







zookeeper之恢复snapshot
前言
本文是基于zookeeper集群启动过程分析(https://blog.csdn.net/weixin_42442768/article/details/109247622),对zk从磁盘中读取文件并恢复为内存中的zk数据结构这一过程进行源码分析,本文主要分析snapshot的反序列化过程,事务日志的恢复将在下一篇讲解。
源码分析
前文分析了QuorumPeer类的loadDataBase()方法,本文对其中的zkDb.loadDataBase()方法进行分析。
首先来看一下QuorumPeer类中的成员变量zkDb:
/**
* ZKDatabase is a top level member of quorumpeer
* which will be used in all the zookeeperservers
* instantiated later. Also, it is created once on
* bootup and only thrown away in case of a truncate
* message from the leader
*/
private ZKDatabase zkDb;
该变量在QuorumPeer类初始化时进行了赋值,ZKDatabase中本文主要关注这几个变量:
protected DataTree dataTree;
protected ConcurrentHashMap<Long, Integer> sessionsWithTimeouts;
protected FileTxnSnapLog snapLog;
DataTree是zk存储数据信息的数据结构,sessionWithTimeouts存储session信息,FileTxnSnapLog是辅助恢复快照和事务日志文件的类,具体内容在数据结构部分详解。
将磁盘中的文件以zkDatabase结构恢复到内存中
进入正题,ZKDatabase类的loadDataBase方法:
public long loadDataBase() throws IOException {
long zxid = snapLog.restore(dataTree, sessionsWithTimeouts, commitProposalPlaybackListener);
initialized = true;
return zxid;
}
通过辅助类FileTxnSnapLog的对象snapLog进一步恢复数据,返回最新的zxid,跟进restore方法:
/**
* this function restores the server
* database after reading from the
* snapshots and transaction logs
* @param dt the datatree to be restored
* @param sessions the sessions to be restored
* @param listener the playback listener to run on the
* database restoration
* @return the highest zxid restored
* @throws IOException
*/
public long restore(DataTree dt, Map<Long, Integer> sessions,
PlayBackListener listener) throws IOException {
long deserializeResult = snapLog.deserialize(dt, sessions);
FileTxnLog txnLog = new FileTxnLog(dataDir);
if (-1L == deserializeResult) {
/* this means that we couldn't find any snapshot, so we need to
* initialize an empty database (reported in ZOOKEEPER-2325) */
if (txnLog.getLastLoggedZxid() != -1) {
throw new IOException(
"No snapshot found, but there are log entries. " +
"Something is broken!");
}
/* TODO: (br33d) we should either put a ConcurrentHashMap on restore()
* or use Map on save() */
save(dt, (ConcurrentHashMap<Long, Integer>)sessions);
/* return a zxid of zero, since we the database is empty */
return 0;
}
return fastForwardFromEdits(dt, sessions, listener);
}
这里主要做了三件事情:
- 反序列化快照文件,恢复到zkDatabase中
- 如果没有找到快照文件,将zkDatabase中的DataTree和session信息生成一个快照落入磁盘
