









Centos7安装Hadoop伪集群超详细教程
1.安装JDK
笔者这里安装的是jdk1.8.0_211, 如果不会安装jdk的同学可以看我发出来的链接,有详细的教程jdk安装指南
2.安装Hadoop
笔者安装的是hadoop2.7.7,在hadoop官网下载的话速度较慢,笔者下到奔溃,所以笔者给出一个速度较快的网址下载,里面的hadoop版本也比较多
下载完成之后,我们在hadoop的压缩包复制到/usr/local/目录下,输入命令进行解压
tar -xvf hadoop-2.7.7.tar
3.配置hadoop环境变量
解压完成后,查看hadoop的安装路径,在这里,笔者的安装路径是: /usr/local/hadoop-2.7.7
[root@xiaotaotao hadoop-2.7.7]# pwd
/usr/local/hadoop-2.7.7
复制该路径,使用命令打开 vim/etc/profile
在下方添加
HADOOP_HOME=/usr/local/hadoop-2.7.7
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
环境变量配置完成,使用source /etc/profile刷新配置文件
source /etc/profile
4.设置静态IP地址
如果您的IP地址是自动获取,您还需要设置ip为静态的,这是因为我们ip映射的时候,可能会出现IP错误,当然如果你能保证您的IP地址为静态获取,就不必去设置
