决。但考虑到要有大量数据的导入,这个时候要求程序健壮性。
健壮性很重要啊!python下,用了try...except结构。except部分用来记录哪个文件出错,continue。最后再对错误文件进行导入。
7天的log files 已经有2 billions 。
由于是bulk insert,在最终的except部分,我将对于其他的正确文件的最后一起导入变为对错误文件每隔一百就插入,遇错则drop 这一小块。最后扔掉了大约2K的数据,但是,对于一个将近2millions的文件来说,比例很小,如果在整体的2 billion下看,那更是微乎其微。
总之,程序健壮性,和性价比。















 1362
1362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









