




 本文深入探讨缓存雪崩、穿透与击穿等问题,提供有效解决方案,包括缓存预热、数据一致性维护及Redis单线程高效处理原理。涵盖缓存设计、Redis集群脑裂现象及其对策。
本文深入探讨缓存雪崩、穿透与击穿等问题,提供有效解决方案,包括缓存预热、数据一致性维护及Redis单线程高效处理原理。涵盖缓存设计、Redis集群脑裂现象及其对策。
目录
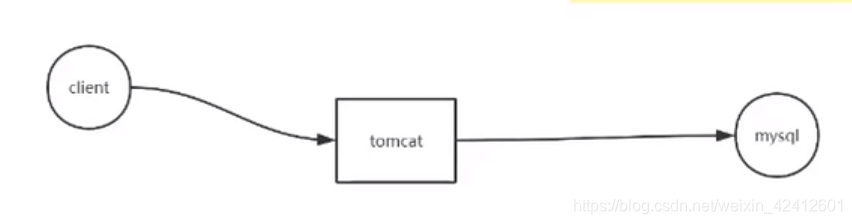
mysql处最容易发生瓶颈,解决方法,减少连接。最初解决方法使用数据库连接池,但是还是会发生了瓶颈,分库分表以及mysql集群,再然后加缓存。缓存首先redis,在tomcat和mysql之间放一个缓存,可以帮mysql抵挡一部分请求,但是加了缓存会带来一些问题。
缓存雪崩
为啥使用缓存
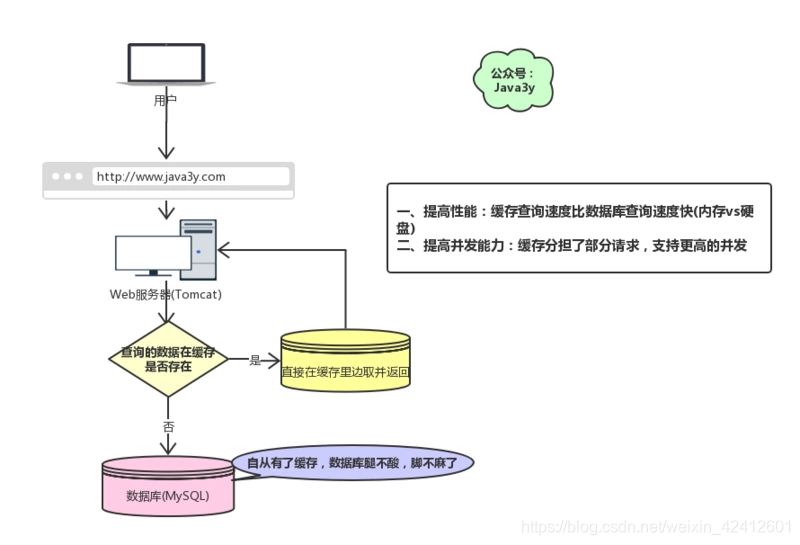
现在有个问题,如果我们的缓存挂掉了,这意味着我们的全部请求都跑去数据库了。
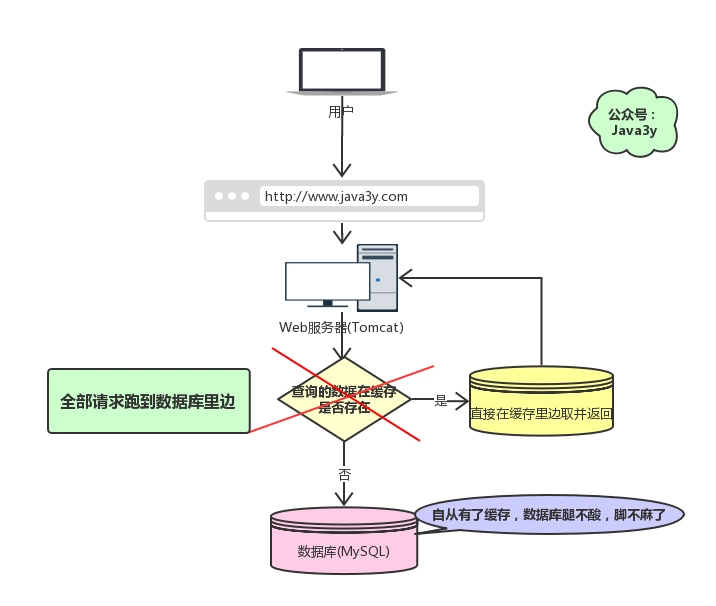
如果缓存数据设置的过期时间是相同的,并且Redis恰好将这部分数据全部删光了。这就会导致在这段时间内,这些缓存同时失效,全部请求到数据库中。
这就是缓存雪崩:
Redis挂掉了,请求全部走数据库。- 对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。
解决缓存雪崩
对于“对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。”这种情况,非常好解决:
