







音频播放
实现播放视频文件中的声音,不显示图像。
使用FFmpeg库实现音频播放的流程图:
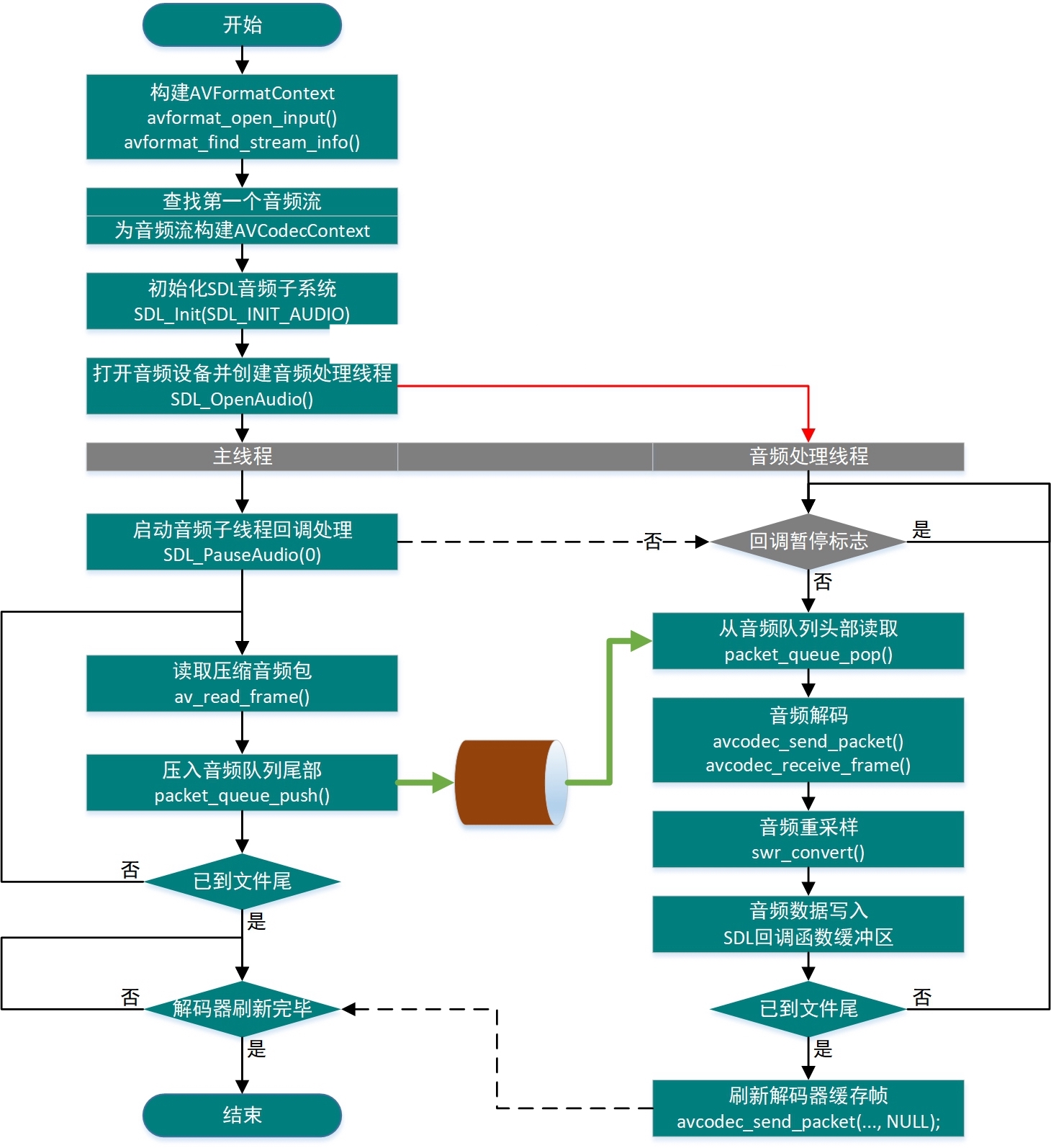
整体流程
- 音频播放的FFmpeg库函数的使用和视频播放的基本一样。
// A1.1 打开视频文件:读取文件头,将文件格式信息存储在"fmt context"中
ret = avformat_open_input(&p_fmt_ctx, argv[1], NULL, NULL);
// A1.2 搜索流信息:读取一段视频文件数据,尝试解码,将取到的流信息填入p_fmt_ctx->streams
// p_fmt_ctx->streams是一个指针数组,数组大小是pFormatCtx->nb_streams
ret = avformat_find_stream_info(p_fmt_ctx, NULL);
// A2. 查找第一个音频流
a_idx = -1;
for (i = 0; i < p_fmt_ctx->nb_streams; i++)
{
if (p_fmt_ctx->streams[i]->codecpar->codec_type == AVMEDIA_TYPE_AUDIO)
{
a_idx = i;
printf("Find a audio stream, index %d\n", a_idx);
break;
}
}
// A3. 为音频流构建解码器AVCodecContext
// A3.1 获取解码器参数AVCodecParameters
p_codec_par = p_fmt_ctx->streams[a_idx]->codecpar;
// A3.2 获取解码器
p_codec = avcodec_find_decoder(p_codec_par->codec_id);
// A3.3 构建解码器AVCodecContext
// A3.3.1 p_codec_ctx初始化:分配结构体,使用p_codec初始化相应成员为默认值
p_codec_ctx = avcodec_alloc_context3(p_codec);
// A3.3.2 p_codec_ctx初始化:p_codec_par ==> p_codec_ctx,初始化相应成员
ret = avcodec_parameters_to_context(p_codec_ctx, p_codec_par);
// A3.3.3 p_codec_ctx初始化:使用p_codec初始化p_codec_ctx,初始化完成
ret = avcodec_open2(p_codec_ctx, p_codec, NULL);
// B1. 初始化SDL子系统:缺省(事件处理、文件IO、线程)、视频、音频、定时器
SDL_Init(SDL_INIT_AUDIO | SDL_INIT_TIMER)
-
打开音频设备并创建音频处理线程
打开音频设备,获取SDL设备支持的音频参数actual_spec(期望的参数是wanted_spec,实际得到actual_spec)
SDL提供两种使音频设备取得音频数据方法:
a. push,SDL以特定的频率调用回调函数,在回调函数中取得音频数据(本文采用);
b. pull,用户程序以特定的频率调用SDL_QueueAudio(),向音频设备提供数据。此种情况
wanted_spec.callback = NULL;音频设备打开后播放静音,不启动回调,调用SDL_PauseAudio(0)后启动回调,开始正常播放音频。
wanted_spec.freq = p_codec_ctx->sample_rate; // 采样率
wanted_spec.format = AUDIO_S16SYS; // S表带符号,16是采样深度,SYS表采用系统字节序
wanted_spec.channels = p_codec_ctx->channels; // 声道数
wanted_spec.silence = 0; // 静音值
wanted_spec.samples = SDL_AUDIO_BUFFER_SIZE; // SDL声音缓冲区尺寸,单位是单声道采样点尺寸x通道数
wanted_spec.callback = sdl_audio_callback; // 回调函数,若为NULL,则应使用SDL_QueueAudio()机制
wanted_spec.userdata = p_codec_ctx; // 提供给回调函数的参数