cd /etc/sysconfig/network-scripts/
vim ifcfg-ens33
修改笔者圈住的地方即可(关于静态IP设置笔者也不是很熟悉,详细的大家可以上网查,此步教程不保证一定成功)
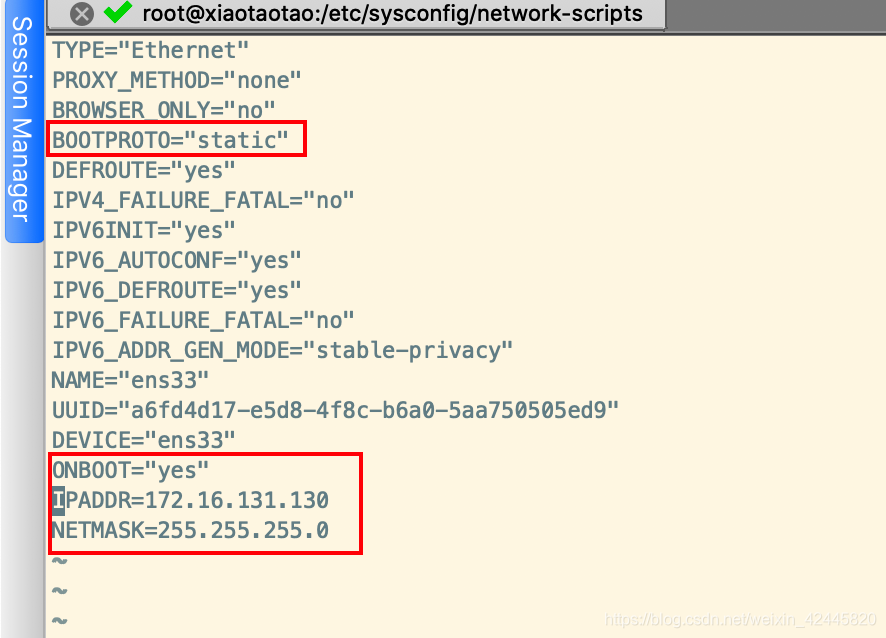
修改完成后重启网络配置即可
systemctl restart network.service
5.配置IP映射
我们在安装操作系统的时候会让我们自己设置,但是我们一般都是傻瓜似的下一步下一步安装,所以我们这里的网络名是默认的IP地址,我们需要需改以便于我们操作和记忆
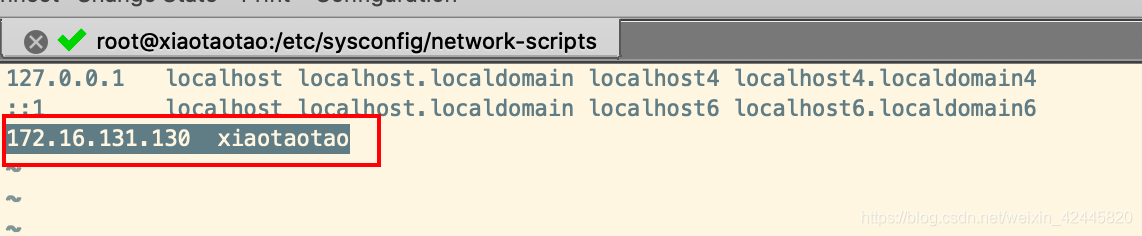
vi /etc/hosts
添加映射
172.16.131.130 xiaotaotao
6.配置ssh免密登录
进入/root/.ssh
cd /root/.ssh
如果没有运行下方命令就有了
使用命令ssh-keygen
ssh-keygen
一路回车之后在/root/.ssh下会生成两个文件,
然后使用命令 ssh-copy-id ‘本机ip’ 输入密码免密码配置完成
ssh-copy-id ‘本机ip’
7.修改hadoop配置文件
首先进入/usr/local/hadoop-2.7.7/etc/hadoop
cd /usr/local/hadoop-2.7.7/etc/hadoop
修改hadoop-env.sh配置文件,添加自己的jdk路径
vim hadoop-env.sh
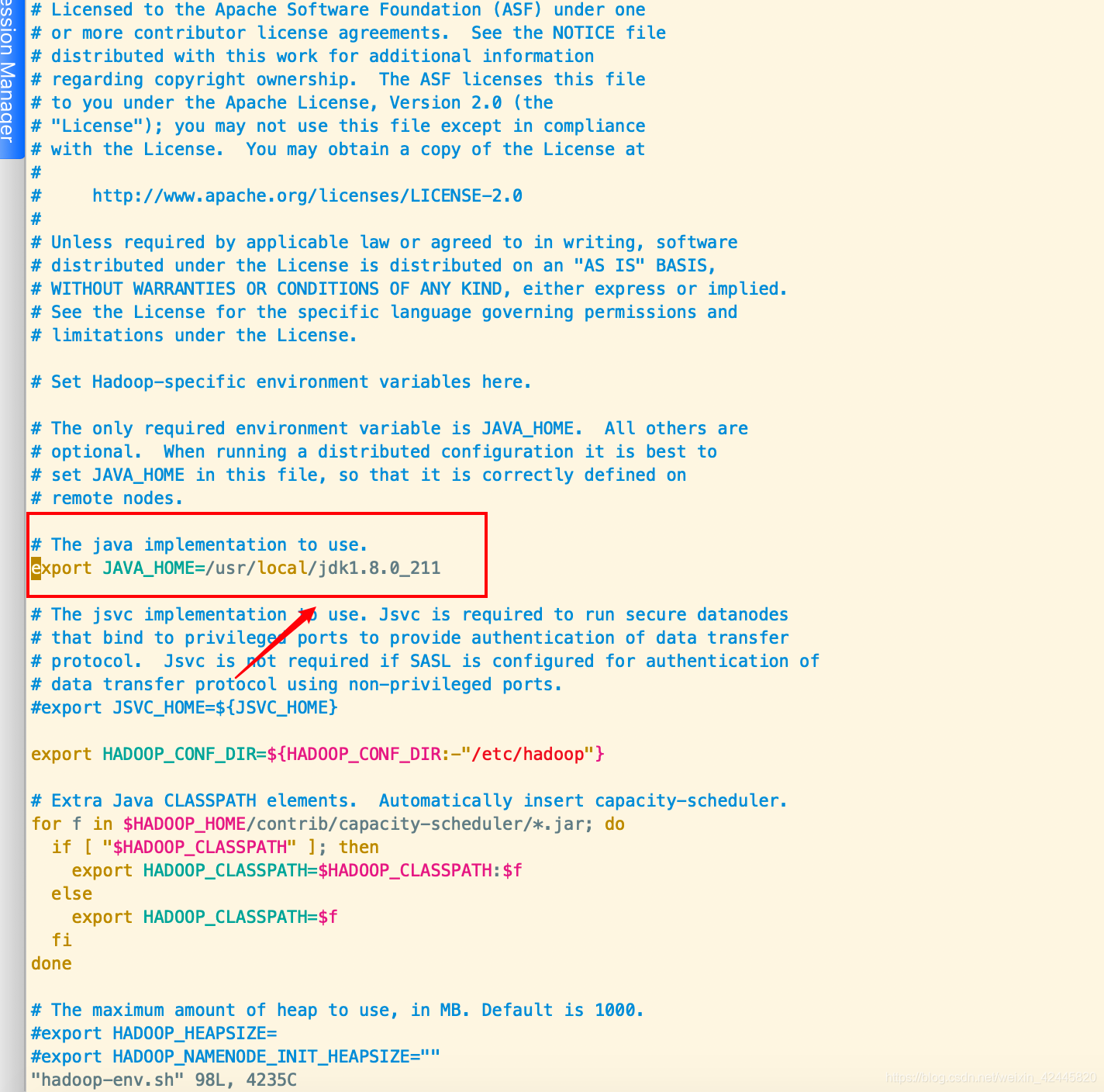