- 快速从事务日志中获取最新zxid返回(这部分将单独写一篇文章分析)
从最新快照文件中反序列化DataTree
跟到FileSnap类中的deserialize方法:
/**
* deserialize a data tree from the most recent snapshot
* @return the zxid of the snapshot
*/
public long deserialize(DataTree dt, Map<Long, Integer> sessions)
throws IOException {
// we run through 100 snapshots (not all of them)
// if we cannot get it running within 100 snapshots
// we should give up
List<File> snapList = findNValidSnapshots(100);
if (snapList.size() == 0) {
return -1L;
}
File snap = null;
boolean foundValid = false;
for (int i = 0, snapListSize = snapList.size(); i < snapListSize; i++) {
snap = snapList.get(i);
LOG.info("Reading snapshot " + snap);
try (InputStream snapIS = new BufferedInputStream(new FileInputStream(snap));
CheckedInputStream crcIn = new CheckedInputStream(snapIS, new Adler32())) {
InputArchive ia = BinaryInputArchive.getArchive(crcIn);
deserialize(dt, sessions, ia);
long checkSum = crcIn.getChecksum().getValue();
long val = ia.readLong("val");
if (val != checkSum) {
throw new IOException("CRC corruption in snapshot : " + snap);
}
foundValid = true;
break;
} catch (IOException e) {
LOG.warn("problem reading snap file " + snap, e);
}
}
if (!foundValid) {
throw new IOException("Not able to find valid snapshots in " + snapDir);
}
dt.lastProcessedZxid = Util.getZxidFromName(snap.getName(), SNAPSHOT_FILE_PREFIX);
return dt.lastProcessedZxid;
}
这里做了两件事情:
- 拿到默认100个有效的快照,并按zxid降序排列
- 反序列化最新有效的快照文件,返回zxid
首先看一下findNValidSnapshots方法:
private List<File> findNValidSnapshots(int n) throws IOException {
List<File> files = Util.sortDataDir(snapDir.listFiles(), SNAPSHOT_FILE_PREFIX, false);
int count = 0;
List<File> list = new ArrayList<File>();
for (File f : files) {
// we should catch the exceptions
// from the valid snapshot and continue
// until we find a valid one
try {
if (Util.isValidSnapshot(f)) {
list.add(f);
count++;
if (count == n) {
break;
}
}
} catch (IOException e) {
LOG.info("invalid snapshot " + f, e);
}
}
return list;
}
这里需要注意两点:
- 先获取所有以snapshot开头的文件并按文件名中的zxid降序排列
- 对文件进行了粗略的合法有效性校验
a) 文件至少10bytes,这是根据snap头文件大小估算的
b) 文件必须以/结尾
关于dataDir和dataLogDir的说明
snapDir目录是存储快照的文件目录,是从QuorumPeerConfig配置类赋值过来的,而默认的zk配置zoo_sample.cfg(zoo.cfg)中只有dataDir,所以默认情况下快照文件和事务日志文件都存储在dataDir目录下,如下图所示。可以通过配置dataLogDir使两类文件分离,从源码上看这样做的好处之一是,File.listFiles的时候只获取快照文件,不用过滤事务日志文件。

Adler32校验