if (SDL_OpenAudio(&wanted_spec, &actual_spec) < 0) // 打开音频设备并创建音频处理线程
{
printf("SDL_OpenAudio() failed: %s\n", SDL_GetError());
goto exit4;
}
-
根据SDL音频参数构建音频重采样参数
wanted_spec是期望的参数,actual_spec是实际的参数,wanted_spec和auctual_spec都是SDL中的参数。此处audio_param是FFmpeg中的参数,此参数应保证是SDL播放支持的参数,后面重采样要用到此参数。
音频帧解码后得到的frame中的音频格式未必被SDL支持,比如frame可能是planar格式,但SDL2.0并不支持planar格式。此时若将解码后的frame直接送入SDL音频缓冲区,声音将无法正常播放。所以需要先将frame重采样(转换格式)为SDL支持的模式,然后送再写入SDL音频缓冲区。
s_audio_param_tgt.fmt = AV_SAMPLE_FMT_S16;
s_audio_param_tgt.freq = actual_spec.freq;
s_audio_param_tgt.channel_layout = av_get_default_channel_layout(actual_spec.channels);
s_audio_param_tgt.channels = actual_spec.channels;
s_audio_param_tgt.frame_size = av_samples_get_buffer_size(NULL, actual_spec.channels, 1, s_audio_param_tgt.fmt, 1);
s_audio_param_tgt.bytes_per_sec = av_samples_get_buffer_size(NULL, actual_spec.channels, actual_spec.freq, s_audio_param_tgt.fmt, 1);
if (s_audio_param_tgt.bytes_per_sec <= 0 || s_audio_param_tgt.frame_size <= 0)
{
printf("av_samples_get_buffer_size failed\n");
goto exit4;
}
s_audio_param_src = s_audio_param_tgt;
-
暂停/继续音频回调处理。参数1表暂停,0表继续。
打开音频设备后默认未启动回调处理,通过调用SDL_PauseAudio(0)来启动回调处理。这样就可以在打开音频设备后先为回调函数安全初始化数据,一切就绪后再启动音频回调。在暂停期间,会将静音值往音频设备写。
SDL_PauseAudio(0);
-
从视频文件中读取一个packet,此处仅处理音频packet。
对于音频来说,若是帧长固定的格式则一个packet可包含整数个frame;若是帧长可变的格式则一个packet只包含一个frame。
while (av_read_frame(p_fmt_ctx, p_packet) == 0)
{
if (p_packet->stream_index == a_idx)
{ // 读取到音频数据包
packet_queue_push(&s_audio_pkt_queue, p_packet); // 将数据包放入任务队列当中
}
else
{ // 没有读取到音频数据包
av_packet_unref(p_packet); // 释放该数据包
}
}
SDL_Delay(40);
s_input_finished = true;
任务队列
生产者-消费者模型实现,任务队列是共享资源需互斥访问,并且使用条件变量来实现同步。
// 写队列尾部。pkt是一包还未解码的音频数据
int packet_queue_push(packet_queue_t *q, AVPacket *pkt)
{
AVPacketList *pkt_list;
if (av_packet_make_refcounted(pkt) < 0)
{
printf("[pkt] is not refrence counted\n");
return -1;
}
pkt_list = av_malloc(sizeof(AVPacketList));
if (!pkt_list)
{
return -1;
}
pkt_list->pkt = *pkt;
pkt_list->next = NULL;
