






1: RestTemplate超时时间失效问题
每一笔http都应该有自己超时时间而不是使用公共超时时间。所以我们在设计的时候restTemplate超时时间是通过业务参数实时定义的
public ResponseEntity<Boolean> httpTimeEntrance(@RequestBody HttpReqDTO reqDTO){
HttpComponentsClientHttpRequestFactory requestFactory = new HttpComponentsClientHttpRequestFactory(); //每次new一个factory,但是template是公共的,线程不安全
try {
LogUtil.info(log,"httpTimeEntrance pram {}",()-> FastjsonUtil.toJson(reqDTO));
requestFactory.setReadTimeout(reqDTO.getTime());
requestFactory.setConnectTimeout(reqDTO.getTime());
restTemplate.setRequestFactory(requestFactory);
HttpHeaders headers = new HttpHeaders();
HttpEntity<HashMap<String, Object>> entity =new HttpEntity<>(headers);
restTemplate.exchange(reqDTO.getPath(), HttpMethod.GET,entity,Boolean.class);
} catch (Exception e) {}
解决方案:
将超时时间设置到threadLocal中 然后实现HttpContextFactory的apply方法从threadLocal中获取超时时间
sgw异网话费充值出向带宽网络占用告警
异网话费充值调用第三方充值业务(通过httpClient的工具类调用)自己写的工具类,业务方将本网代扣流量切到异网通道,业务量陡增,同时业务方五月初充值订单闭环慢且接口响应变长触发公网连接数占用过高告警,当时公网的总连接数是:5W; 告警的时候sgw已经占用连接:4W+
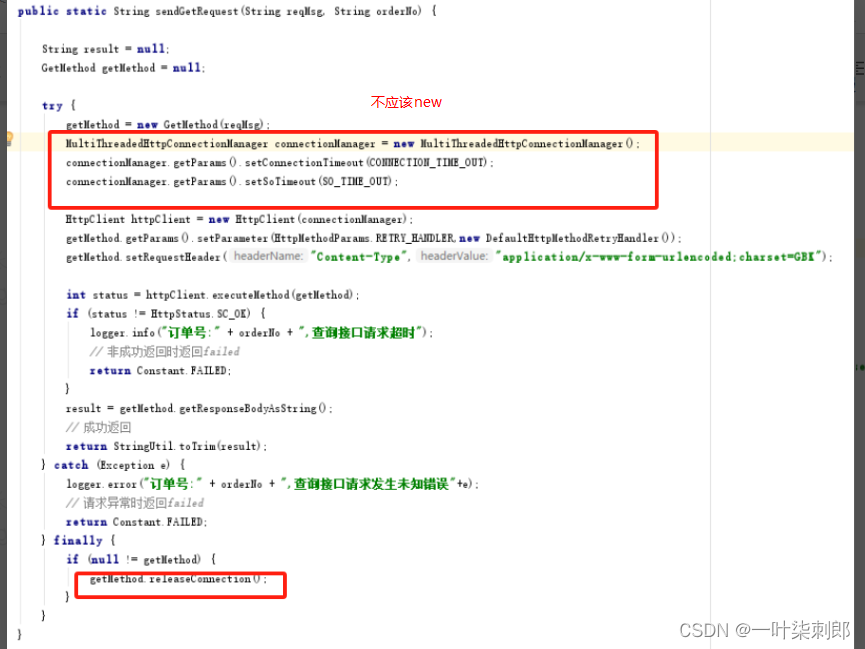
new对象表示开一个socket,socket没复用,调用时间变长后,导致socket越来越多,改为static,设置最大连接数
案例3:黑名单缓存数据丢失问题
400万的黑名单的数据插入到redis的缓存中,因为考虑到批量操作、以及数据量的问题 所以使用了redis的管道命令,缓存数据刷新完毕后发现redis中存储的数据只有50w的数据 ,大部分数据没入到redis里面。
