









1. ELK
1.1 为什么用ELK
在简单应用中,直接在日志文件中 grep就可以获得自己想要的信息。但在规模较大分布式系统中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。
常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块。那么构建一套集中式日志管理系统,提高定位问题的效率,是非常必要和需要的。
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合和场景的应用。是目前市面上非常主流的一种日志收集分析处理架构。
1.2 ELK架构原理
ELK 最早是 Elasticsearch(简称ES)、Logstash、Kibana 三款开源软件的简称,三款软件后来被同一公司收购,并加入了Xpark、Beats等组件,改名为Elastic Stack,成为现在最流行的开源日志解决方案,虽然有了新名字但大家依然喜欢叫ELK,现在所说的ELK就指的是基于这些开源软件构建的日志系统。
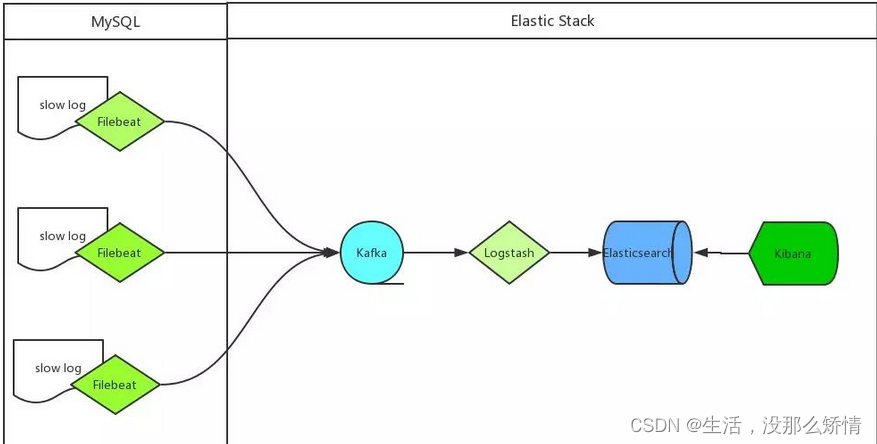
上述架构中,各模块作用如下:
- MySQL 服务器安装 Filebeat 作为 agent 收集 slowLog
- Filebeat 读取 MySQL 慢日志文件做简单过滤传给 Kafka 集群
- Logstash 读取 Kafka 集群数据并按字段拆分后转成 JSON 格式存入 ES 集群
- Kibana 读取ES集群数据展示到web页面上
1.3 MySQL慢查询日志收集展示
Filebeat日志收集
filebeat读取收集slow log,处理后写入kafka。收集日志时需要解决以下问题:
- 日志行合并
- 获取SQL执行时间
- 确定SQL对应的DB名
- 确定SQL对应的主机
Filebeat示例
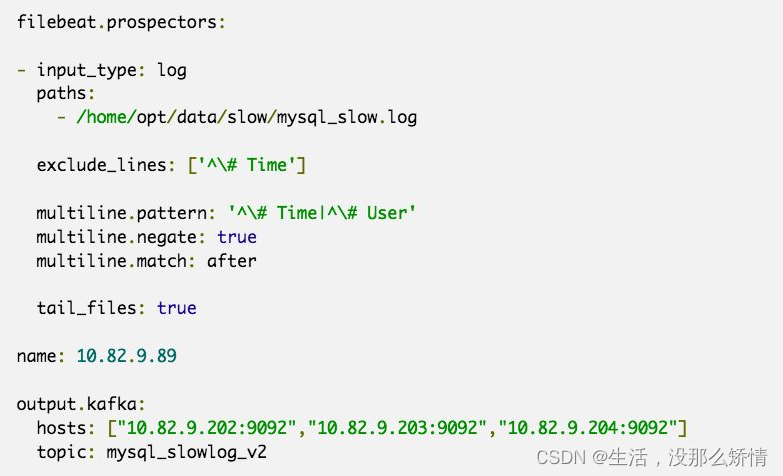
重要参数解释:
input_type:指定输入的类型是log或者是stdin
paths:慢日志路径,支持正则,比如/data/*.log
exclude_lines:过滤掉#Time开头的行
multiline.pattern:匹配多行时指定正则表达式,这里匹配以# Time或者# User开头的行,
Time行要先匹配再过滤
multiline.negate:定义上边pattern匹配到的行是否用于多行合并,也就是定义是不是作为日志
的一部分
multiline.match:定义匹配的行日志作为日志元素的开始还是结束。
tail_files:定义是从文件开头读取日志还是结尾,这里定义为true,从现在开始收集,之前已存
在的不管
name:设置filebeat的名字,如果为空则为服务器的主机名,这里我们定义为服务器IP
output.kafka:配置要接收日志的kafka集群地址可topic名称
Kafka 接收示例:
{“@timestamp”:“2020-05-08T09:36:00.140Z”,“beat”: {“hostname”:“oak”,“name”:“10.63.144.71”,“version”:“5.4.0”},“input_type”:“log”,“m essage”:“# User@Host: select[select] @ [10.63.144.16] Id: 23460596\n# Query_time: 0.155956 Lock_time: 0.000079 Rows_sent: 112 Rows_examined: 366458\nSET timestamp=1533634557;\nSELECT DISTINCT(uid) FROM common_member WHERE hideforum=-1 AND uid != 0;”,“offset”:1753219021,“source”:“/data/slow/mysql_slow.log”,“type”:“log”}
Logstash示例
Logstash消费kafka消息,可以利用kafka consumer group实现集群模式消费保障单点故障不影响日志
处理,grok正则处理后写入elasticsearch。

