









Java集合篇
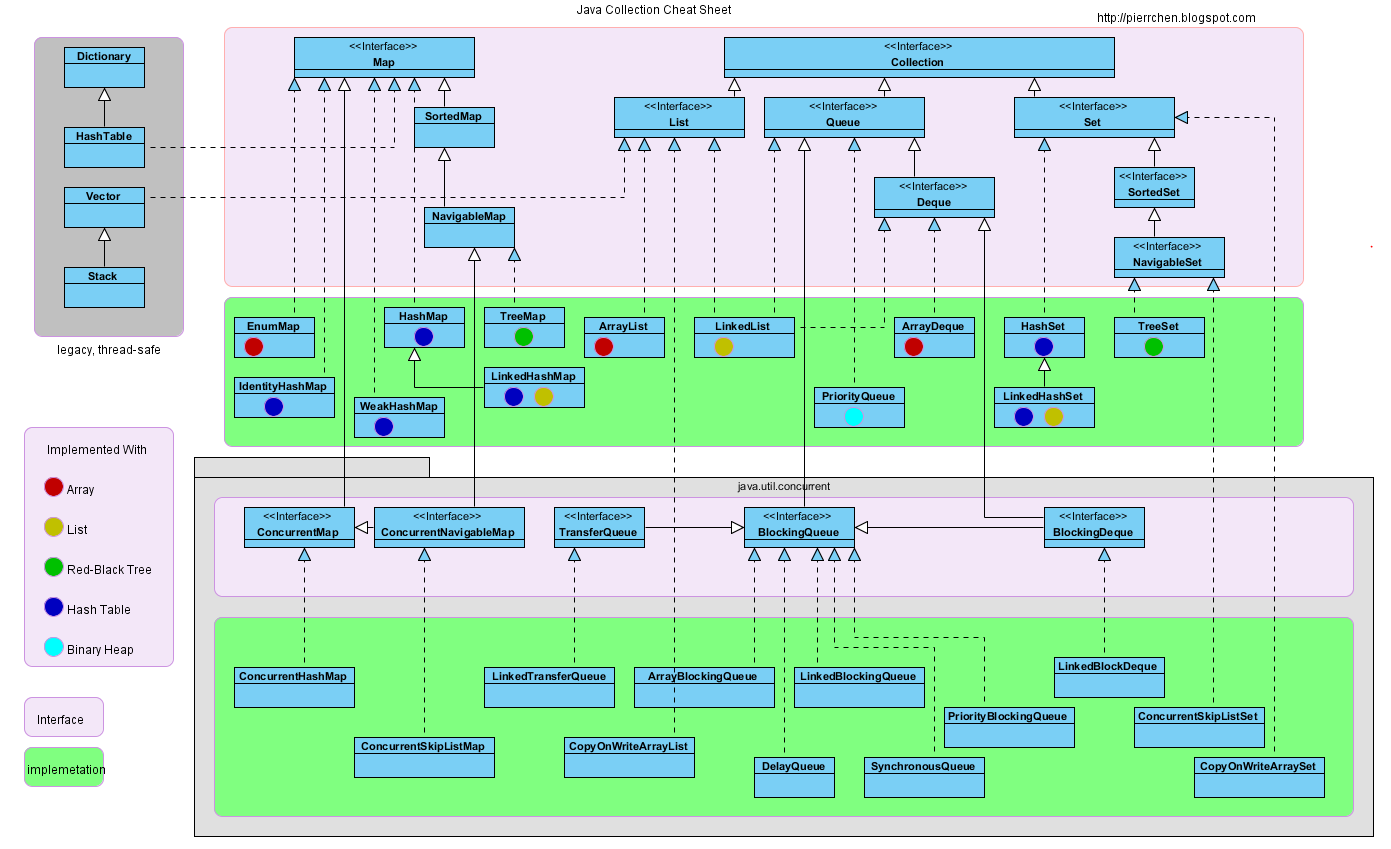
一、集合整体概览图
二、概念
1、什么是集合?
Java集合是一个用来存放对象(就是存放数据的容器)的容器,存储对象信息。所有集合类都位于【java.util】包下,但支持多线程的集合类位于【java.util.concurrent】包下。
应当注意:
- 集合只能存放对象(实际上是对象名,即指向地址的指针)。基本数据类型的数据放入集合中会自动装箱,转换成对应的包装类类型存入集合。
- 集合存放的是多个的对象引用(指向对象的引用),对象本身是放在堆内存。
- 集合存放不同类型、不限数量的数据类型。
2、集合的组成
2.1、接口概览
Collection接口层级:

Map接口层级:

