







接前面博客
Scrapy爬虫的第一个实例
演示HTML页面地址:http://python123.io/ws/demo.html
文件名称:demo.html
产生步骤:
1、建立一个Scrapy爬虫工程
选取一个目录,D:\pythoncode,在这个目录中执行建立爬虫工程的命令

工程生成了一个目录:
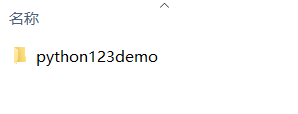

下面逐一介绍这些文件和子目录的作用:
生成的工程目录:
python123demo/ =======>外层目录
- scrapy.cfg =========>部署Scrapy爬虫的配置文件(这里的部署的意思是将这样的爬虫放在特定的服务器上并且在服务器 配置好相应的接口,对于本机的爬虫来讲,不需要改变部署的配置文件)
- python123demo/ =====>Scrapy框架的用户自定义Python代码
_init_.py ========>初始化脚本(用户不需要编写)
items.py ========>Items代码模板(继承类)(对于一般例子用户不需要编写)
middlewares.py ===>Middlewares代码模板(继承类)(若需要拓展,则需要编写)
pipelines.py ======>Pipelines代码模板(继承类)
settings.py =======>Scrapy爬虫的配置文件(需要优化爬虫功能,则需要修改某些配置项)
spiders/ ========>Spiders代码模板目录(继承类)
_init_.py ===>初始文件,无需修改
_pycache_/ ===>缓存目录,无需修改
2、在工程中产生一个Scrapy爬虫
输入命令:scrapy genspider demo python123.io

这条命令的作用是生成一个demo名称的spider,也是仅限于生成一个如下的demo.py文件
如果你出现以下结果,可能是你命令行没有进到python123demo子目录下

此时spiders目录下会多一个demo.py文件
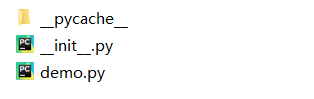
事实上,也可以手工来生成这个文件(和上面所说命令作用相对应)
看一下demo.py文件:

这个类叫什么没关系,必须是继承scrapy.Spider的字类
allowed_domains:约束只能爬取这个域名以下的链接
parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求
3、配置产生的spider爬虫
修改demo.py文件
要实现的功能:将返回的html存成文件,修改parse()
修改代码如下:

4、运行爬虫,获取网页
执行命令:
![]()
捕获的页面存储在这:

其实上述demo.py是scrapy提供的一个简化版代码,完整版代码是:

上述代码等价,我们需要知道yield关键字的含义
下面介绍yield关键字:
yield<---------->生成器
生成器是一个不断产生值的函数;
包含yield语句的函数是一个生成器;
生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值
给一个例子: 等价普通写法:
def gen(n): def square(n):
for i in range(n): ls=[i**2 for i in range(n)]
yield i**2 ========= return ls
for i in gen(5): for i in square(5):
print(i," ",end="") print(i," ",end="")
打印结果为:
0 1 4 9 16
生成器相比一次列出所有内容(普通写法)的优势:
①更节省存储空间;
②响应更迅速;
③使用更灵活
生成器函数一次调用产生一个值后冻结,等到再次调用时再接着运行















 2692
2692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









