






 本文介绍了如何使用Hutool库中的Tree对象将树状数据导出到Excel,通过先将数据平铺并生成散列,然后合并相邻列,实现了数据的自动合并,即使在有同级节点的情况下也能保持简洁的表格结构。
本文介绍了如何使用Hutool库中的Tree对象将树状数据导出到Excel,通过先将数据平铺并生成散列,然后合并相邻列,实现了数据的自动合并,即使在有同级节点的情况下也能保持简洁的表格结构。
目的
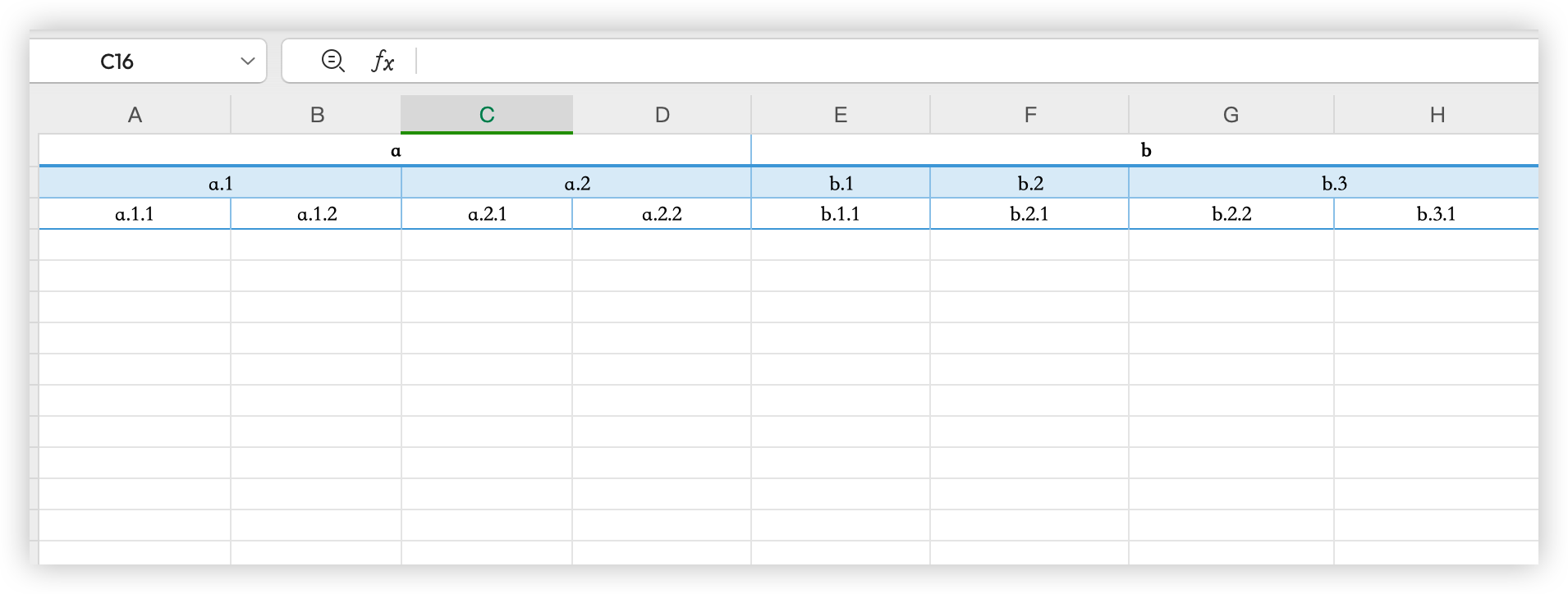
将树状数据导出到excel中,并自动合并单元格(数据传递采用了hutool中Tree对象,方便直接使用)
转后excel示例
![]()
使用
import cn.hutool.core.lang.tree.Tree;
@GetMapping("/tree/download/template")
public void template(HttpServletResponse response) throws IOException {
// 树状行数据
List<TreeData> list = new ArrayList<>();
K k = ReflectUtils.invokeGetter(list.get(0), "parentId");
List<Tree<Long>> build = TreeUtil.build(list, k, (data, tree) ->
tree.setId(data.getId())
.setParentId(data.getParentId())
.setName(data.getName())
.setWeight(data.getOrderNum()));
try (Workbook workbook = ExcelUtil.writeWorkbookTree(build)) {
// todo Workbook... 按需...
