






项目1:
bikes
#读取文件
import pandas as pd
#读取文件
#pd.read_csv
bikes=pd.read_csv("../Anaconda3/bikes.csv")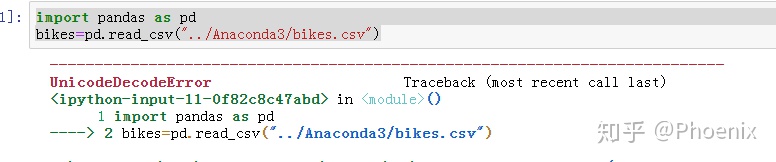
- 如果发现出错类型是UnicodeDecodeError,可能是原来的数据编码出了问题,我们1需要重新改一下编码
import pandas as pd
bikes=pd.read_csv("../Anaconda3/bikes.csv",encoding="latin-1")
bikes.head()
这里的encoding就实现了对原来的编码的转换
head()函数表示看前几行的数据
#修改参数
import pandas as pd
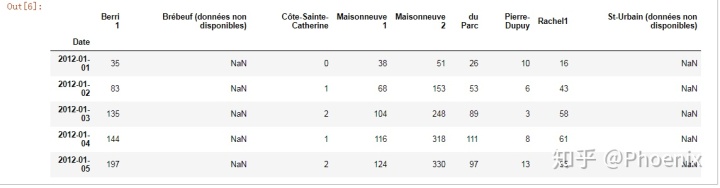
bikes=pd.read_csv("../Anaconda3/bikes.csv",sep=";",parse_dates=["Date"],
encoding="latin-1",dayfirst=True,index_col="Date")
bikes.head()- 将列分隔符改成 ;
- 将编码改为 latin1 (默认为 utf-8 )
- 解析 Date 列中的日期
- 告诉它我们的日期将日放在前面,而不是月
- 将索引设置为 Date
- 这里要注意的是这个是换行符,当一行内字符数多的时候,需要换行
#缺失值删除
#如果某一行的数值全部缺失,才需要扔掉
bikes.dropna(how="all").head()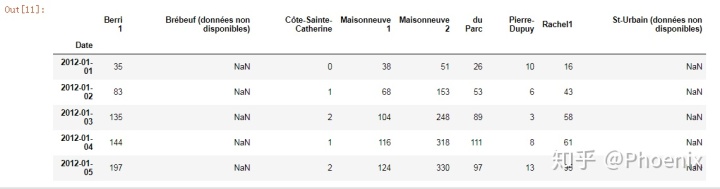
#填充缺失值
bikes.T.fillna(bikes.T.mean(0)).T.head()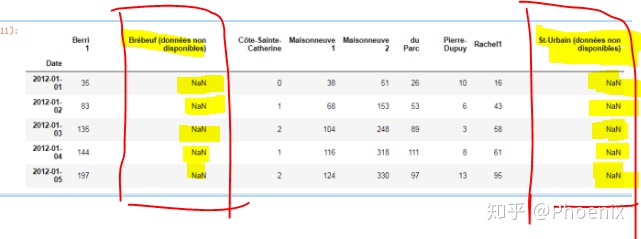
这里用T转置是因为缺失的数据在一列上,如果是在一行,就没有必要转置
#选择数据
比如要选某一列数据
berri_bikes=bikes[["Berri 1"]]
berri_bikes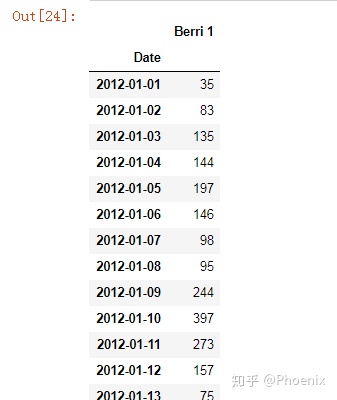
#按weekday给berri_bikes分组并聚合求平均值
berri_bikes.groupby(berri_bikes.index.weekday).mean()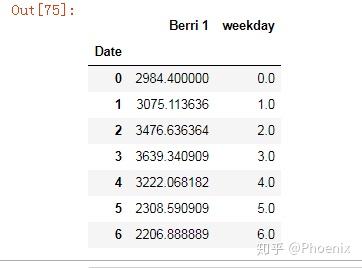
#查看表格的索引
berri_bikes.index
#查看索引中的weekday
berri_bikes.index.weekday
#增加weekday这一列
berri_bikes.loc[:,"weekday"]=berri_bikes.index.weekday
berri_bikes.head()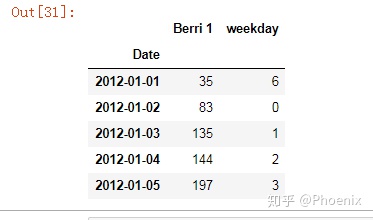
#计算不同weekday对应的berri_bikes的平均值
weekday_counts=berri_bikes.groupby("weekday").mean()
weekday_counts
#修改索引值
weekday_counts.index=["Monday","Tuesday","Wednesday","Thursday","Friday","Saturday","Sunday"]
weekday_counts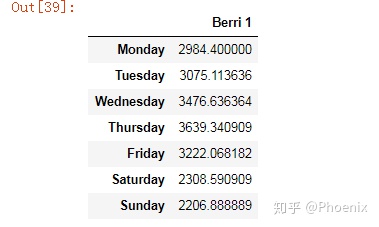
#绘图
%matplotlib inline
weekday_counts.plot(kind="bar")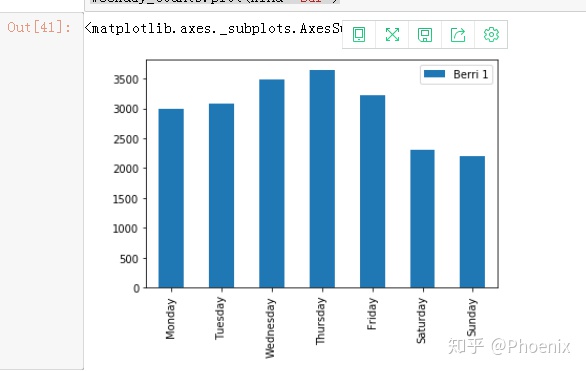















 394
394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