解决方法:在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
对于“Redis挂掉了,请求全部走数据库”这种情况,我们可以有以下的思路:
- 事发前:实现
Redis的高可用(主从架构+Sentinel或者Redis Cluster),尽量避免Redis挂掉这种情况发生。 - 事发中:万一
Redis真的挂了,我们可以设置本地缓存(ehcache)+限流(hystrix),尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的) - 事发后:
redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
缓存穿透
什么是缓存穿透
缓存穿透是指查询一个一定不存在的数据。 由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。不能避免低频的缓存穿透,但是能避免高频的缓存穿透。
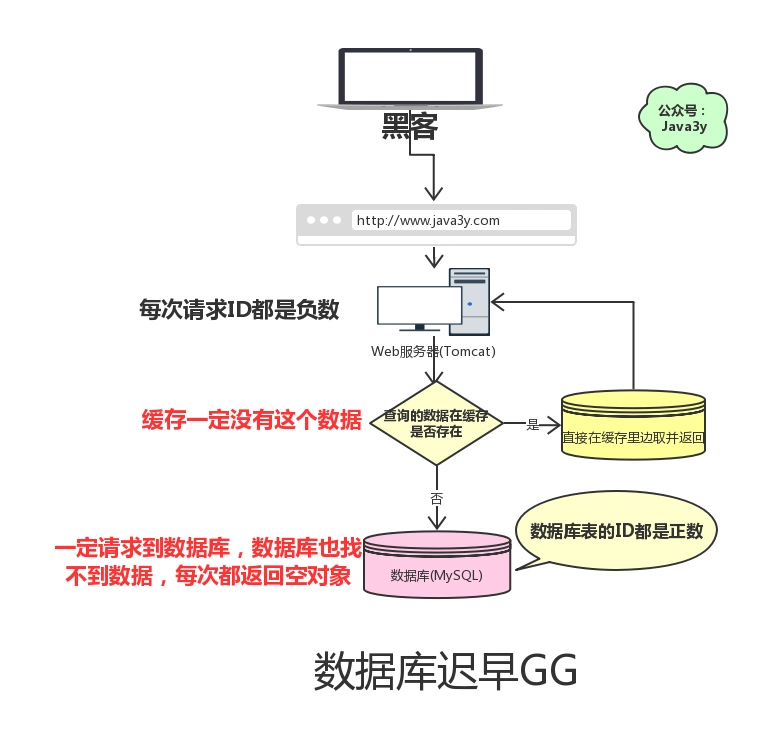
这就是缓存穿透:
- 请求的数据在缓存大量不命中,导致请求走数据库。
缓存穿透如果发生了,也可能把我们的数据库搞垮,导致整个服务瘫痪!
解决缓存穿透
解决缓存穿透也有两种方案:
- 由于请求的参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(
BloomFilter)或者压缩filter提前拦截,不合法就不让这个请求到数据库层!