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
workbook.write(outputStream);
response.setContentType("application/vnd.ms-excel");
response.setHeader(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=template_"+ DateUtil.format(new Date(), "yyyy") +".xlsx");
OutputStream responseOutputStream = response.getOutputStream();
responseOutputStream.write(outputStream.toByteArray());
} catch (IOException e) {
e.printStackTrace();
}
}
// TreeData示例 基础树形表结构 其他按需
public class TreeData {
private Long id;
private String name;
private Long parentId;
private Integer orderNum;
}
![]()
工具类方法
public class ExcelUtil {
/**
* 将树状数据写入到workbook中
* 注意!!!该工具方法为了灵活使用,故返回Workbook实例以供后续自定义处理,使用workbook时注意关闭
* @param list
* @return
* @param <T>
*/
public static <T> Workbook writeWorkbookTree(List<Tree<T>> list) {
return ExcelUtil.writeWorkbookTree(list, 0);
}
public static <T> Workbook writeWorkbookTree(List<Tree<T>> list, Integer colIndexStart) {
List<List<String>> allNodeNames = getAllNodeNames(list);
Workbook workbook = new XSSFWorkbook();
CellStyle centerStyleHead = workbook.createCellStyle();
centerStyleHead.setAlignment(HorizontalAlignment.CENTER);
centerStyleHead.setVerticalAlignment(VerticalAlignment.CENTER);
Font fontHead = workbook.createFont();
fontHead.setFontHeightInPoints((short) 13);
fontHead.setBold(true);
centerStyleHead.setFont(fontHead);
try {
Sheet sheet = workbook.createSheet("Sheet1");
int rowIndex = 0;
int maxRowIndex = allNodeNames.stream().mapToInt(List::size).max().orElse(0);
while (rowIndex < maxRowIndex) {
Row row = sheet.createRow(rowIndex);
int colIndex = colIndexStart;
boolean toBreak = false;
for (List<String> rowData : allNodeNames) {
if (rowData.size() - 1 < rowIndex) {
toBreak = true;
break;
}
String value = rowData.get(rowIndex);
Cell cell = row.createCell(colIndex);
cell.setCellValue(value);
cell.setCellStyle(centerStyleHead);
colIndex++;
}
if (toBreak) {
break;
}
rowIndex++;
}
mergeAdjacentCells(sheet);
for (int i = 0; i < sheet.getRow(0).getLastCellNum(); i++) {
sheet.autoSizeColumn(i);
}
return workbook;
}catch (Exception e) {
e.printStackTrace();
}
return null;
}
/**
* 获取树状数据中散列节点名称
* @param nodes
* @return
* @param <T>
*/
public static <T> List<List<String>> getAllNodeNames(List<Tree<T>> nodes) {
List<List<String>> result = new ArrayList<>();
for (Tree root : nodes) {
dfs(root, new ArrayList<>(), result);
}
return result;
}
/**
* 自动合并sheet中左侧相同列
* @param sheet
*/
private static void mergeAdjacentCells(Sheet sheet) {
int lastRowNum = sheet.getLastRowNum();
int lastColNum = sheet.getRow(0).getLastCellNum();
for (int row = 0; row <= lastRowNum; row++) {
int startCol = 0;
for (int col = 1; col < lastColNum; col++) {
String value = sheet.getRow(row).getCell(col).getStringCellValue();
String leftValue = sheet.getRow(row).getCell(col - 1).getStringCellValue();
if (!value.equals(leftValue)) {
// 不相等,合并之前的列
if (col - startCol > 1) {
CellRangeAddress newMergedRegion = new CellRangeAddress(row, row, startCol, col - 1);
if (!isOverlapping(sheet, newMergedRegion)) {
sheet.addMergedRegion(newMergedRegion);
}
}
startCol = col;
}
// 当前值为空的时候记录的起始列自增——不参与合并
if (StringUtils.isBlank(value)) {
startCol ++;
}
}
// 处理行末尾相邻相同的情况
if (lastColNum - startCol > 1) {
CellRangeAddress newMergedRegion = new CellRangeAddress(row, row, startCol, lastColNum - 1);
if (!isOverlapping(sheet, newMergedRegion)) {
sheet.addMergedRegion(newMergedRegion);
}
}
}
}
/**
* 检查合并范围是否与已有的合并范围重叠
*/
private static boolean isOverlapping(Sheet sheet, CellRangeAddress newMergedRegion) {
for (int i = 0; i < sheet.getNumMergedRegions(); i++) {
CellRangeAddress existingMergedRegion = sheet.getMergedRegion(i);
if (newMergedRegion.isInRange(existingMergedRegion.getFirstRow(), existingMergedRegion.getFirstColumn())
|| newMergedRegion.isInRange(existingMergedRegion.getLastRow(), existingMergedRegion.getLastColumn())) {
// 重叠
return true;
}
}
return false;
}
/**
* 使用深度优先搜索 收集底层节点完整路径
* @param node
* @param currentPath
* @param result
*/
private static void dfs(Tree node, List<String> currentPath, List<List<String>> result) {
if (node == null) {
return;
}
// 添加当前节点的名称到当前路径
currentPath.add(node.getName()+"");
// 如果是叶子节点,将当前路径添加到结果列表
if (CollectionUtil.isEmpty(node.getChildren())) {
result.add(new ArrayList<>(currentPath));
}
// 递归遍历子节点
List<Tree> children = Optional.ofNullable(node.getChildren()).orElseGet(() -> Collections.EMPTY_LIST);
for (Tree child : children) {
dfs(child, currentPath, result);
}
// 回溯,移除当前节点的名称,以便尝试其他路径
currentPath.remove(currentPath.size() - 1);
}
}
实现思路说明
本想采用写入数据时就可以合并单元格,后发现因头部列数据是动态数据,每个非叶子节点的数量都会引起当前节点的所有父级(包括父同级节点)以上的节点,合并单元格数量的变化,写起来较为复杂,故舍弃
本文采用了:1.生成散列数据平铺开在excel中,2.再进行左侧相邻元素合并列。如有同级节点但属于不同父节点,又正好处在相邻单元格且有着相同元素的情况,则需要进行代码改进(基本上很少有此情况,本人使用无此情况,故不需要考虑),改进可为整体思路不变,在形成散列数据时,每一个节点都拥有父元素的唯一标识,然后再去除excel整单元格的父元素数据,保留原数据即可。(父的标识如果用批注也可,只要能做区分)

















 3437
3437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