回到FileSnap类的deserialize方法,在获取snap文件后,建立输入流,读取文件并反序列化到zkDatabase中。
try (InputStream snapIS = new BufferedInputStream(new FileInputStream(snap));
CheckedInputStream crcIn = new CheckedInputStream(snapIS, new Adler32())) {
InputArchive ia = BinaryInputArchive.getArchive(crcIn);
deserialize(dt, sessions, ia);
long checkSum = crcIn.getChecksum().getValue();
long val = ia.readLong("val");
if (val != checkSum) {
throw new IOException("CRC corruption in snapshot : " + snap);
}
foundValid = true;
break;
} catch (IOException e) {
LOG.warn("problem reading snap file " + snap, e);
}
这一段的功能是建立输入流,并使用Adler32算法进行校验,经过deserialize后,对快照文件中的val值和Adler32的getValue计算结果进行匹配,如果校验通过,则该恢复该快照信息到内存中。
需要说明的是快照文件中的val值,是在生成快照文件时,以序列化方式update Adler32算法的Value写入的。
Adler32算法类似循环冗余校验法CRC,通过变量名可以看出(crcIn),Adler32算法的优势是以准确性换取时间,感兴趣可以了解一下。
真正反序列化快照文件
主要来看deserialize方法:
public void deserialize(DataTree dt, Map<Long, Integer> sessions,
InputArchive ia) throws IOException {
FileHeader header = new FileHeader();
header.deserialize(ia, "fileheader");
if (header.getMagic() != SNAP_MAGIC) {
throw new IOException("mismatching magic headers "
+ header.getMagic() +
" != " + FileSnap.SNAP_MAGIC);
}
SerializeUtils.deserializeSnapshot(dt,ia,sessions);
}
反序列化快照文件分为两步,反序列化文件头并进行校验,反序列化快照信息。
快照文件的头信息主要有三个变量:
| 变量名 | 类型 | 含义 |
|---|---|---|
| magic | int | 魔数 |
| version | int | 版本 |
| dbid | long | 未知 |
快照文件的魔数是ZKSN,version为2,dbid为-1。
我们可以看一下快照文件的内容,进入zkData/version-2,执行hexdump -C snapshot.xx 命令以16进制查看快照文件,5a4b534e 为 ZKSN,00000002 为version,8字节的ff为-1,即dbid。顺便可以看下文件以2f结尾,即/。
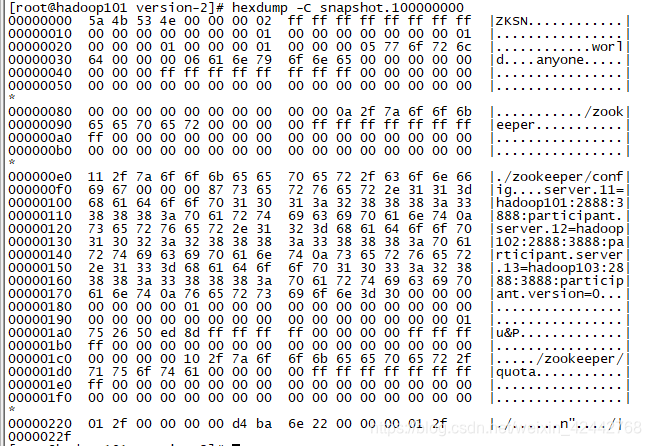
反序列化快照文件内容到DataTree
反序列化核心是读取文件中字段值,写入DataTree中的结构中,涉及权限、路径、普通节点、字典树、临时节点等内容,接下来简要进行分析:
public void deserialize(InputArchive ia, String tag) throws IOException {
aclCache.deserialize(ia);
nodes.clear();
pTrie.clear();
String path = ia.readString("path");
while (!"/".equals(path)) {
DataNode node = new DataNode();
ia.readRecord(node, "node");
nodes.put(path, node);
synchronized (node) {
aclCache.addUsage(node.acl);
}
int lastSlash = path.lastIndexOf('/');
if (lastSlash == -1) {
root = node;
} else {
String parentPath = path.substring(0, lastSlash);
DataNode parent = nodes.get(parentPath);
if (parent == null) {
throw new IOException("Invalid Datatree, unable to find " +
"parent " + parentPath + " of path " + path);
}
parent.addChild(path.substring(lastSlash + 1));