布隆过滤器(推荐)
就是引入了k(k>1)k(k>1)个相互独立的哈希函数,保证在给定的空间、误判率下,完成元素判重的过程。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Bloom-Filter算法的核心思想就是利用多个不同的Hash函数来解决“冲突”。
Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减少冲突,我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。这便是Bloom-Filter的基本思想。
Bloom-Filter一般用于在大数据量的集合中判定某元素是否存在。
- 当我们从数据库找不到的时候,我们也将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了。
这种情况我们一般会将空对象设置一个较短的过期时间。这种方式对付低级黑客好使,对付高级黑客,每次都给你传给不同uuid进来,redis存一堆null,然后redis根据淘汰策略给你淘汰有用的数据。
//模拟防穿透模式
public String getPassThrough(String key) {
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (StringUtils.isBlank(storageValue)) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
缓存击穿
缓存击穿:对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。如果这个key在大量请求同时进来前正好失效,那么所有对这个key的数据查询都落到db,我们称为缓存击穿。
解决: 加锁大量并发只让一个去查,其他人等待,查到以后释放锁,其他人获取到锁,先查缓存,就会有数据,不用去db
缓存预热
缓存预热就是系统上线后,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
缓存预热解决方案:
(1)直接写个缓存刷新页面,上线时手工操作下;
(2)数据量不大,可以在项目启动的时候自动进行加载;
(3)定时刷新缓存;
缓存数据一致性
缓存里的数据如何和数据库的数据保持一致??
缓存数据一致性
- 双写模式:写完数据库,缓存跟着改一下
- 缺点:线程1改完数据库,准备去改缓存,结果没cpu时间片了或者执行的慢,此时线程2快速的改数据库,改缓存, 然后线程1才把缓存改了。这就出现了脏数据了,本来线程2的修改数据才是最新的数据,结果因为线程1的原因,出现了脏数据。
- 解决
- 改数据和改缓存,这两部操作,用锁锁起来
- 如果能容忍最终一致性,可以给缓存设置一个过期时间。也是ok的
- 失效模式: 写完数据库,对应的缓存删了,等待下次主动查询,更新缓存即可
- 缺点:请求1在一号机器,写完数据,并把缓存删了;请求2进来二号机器,改数据库1号数据改为2,但是机器2执行的慢,还没改完,此时请求3进来,发现确实没缓存,读取数据库,读取到了老的数据(机器2还没改完数据),然后要把读取到的老数据放到缓存里,但是机器三把数据放到缓存的操作比较慢,机器二在这段时间改完了数据,也删了缓存,然后机器三把数据放到了缓存里,此时,缓存里的数据就不是最新的数据了
- 解决
- 改数据和改缓存,这两部操作,用锁锁起来。但是加锁是很笨重的,如果数据经常修改,还要不要放缓存,为了保证缓存数据一致性,经常加锁,整个系统就很慢,还不如直接查询数据库,不放缓存了。因此,经常修改的数据,想要实时的读取,实时性要求高的,直接读数据库
缓存数据一致性-解决方案
无论是双写模式还是失效模式,都会导致缓存的不一致问题。即多个实例同时更新会出事。怎么办?
1、如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加上过期时间,每隔一段时间触发读的主动更新即可
2、如果是菜单,商品介绍等基础数据,这些数据是能容忍一定程度的缓存不一致,比如:ipone手机的介绍,在后台修改了,过一段时间,页面才同步过来,虽然是最终一致性,但是对我们的业务并没有什么影响,这些数据能容忍缓存的不一致。如果想要实时的一致性,也可以去使用canal订阅binlog的方式。
3、缓存数据+过期时间也足够解决大部分业务对于缓存的要求。
4、通过加锁保证并发读写,写写的时候按顺序排好队。读读无所谓。所以适合使用读写锁。(业务不关心 脏数据,允许临时脏数据可忽略);
