




文章目录
1、Select 语句完整的执行顺序
(1)from 子句组装来自不同数据源的数据;
(2)where 子句基于指定的条件对记录行进行筛选;
(3)group by 子句将数据划分为多个分组;
(4)使用聚集函数进行计算;
(5)使用 having 子句筛选分组;
(6)计算所有的表达式;
(7)select 的字段;
(8)使用order by 对结果集进行排序。
2、MySQL事务
事务的基本要素(ACID)
- 原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位
- 一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
- 隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
- 持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
MySQL事务隔离级别:
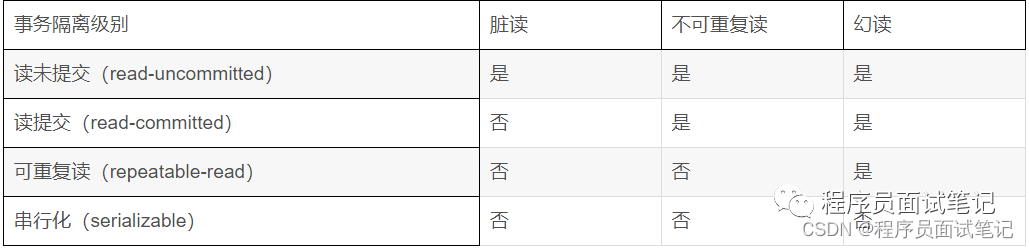
事务的并发问题
脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致
幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
如何解决脏读、幻读、不可重复读
脏读:隔离级别为 读提交、可重复读、串行化可以解决脏读
不可重复读:隔离级别为可重复读、串行化可以解决不可重复读
幻读:隔离级别为串行化可以解决幻读、通过MVCC + 区间锁可以解决幻读
小结:
不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
3、MyISAM和InnoDB的区别

4、悲观锁和乐观锁的怎么实现
悲观锁:select…for update是MySQL提供的实现悲观锁的方式。
例如:select price from item where id=100 for update
此时在items表中,id为100的那条数据就被我们锁定了,其它的要执行select price from items where id=100 for update的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其它事务修改。MySQL有个问题是select…for update语句执行中所有扫描过的行都会被锁上,因此在MySQL中用悲观锁务必须确定走了索引,而不是全表扫描,否则将会将整个数据表锁住。
乐观锁:乐观锁相对悲观锁而言,它认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回错误信息,让用户决定如何去做。
利用数据版本号(version)机制是乐观锁最常用的一种实现方式。一般通过为数据库表增加一个数字类型的 “version” 字段,当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值+1。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据,返回更新失败。
举例:
//1: 查询出商品信息
select (quantity,version) from items where id=100;
//2: 根据商品信息生成订单
insert into orders(id,item_id) values(null,100);
//3: 修改商品的库存
update items set quantity=quantity-1,version=version+1 where id=100 and version=#{
version};
5、聚簇索引与非聚簇索引区别
都是B+树的数据结构
聚簇索引:将数据存储与索引放到了一块、并且是按照一定的顺序组织的,找到索引也就找到了数据,数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的
非聚簇索引叶子节点不存储数据、存储的是数据行地址,也就是说根据索引查找到数据行的位置再取磁盘查找数据,这个就有点类似一本书的目录,比如我们要找第三章第一节,那我们先在这个目录里面找,找到对应的页码后再去对应的页码看文章。
优势:
1、查询通过聚簇索引可以直接获取数据,相比非聚簇索引需要第二次查询(非覆盖索引的情况下)效率要高
2、聚簇索引对于范围查询的效率很高,因为其数据是按照大小排列的
3、聚簇索引适合用在排序的场合,非聚簇索引不适合
劣势
1、维护索引很昂贵,特别是插入新行或者主键被更新导至要分页(pagesplit)的时候。建议在大量插入新行后,选在负载较低的时间段,通过OPTIMIZETABLE优化表,因为必须被移动的行数据可能造成碎片。使用独享表空间可以弱化碎片
2、表因为使用uuId(随机ID)作为主键,使数据存储稀疏,这就会出现聚簇索引有可能有比全表扫面更慢,所以建议使用int的auto_increment作为主键
3、如果主键比较大的话,那辅助索引将会变的更大,因为辅助索引的叶子存储的是主键值,过长的主键值,会导致非叶子节点占用占用更多的物理空间
6、什么情况下mysql会索引失效
失效条件:
where 后面使用函数
使用or条件
模糊查询 %放在前边
类型转换
组合索引 (最佳左前缀匹配原则)
#查询条件用到了计算或者函数
explain SELECT * from test_slow_query where age = 20
explain SELECT * from test_slow_query where age +10 = 30
#模糊查询
EXPLAIN SELECT * from test_slow_query where NAME like '%吕布'
EXPLAIN SELECT * from test_slow_query where NAME like '%吕布%'
EXPLAIN SELECT * from test_slow_query where NAME like '吕布&'
#用到了or条件
EXPLAIN SELECT * from test_slow_query where NAME = '吕布' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4695
4695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