redis内存也没打满,可以排除redis淘汰策略导致。
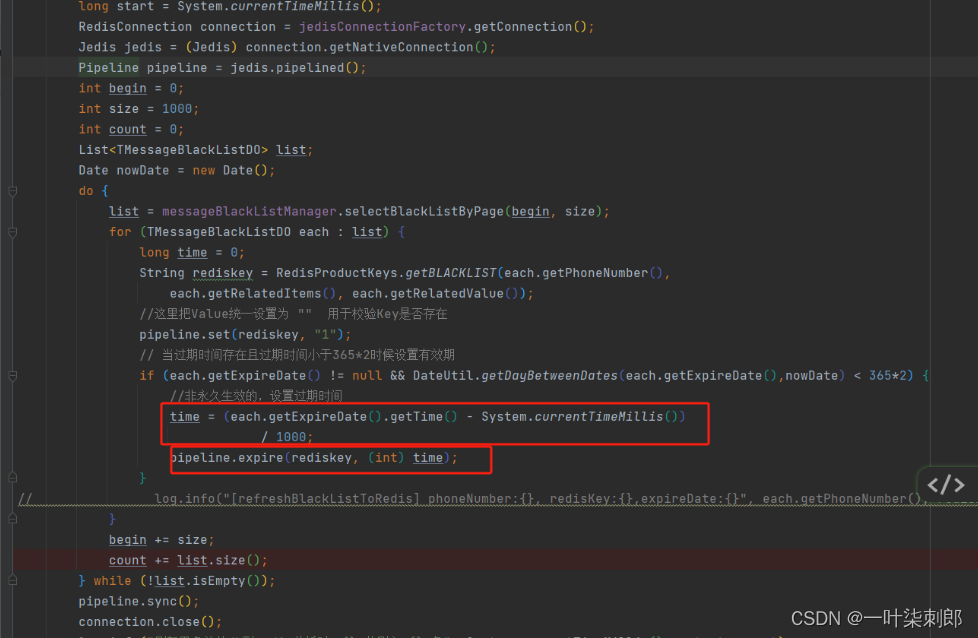
long转换int,高4位被截取,有些低4位最高位是1,则变为负数,设置过期直接失效消失
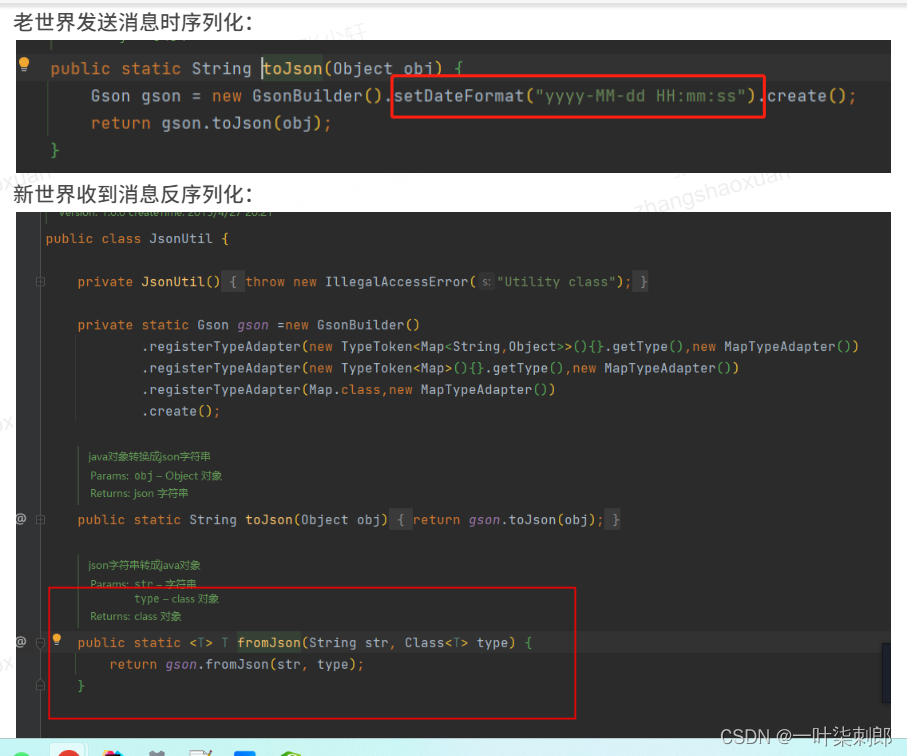
Gson反序列化日期无法转换
短信老世界新增黑名单信息后 需要通过同步新世界消费 测试过程中线下环境验证通过 生产环境出现时间转换报错问题 错误堆栈信息如下
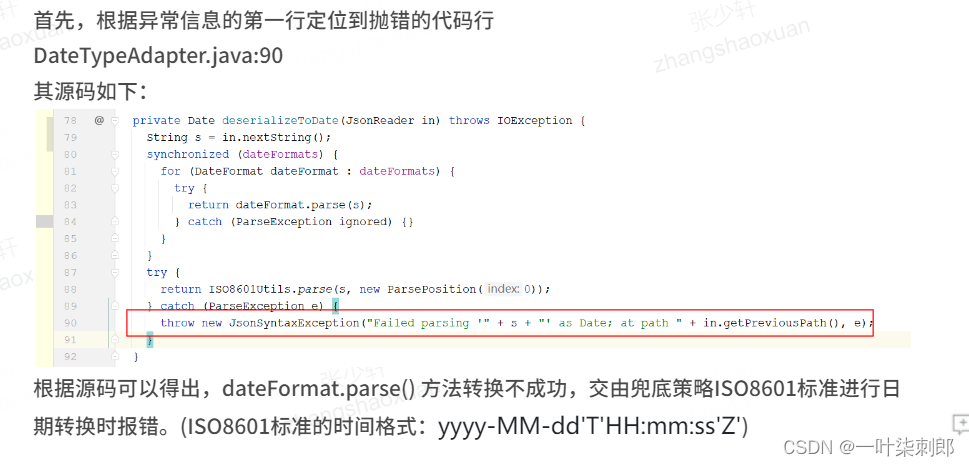
dateFormat.parse() 方法转换不成功,交由兜底策略ISO8601标准进行日期转换时报错。(ISO8601标准的时间格式:yyyy-MM-dd’T’HH:mm:ss’Z’)
手动指定反序列化的格式
Gson gson = new GsonBuilder()
.setDateFormat("yyyy-MM-dd HH:mm:ss")
.create();
Gson序列化日期加锁,导致并发线程阻塞
客户信息是个大对象,一个对象中包含十多个日期字段,例如创建日期、更新日期、证件起始日期、证件有效期等等
https://blog.csdn.net/qsmiley10/article/details/127090322