进入core-site.xml中修改或添加以下信息
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://xiaotaotao:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.7/data/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>420</value>
</property>
</configuration>
进入hdfs-site.xml中修改或添加以下信息
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>xiaotaotao:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop-2.7.7/data/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop-2.7.7/data/tmp/dfs/name</value>
</property>
</configuration>
进入mapred-site.xml中修改或添加以下信息
需要注意的是,并没有mapred-site.xml文件的,但是有mapred-site.xml.template,所以我们只需要将这个mapred-site.xml.template更名为mapred-site.xml即可
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>xiaotaotao:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>xiaotaotao:19888</value>
</property>
</configuration>
进入yarn-site.xml中修改或添加以下信息
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>xiaotaotao</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置完成!!!
8.关闭防火墙
systemctl stop firewalld.service 关闭防火墙
systemctl disable firewalld.service 禁止开机启动
firewall-cmd --state 查看防火墙状态
9.大功告成
进入/usr/local/hadoop-2.7.7/bin
cd /usr/local/hadoop-2.7.7/bin
输入命令
./hdfs namenode -format
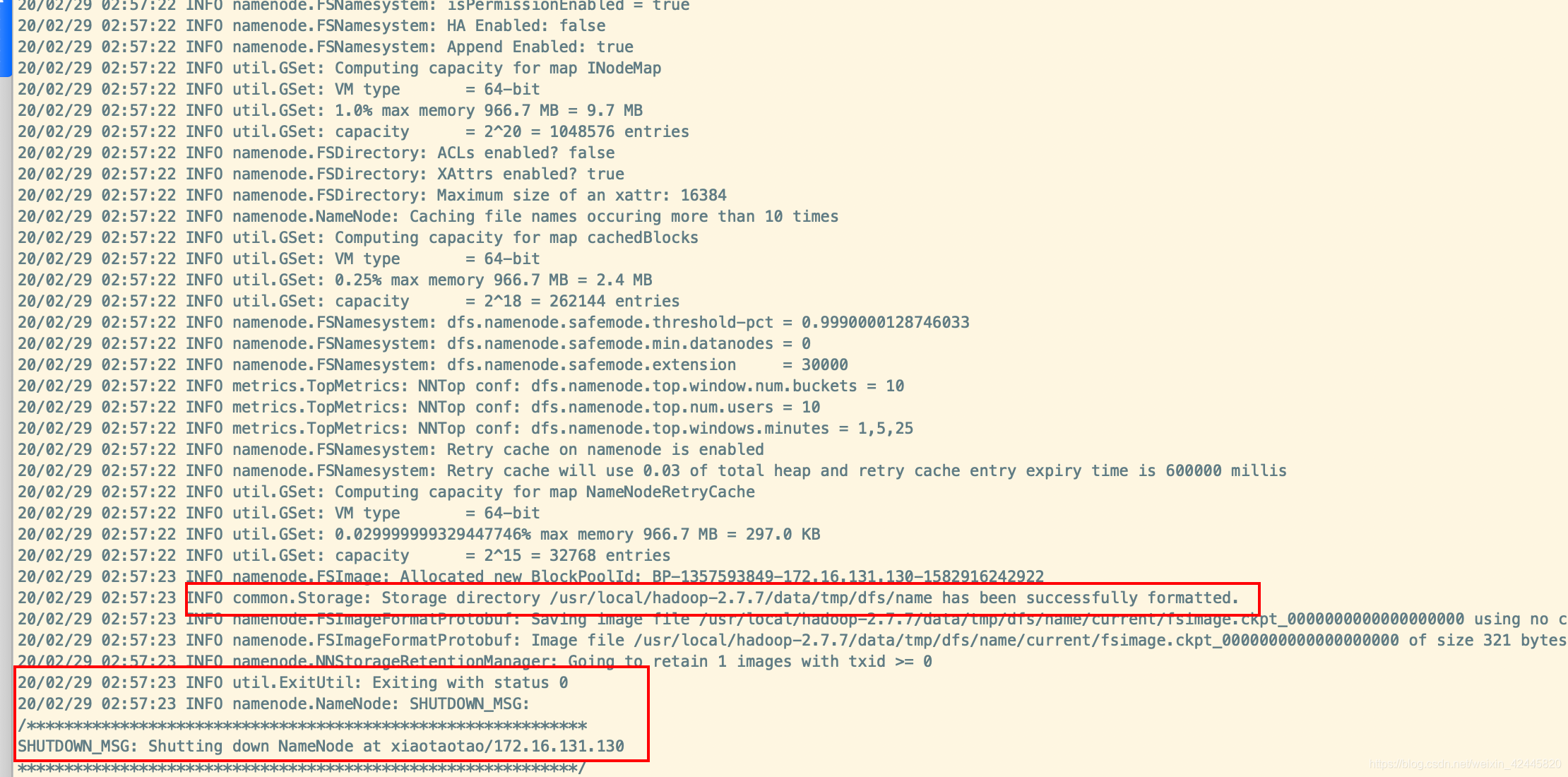
继续输入命令
cd ../sbin/
start-all.sh
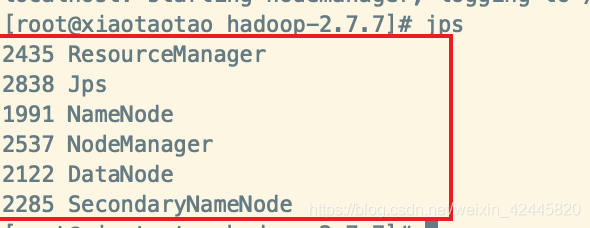
jps
显示如下信息,就表示hadoop安装成功啦!