总结:
- 我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,保证每天拿到当前最新数据即可。
- 害怕脏数据,顶多加个读写锁
- 遇到实时性、一致性要求高的数据,就应该直接查数据库,即使慢点。
- 还可以使用
canal完美的解决缓存一致性的问题。
我们系统的一致性解决方案:
1、缓存的所有数据都有过期时间,数据过期下一次查询触发主动更新
2、读写数据的时候,加上分布式的读写锁。 经常写,经常读,会对系统性能有极大的影响
Redis 为什么是单线程的
官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!)Redis利用队列技术将并发访问变为串行访问
1)绝大部分请求是纯粹的内存操作(非常快速)
2)采用单线程,避免了不必要的上下文切换和竞争条件
3)非阻塞IO优点:
1.速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
2. 支持丰富数据类型,支持string,list,set,sorted set,hash
3.支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
4. 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除如何解决redis的并发竞争key问题
同时有多个子系统去set一个key。这个时候要注意什么呢? 不推荐使用redis的事务机制。因为我们的生产环境,基本都是redis集群环境,做了数据分片操作。你一个事务中有涉及到多个key操作的时候,这多个key不一定都存储在同一个redis-server上。因此,redis的事务机制,十分鸡肋。
(1)如果对这个key操作,不要求顺序: 准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可
(2)如果对这个key操作,要求顺序: 分布式锁+时间戳。 假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
(3) 利用队列,将set方法变成串行访问也可以redis遇到高并发,如果保证读写key的一致性
对redis的操作都是具有原子性的,是线程安全的操作,你不用考虑并发问题,redis内部已经帮你处理好并发的问题了。
对于大量的请求redis是怎么样处理
redis是一个单线程程序,也就说同一时刻它只能处理一个客户端请求;
redis是通过IO多路复用(select,epoll, kqueue,依据不同的平台,采取不同的实现)来处理多个客户端请求的
单线程的redis为什么这么快
(一)纯内存操作
(二)单线程操作,避免了频繁的上下文切换
(三)采用了非阻塞I/O多路复用机制
脑裂
什么是redis的集群脑裂
redis的集群脑裂是指因为网络问题,导致redis master节点跟redis slave节点和sentinel集群处于不同的网络分区,此时因为sentinel集群无法感知到master的存在,所以将slave节点提升为master节点。此时存在两个不同的master节点,就像一个大脑分裂成了两个。集群脑裂问题中,如果客户端还在基于原来的master节点继续写入数据,那么新的master节点将无法同步这些数据,当网络问题解决之后,sentinel集群将原先的master节点降为slave节点,此时再从新的master中同步数据,将会造成大量的数据丢失。
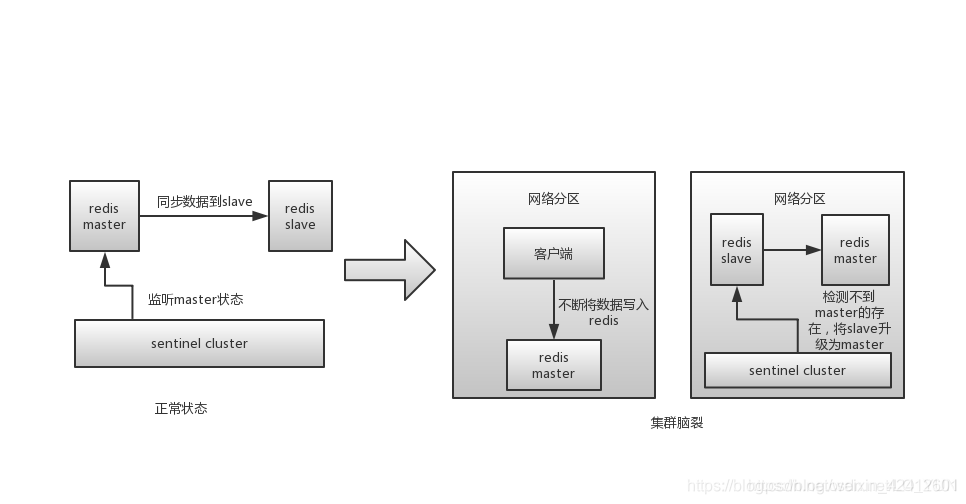
解决方案
redis的配置文件中,存在两个参数
//连接到master的最少slave数量
min-slaves-to-write 3
//slave连接到master的最大延迟时间
min-slaves-max-lag 10
要求至少3个slave节点,且数据复制和同步的延迟不能超过10秒,否则的话master就会拒绝写请求,配置了这两个参数之后,如果发生集群脑裂,原先的master节点接收到客户端的写入请求会拒绝,就可以减少数据同步之后的数据丢失。
注意:较新版本的redis.conf文件中的参数变成了
min-replicas-to-write 3
min-replicas-max-lag 10

















 3651
3651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