es的scroll默认1分钟,每次都updateByquery都会创建scroll 导致scroll contexts过多,Trying to create too many scroll contexts. Must be less than or equal to: [500]
分析:GET /_nodes/stats/indices/search
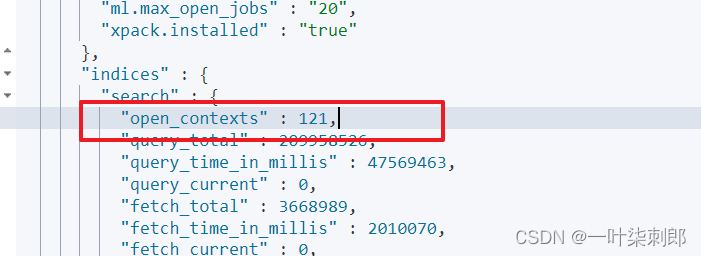
打开的context很多的话,说明以后没及时关闭的
2.查看 open.max.scroll.context是否太小,结果发现是500也够用
3.检查代码里是否有设置scroll,结果发现没手动设置
搜同样问题时找到了issue,https://github.com/elastic/elasticsearch/issues/71618
解决:
1.es默认scroll开启,1分钟内创建太多会抛异常,可将scroll设置为10s,存活时间少一点,这样并发就会更大
2.用完后删除clearScroll()
3.本质还是es版本要升级,但是阻力比较大
kafka数据同步两个redis,同步失败,数据丢失
A–>MQ–>B
在B段默认开启了自动提交位移,B端更新失败,此时数据从kafka丢失,
使用手动提交,确定更新完成后提交位移