重要参数解释:
- input:配置 kafka 的集群地址和 topic 名字
- filter:过滤日志文件,主要是对 message 信息(前文 kafka 接收到的日志格式)进行拆分,拆
分成一个一个易读的字段,例如User、Host、Query_time、Lock_time、timestamp等。 - grok:MySQL版本不同,慢查询日志格式有些差异,grok可以根据不同的慢查询格式写不同的正
则表达式去匹配,当有多条正则表达式存在时,logstash会从上到下依次匹配,匹配到一条后边的
则不再匹配。 - date:定义让SQL中的timestamp_mysql字段作为这条日志的时间字段,kibana上看到的实践排
序的数据依赖的就是这个时间 - output:配置ES服务器集群的地址和index,index自动按天分割
Elasticsearch部分略过,默认设置即可达到需求
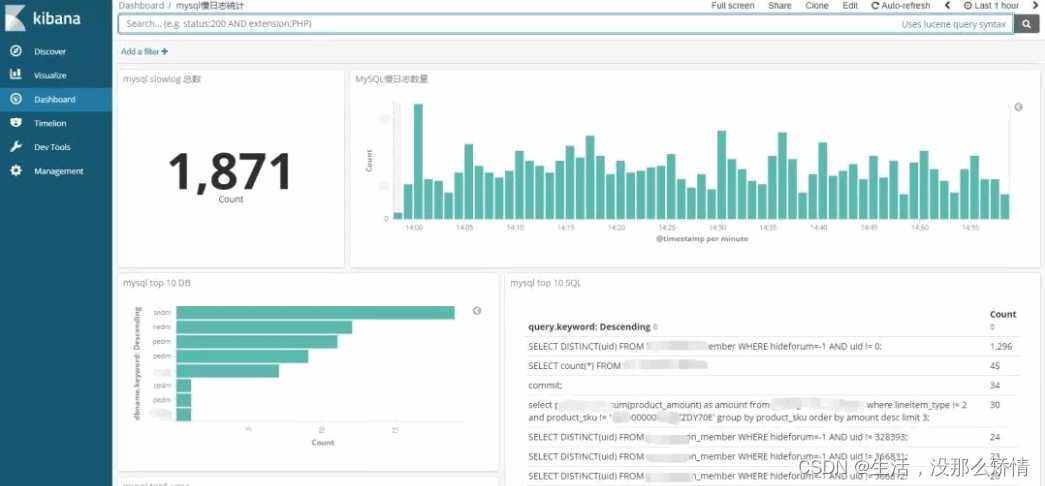
Kibana示例
打开Kibana添加 mysql-slowlog-* 的Index,并选择timestamp,创建Index Pattern。进入Discover页面,就可以很直观的看到各个时间点慢日志的数量变化,可以根据左侧Field实现简单过滤,搜索框也方便搜索慢日志。















 732
732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