Java集合主要由两个根接口Collection和Map派生出来的,Collection派生出了三个子接口:List、Set、Queue(Java5新增的队列),因此Java集合大致也可分成List、Set、Queue、Map四种接口体系,(注意:Map不是Collection的子接口)。
- Collection存放单一元素。
- Map存放键值对。
总结:
两个根接口---->Collection和Map
四个子接口---->List、Set、Queue、Map
2.2、实现类概览
Collection接口的实现类:

Map接口的实现类:

三、Java集合常见接口及实现类
1、Collection接口常见方法(来源于Java API)
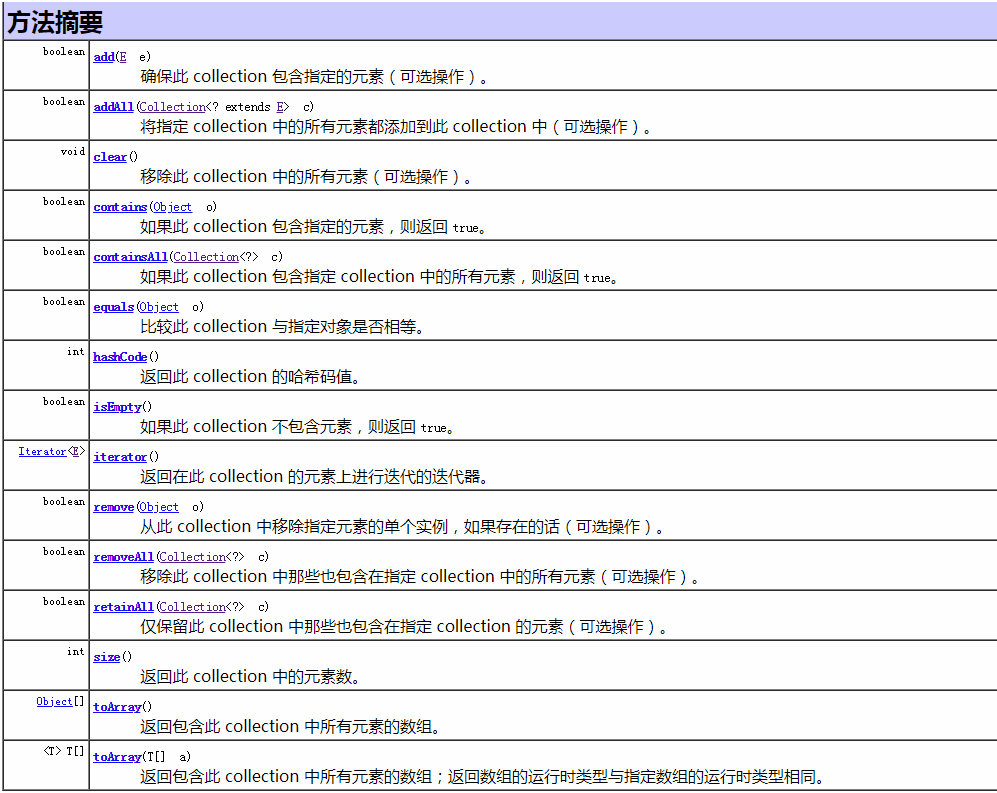
总结:
操作集合可以归结为CRUD。
Collection中常用API在接口里已经定义好,子接口和实现类必须继承。
2、Collection的三个子接口
1、List
-
特点:有序、可重复
-
实现类以及底层:
ArrayList:(动态)数组实现
LinkedList:链表实现
数组和链表的区别:
- 数组随机访问性强、查找速度快
- 链表插入删除速度快
- 数组大小固定,不能动态扩展
- 链表大小不定,扩展灵活
Vector:(动态)数组实现,但是添加了很多的synchronized
Vector和ArrayList的区别:
- 扩容规则:ArrayList扩容1.5倍;Vector默认2倍,没有定义倍数。
- 线程安全:Vector线程安全,所以效率低;ArrayList不是线程安全的。
2、Set
-
特点:无序、不重复
-
每个Set的底层实现对应各自的Map
数值放在map的key上,value放了个PRESENT,是一个静态的Object,相当于place holder,每个key指向这个Object。
-
实现类:HashSet、TreeSet、LinkedHashSet
-
HashSet:HashMap实现。用HashMap的key来储存元素。
集合元素值可以是null。
不能保证元素的顺序。
HashSet不是线程同步的。
-
LinkedHashSet:HashSet+LinkedList
使用链表维护元素的次序,元素的顺序与添加顺序一致。
-
TreeSet:红黑树结构。
可以有序,使用自然排序或者自定义比较器(实现Comparator接口)来排序。
保证元素处于排序状态
默认采用自然排序(实现Comparable接口)。
-
Java常用类中已经实现了Comparable接口的类有以下几个:
♦ BigDecimal、BigDecimal以及所有数值型对应的包装类:按照它们对应的数值大小进行比较。
♦ Charchter:按照字符的unicode值进行比较。
♦ Boolean:true对应的包装类实例大于false对应的包装类实例。
♦ String:按照字符串中的字符的unicode值进行比较。
♦ Date、Time:后面的时间、日期比前面的时间、日期大。
-
3、Queue
是一端进另一端出的线性数据结构;DeQue是两端都可以进出的。