10.测试
运行一个统计单词的例子:
现在hsfs上创建一个文件夹:
hadoop fs -mkdir /input
查看该文件夹:
hadoop fs -ls /

上传文件到hdfs,这里直接将当前目录的README.txt进行上传:
当前目录是 /usr/local/hadoop-2.7.7,大家也可以上传其他文件
hadoop fs -put README.txt /input/
之后在目录
/usr/local/hadoop-2.7.7/share/hadoop/mapreduce
运行相关例子:
cd /usr/local/hadoop-2.7.7/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output
这个目录不需要提前创建,运行的时候指定一下,会自动创建的。
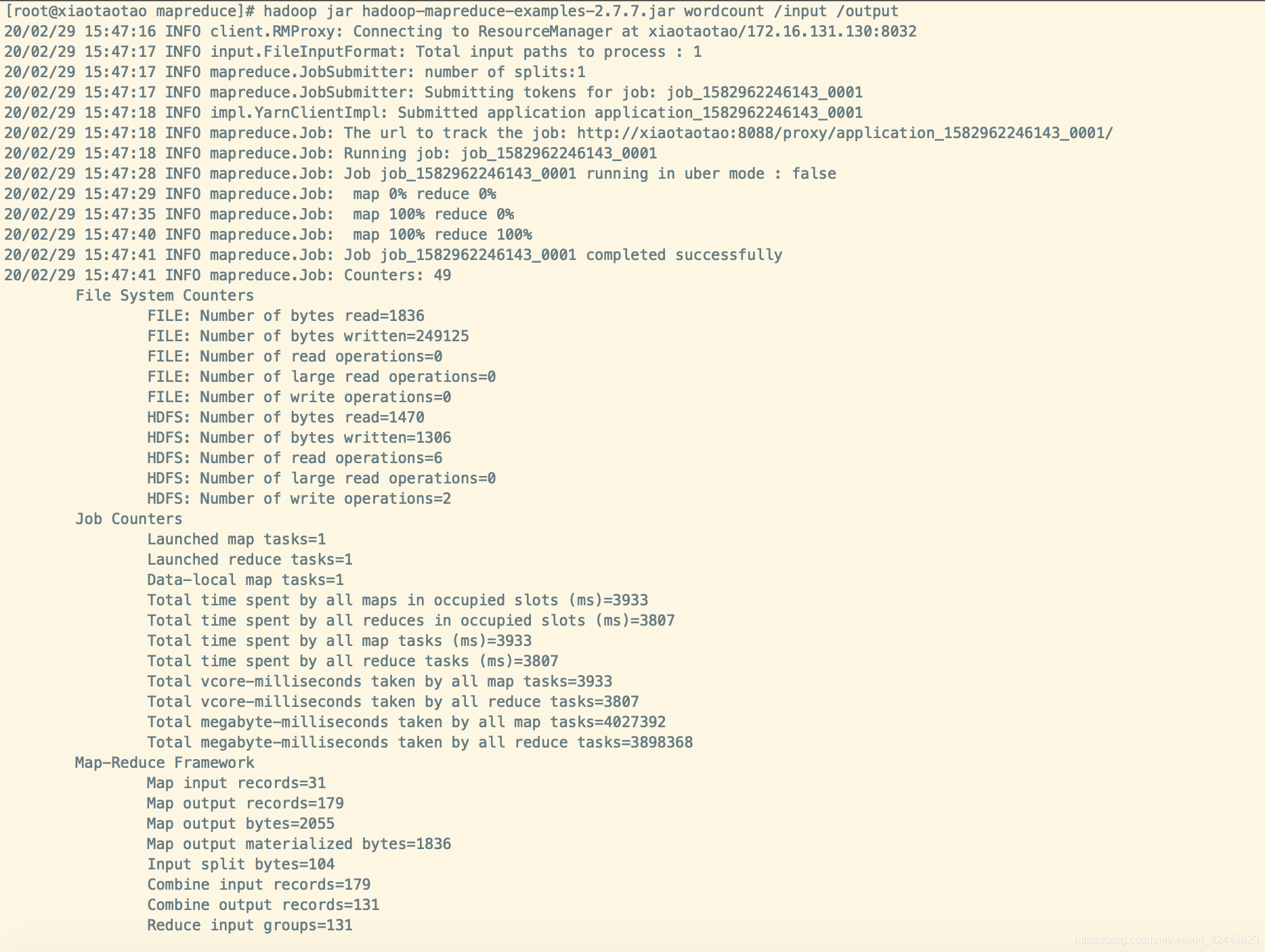
查看相关结果输出:
hadoop fs -ls /output

可以使用: hadoop fs -cat /output1/part-r-00000 查看一下统计结果:
hadoop fs -cat /output/part-r-00000
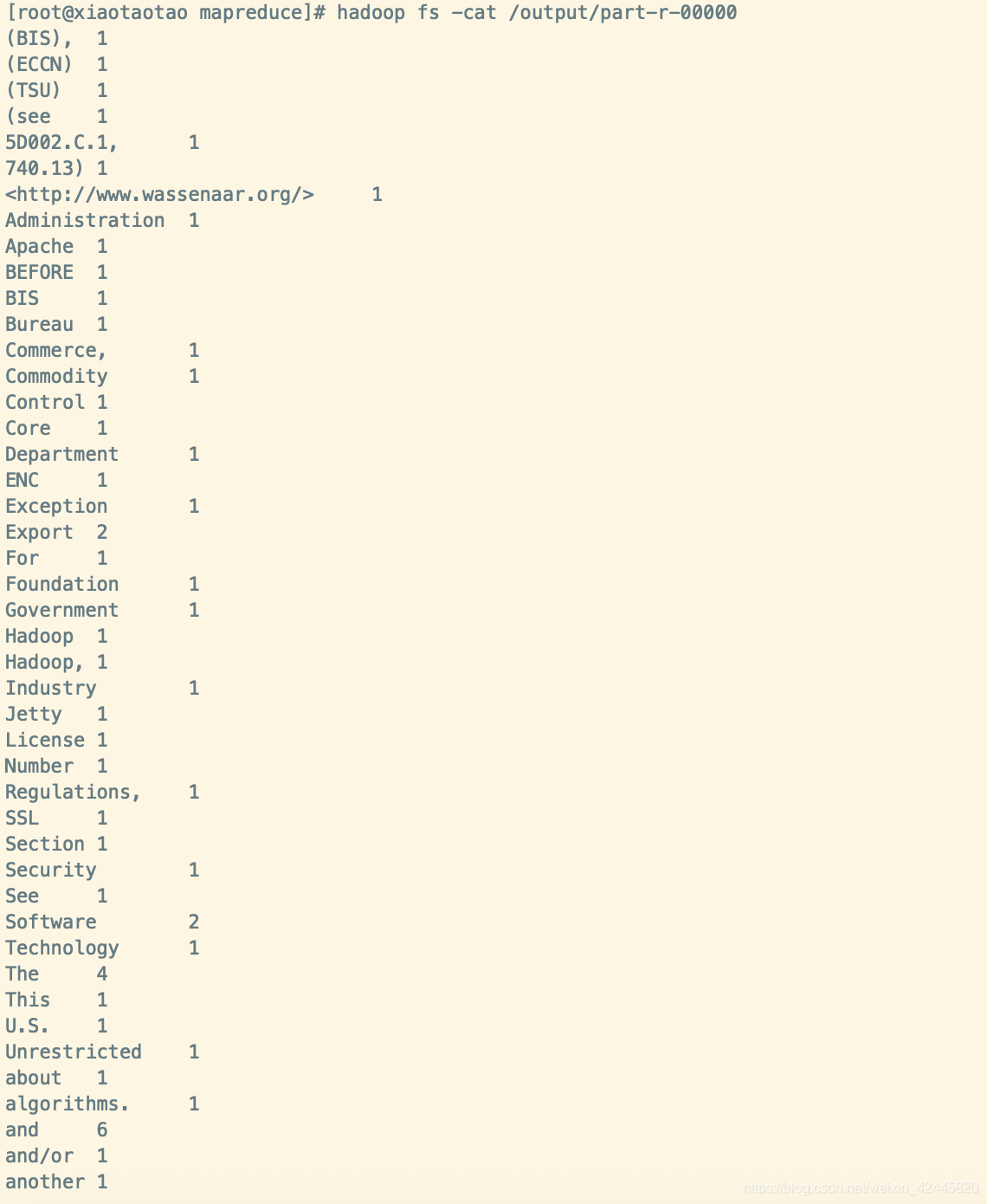
那么到这里,hadoop的安装和测试都完成了,是不是非常刺激呢!!!














 2879
2879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