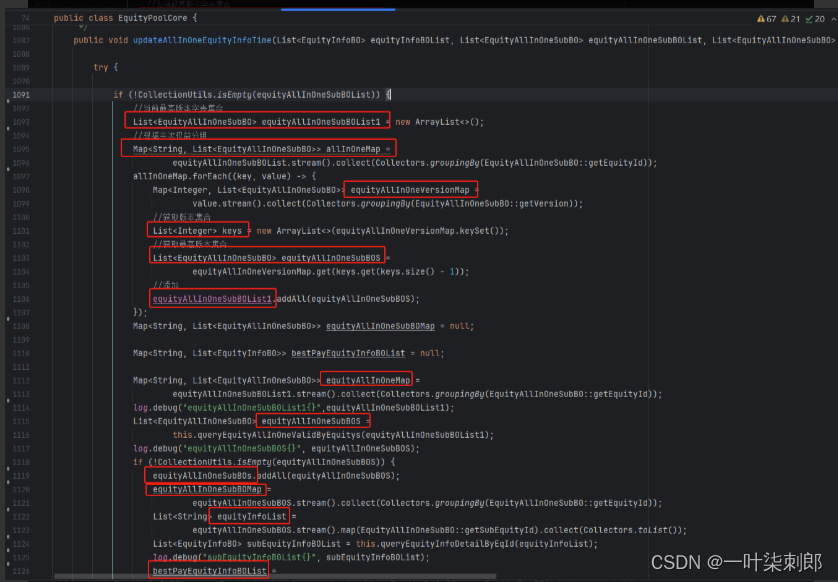
查询接口创建对象太多导致线程池打满
月初1号流量高峰,是平时10倍,查询接口创建对象过多单笔(100M),导致频繁YGC-》FGC-》stopworld,CPU飙升,线程等待导致线程池打满
问题1.接口未对必要参数进行判空,导致sql捞到太多数据

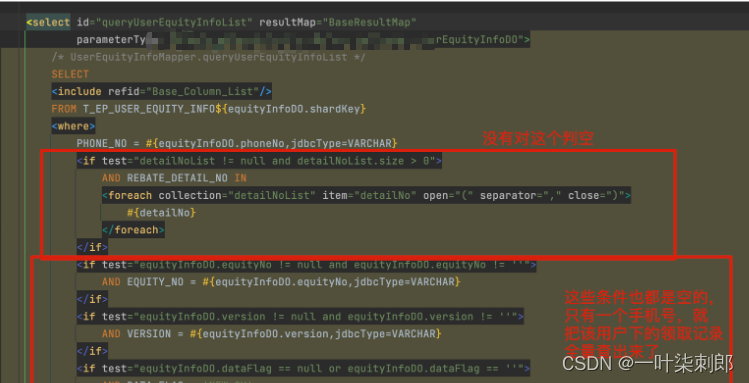
**问题2.**日志打印问题,三层嵌套打印,查询条件确实导致循环过多
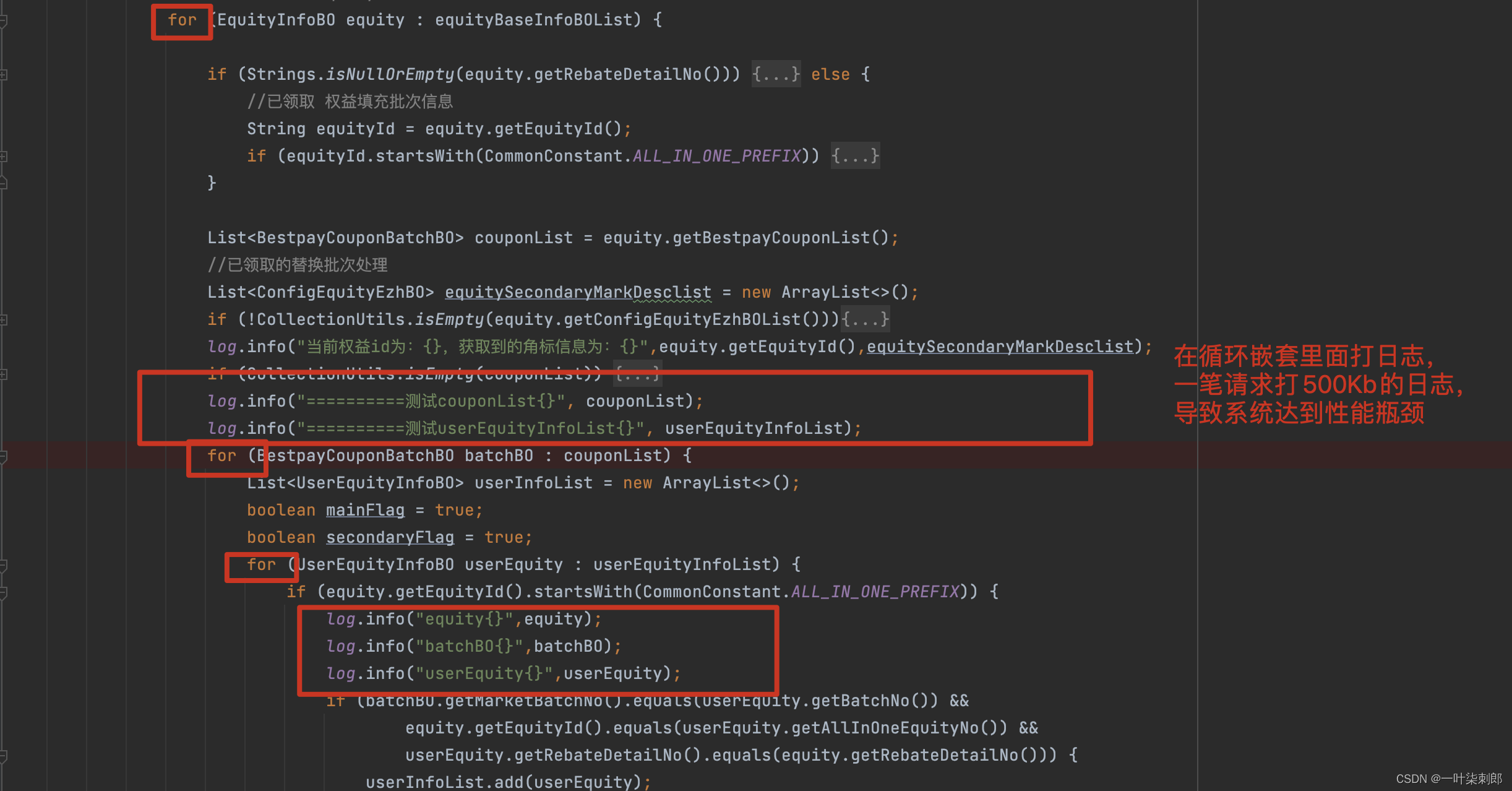
问题3.对象太多
生产灰度和应急的正确方式
1.灰度
灰度的目的不是为了验证多少流量,而是为了尽可能覆盖场景,如果高频请求,灰度应该灰5分钟,然后切换回生产系统,观察是否有问题,如果没问题则依次10分钟、1小时 24小时等逐步拉大周期,最后全量切生产
很多功能的验证切流都是在晚上,原因就是最小影响
可灰度的核心在于:用最小成本、最小代价、最小影响验证功能
2、可应急
可应急本质就是能发现问题快速回滚,有时候服务器节点比较多时,对新功能评估影响,可以增加配置开关,一旦有问题需要直接切开关,关闭新功能















 5941
5941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