-
子接口:DeQue
-
实现类:LinkedList、ArrayDeque、PriorityQueue
-
API:有两组API,基本功能一样。
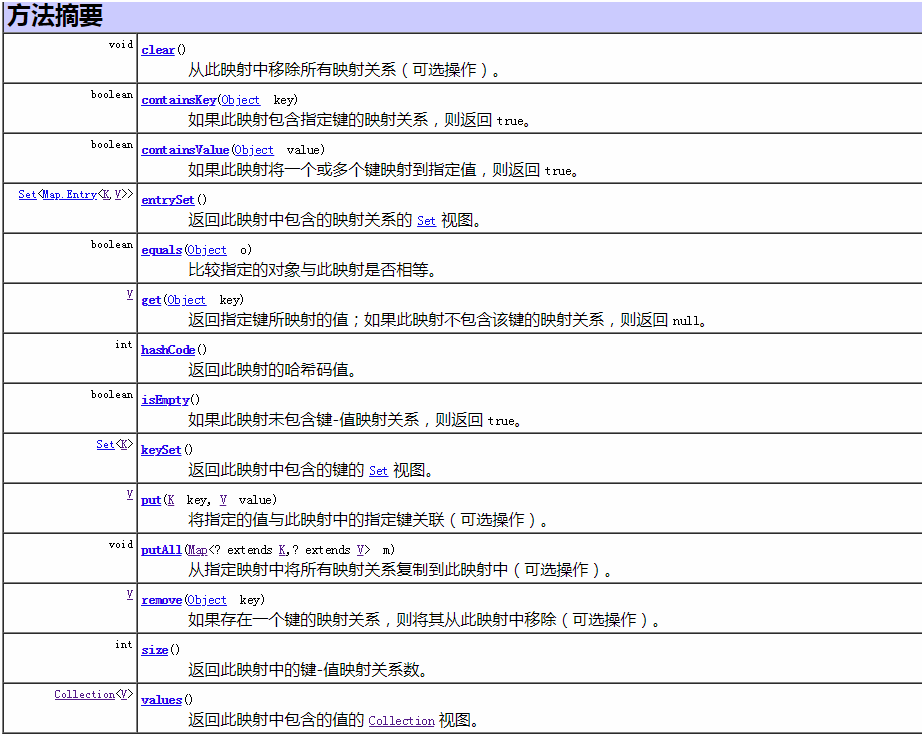
3、Map
Map接口采用键值对Map<K,V>的存储方式。常用实现类有HashMap、LinkedHashMap、TreeMap等。
key值不允许重复,可以为null。
常见API:
1、HashMap
HashMap基于hashing原理,通过put()和get()方法存储和获取对象。
解释:
为了成功的在HashMap和Hashtable中存储和获取对象,用作key的对象必须实现hashCode()方法和equals()方法。
当我们将键值对传递给put()方法时,它调用建对象的hashCode()方法来计算hashCode值,然后找到bucket位置来储存值对象。当获取对象时,通过建对象的equals()方法找到正确的键值对,然后返回对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会存储在链表的下一个节点中。
HashMap与Hashtable:
♦ HashMap是线程不安全,HashTable是线程安全的。
♦ HashMap可以使用null值作为key或value;Hashtable不允许使用null值作为key和value,如果把null放进HashTable中,将会发生空指针异常。
2、LinkedHashMap
使用双向链表来维护key-value对的次序。
3、TreeMap
TreeMap是SortedMap的实现类,是一个红黑树的数据结构,每个key-value对作为红黑树的一个节点。TreeMap存储key-value对时,需要根据key对节点进行排序。
两种排序方式:
♦ 自然排序:TreeMap的所有key必须实现Comparable接口,而且所有的key应该是同一个类的对象,否则会抛出ClassCastException。
♦ 定制排序:创建TreeMap时,传入一个Comparator对象,该对象负责对TreeMap中的所有key进行排序。
各Map实现类的性能分析
♦ HashMap通常比Hashtable(古老的线程安全的集合)要快
♦ TreeMap通常比HashMap、Hashtable要慢,因为TreeMap底层采用红黑树来管理key-value。
♦ LinkedHashMap比HashMap慢一点,因为它需要维护链表来爆出key-value的插入顺序。
ey进行排序。
各Map实现类的性能分析
♦ HashMap通常比Hashtable(古老的线程安全的集合)要快
♦ TreeMap通常比HashMap、Hashtable要慢,因为TreeMap底层采用红黑树来管理key-value。
♦ LinkedHashMap比HashMap慢一点,因为它需要维护链表来爆出key-value的插入顺序。















 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