long eowner = node.stat.getEphemeralOwner();
EphemeralType ephemeralType = EphemeralType.get(eowner);
if (ephemeralType == EphemeralType.CONTAINER) {
containers.add(path);
} else if (ephemeralType == EphemeralType.TTL) {
ttls.add(path);
} else if (eowner != 0) {
HashSet<String> list = ephemerals.get(eowner);
if (list == null) {
list = new HashSet<String>();
ephemerals.put(eowner, list);
}
list.add(path);
}
}
path = ia.readString("path");
}
nodes.put("/", root);
// we are done with deserializing the
// the datatree
// update the quotas - create path trie
// and also update the stat nodes
setupQuota();
aclCache.purgeUnused();
}
alCache是zookeeper的权限缓存类,存储权限相关信息,这里不深入解析nodes是DataTree中维护<文件路径,数据节点>信息的hashmap,使得用户可以根据路径查询相关数据pTrie是字典树结构,存储整个树信息- while循环中主要是拿到每个路径和节点信息,存储到DataTree中
- DataNode的stat变量是节点的一些持久化信息,在数据结构部分给出具体内容
ephemeralOwner是用来表示一个节点是临时节点,并且是由哪个session创建的;而这里的EphemeralType是个枚举类型,用来扩展ephemeralOwner的具体类型,可以通过zookeeper.extendedTypesEnabled来控制扩展的开关,扩展的含义包括具体的EphemeralType和该类型的目的。containers是用来存所有容器类型的临时节点集合,其最后一个子节点被删除时,该节点会被删除ttls是存有过期时间的临时节点集合ephemerals存放所有其他类型的临时节点,以<sessionid,其他临时节点集合>的形式存储setupQuota方法主要功能是构造字典树并更新节点的配额信息(/zookeeper/quota下配置,配额主要是对子节点数量和节点数据大小的限制)alCache.purgeUnused是将无用的信息从alCache的referenceCounter中清除掉,这里与步骤1的添加功能对照来看,这次解析的信息都不会被清除,只有执行deleteNode操作和setACL操作中会产生无用信息。
至此,snapshot的反序列化过程完成,从文件名字中取出zxid返回即可。
序列化DataTree和session到快照中
回到FileTxnSnapLog的restore方法:
public long restore(DataTree dt, Map<Long, Integer> sessions,
PlayBackListener listener) throws IOException {
long deserializeResult = snapLog.deserialize(dt, sessions);
FileTxnLog txnLog = new FileTxnLog(dataDir);
if (-1L == deserializeResult) {
/* this means that we couldn't find any snapshot, so we need to
* initialize an empty database (reported in ZOOKEEPER-2325) */
if (txnLog.getLastLoggedZxid() != -1) {
throw new IOException(
"No snapshot found, but there are log entries. " +
"Something is broken!");
}
/* TODO: (br33d) we should either put a ConcurrentHashMap on restore()
* or use Map on save() */
save(dt, (ConcurrentHashMap<Long, Integer>)sessions);
/* return a zxid of zero, since we the database is empty */
return 0;
}
return fastForwardFromEdits(dt, sessions, listener);
}
save操作为序列化过程,和反序列化相反,列出源码简要说明序列化过程:
public void save(DataTree dataTree,
ConcurrentHashMap<Long, Integer> sessionsWithTimeouts)
throws IOException {
long lastZxid = dataTree.lastProcessedZxid;
File snapshotFile = new File(snapDir, Util.makeSnapshotName(lastZxid));
LOG.info("Snapshotting: 0x{} to {}", Long.toHexString(lastZxid),
snapshotFile);
snapLog.serialize(dataTree, sessionsWithTimeouts, snapshotFile);
}
根据zxid创建文件名,根据文件名和快照路径生成快照文件。
跟进serialize方法:
public synchronized void serialize(DataTree dt, Map<Long, Integer> sessions, File snapShot)
throws IOException {
if (!close) {
try (OutputStream sessOS = new BufferedOutputStream(new FileOutputStream(snapShot));
CheckedOutputStream crcOut = new CheckedOutputStream(sessOS, new Adler32())) {
//CheckedOutputStream cout = new CheckedOutputStream()
OutputArchive oa = BinaryOutputArchive.getArchive(crcOut);
FileHeader header = new FileHeader(SNAP_MAGIC, VERSION, dbId);
serialize(dt, sessions, oa, header);
long val = crcOut.getChecksum().getValue();
oa.writeLong(val, "val");
oa.writeString("/", "path");
sessOS.flush();
}
}
}
创建输出流,同样采用Adler32算法在序列化后写入val值,校验在反序列化过程中。
继续看serialize方法:
protected void serialize(DataTree dt,Map<Long, Integer> sessions,
OutputArchive oa, FileHeader header) throws IOException {
// this is really a programmatic error and not something that can
// happen at runtime
if(header==null)
throw new IllegalStateException(
"Snapshot's not open for writing: uninitialized header");
header.serialize(oa, "fileheader");
SerializeUtils.serializeSnapshot(dt,oa,sessions);
}
序列化文件头信息,将DataTree、session信息写入快照,后面流程和反序列化部分类似,不作详细介绍了。
至此,整个快照已经恢复到内存中的zkDatabase中了。
查看snapshot的可视化命令
命令如下
java -classpath .:/opt/module/apache-zookeeper-3.5.8-bin/lib/zookeeper-3.5.8.jar:/opt/module/apache-zookeeper-3.5.8-bin/lib/zookeeper-jute-3.5.8.jar:/opt/module/apache-zookeeper-3.5.8-bin/lib/slf4j-api-1.7.25.jar:/opt/module/apache-zookeeper-3.5.8-bin/lib/slf4j-log4j12-1.7.25.jar:/opt/module/apache-zookeeper-3.5.8-bin/lib/log4j-1.2.17.jar org.apache.zookeeper.server.SnapshotFormatter snapshot.XXX
这个命令需要按照不同的安装版本进行调整,到lib目录下观察对应jar包是否存在以及版本信息。
这是zookeeper提供了专门查看日志&快照的api工具,查看信息如下:
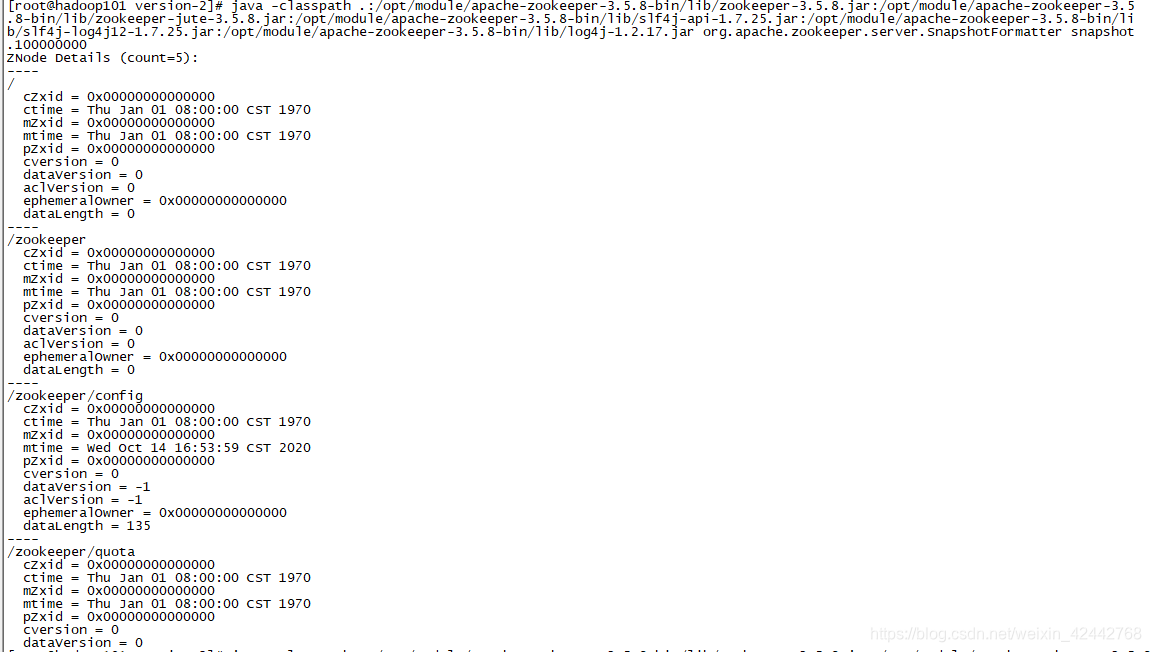
总结
- snapshot文件存储位置默认是
dataDir,每次查找最多100个有效文件按zxid排序,选择最新有效快照恢复 - 快照信息会恢复到
zkDatabase类中,其中包括DataTree、FileTxnSnapLog、存储session的map - snapshot文件命名是根据zxid,头信息中魔数为
ZKSN - 如果没找到snapshot会序列化一个snapshot
- 反序列化采用
Adler32算法校验,序列化写入Adler32算法的val值














 775
775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