SDL_LockMutex(q->mutex);
if (!q->last_pkt) // 队列为空
{
q->first_pkt = pkt_list;
}
else
{
q->last_pkt->next = pkt_list;
}
q->last_pkt = pkt_list;
q->nb_packets++;
q->size += pkt_list->pkt.size;
// 发个条件变量的信号:重启等待q->cond条件变量的一个线程
SDL_CondSignal(q->cond);
SDL_UnlockMutex(q->mutex);
return 0;
}
// 读队列头部。
int packet_queue_pop(packet_queue_t *q, AVPacket *pkt, int block)
{
AVPacketList *p_pkt_node;
int ret;
SDL_LockMutex(q->mutex);
while (1)
{
p_pkt_node = q->first_pkt;
if (p_pkt_node) // 队列非空,取一个出来
{
q->first_pkt = p_pkt_node->next;
if (!q->first_pkt)
{
q->last_pkt = NULL;
}
q->nb_packets--;
q->size -= p_pkt_node->pkt.size;
*pkt = p_pkt_node->pkt;
av_free(p_pkt_node);
ret = 1;
break;
}
else if (s_input_finished) // 队列已空,文件已处理完
{
ret = 0;
break;
}
else if (!block) // 队列空且阻塞标志无效,则立即退出
{
ret = 0;
break;
}
else // 队列空且阻塞标志有效,则等待
{
SDL_CondWait(q->cond, q->mutex);
}
}
SDL_UnlockMutex(q->mutex);
return ret;
}
解码器
注意:
- 一个音频 packet 中含有多个完整的音频帧,此函数每次只返回一个 frame,当 avcodec_receive_frame() 指示需要新数据时才调用 avcodec_send_packet() 向编码器发送一个 packet;
- 音频 frame 中的数据格式未必被 SDL 支持,对于不支持的音频 frame 格式,需要进行重采样,转换为 SDL 支持的格式声音才能正常播放;
- 解码器内部会有缓冲机制,会缓存一定量的音频帧,不冲洗(flush)解码器的话,缓存帧是取不出来的。未冲洗(flush)解码器情况下,avcodec_receive_frame() 返回 AVERROR(EAGAIN),表示解码器中改取的帧已取完了(当然缓存帧还是在的),需要用 avcodec_send_packet() 向解码器提供新数据;
- 文件播放完毕时,应冲洗(flush)解码器。冲洗(flush)解码器的方法就是调用 avcodec_send_packet(…, NULL),然后按之前同样的方式多次调用 avcodec_receive_frame() 将缓存帧取尽。缓存帧取完后,avcodec_receive_frame() 返回 AVERROR_EOF。
int audio_decode_frame(AVCodecContext *p_codec_ctx, AVPacket *p_packet, uint8_t *audio_buf, int buf_size)
{
AVFrame *p_frame = av_frame_alloc();
int frm_size = 0;
int res = 0;
int ret = 0;
int nb_samples = 0; // 重采样输出样本数
uint8_t *p_cp_buf = NULL;
int cp_len = 0;
bool need_new = false;
res = 0;
while (1)
{
need_new = false;
// 1 接收解码器输出的数据,每次接收一个frame
ret = avcodec_receive_frame(p_codec_ctx, p_frame);
if (ret != 0)
{
if (ret == AVERROR_EOF)
{
printf("audio avcodec_receive_frame(): the decoder has been fully flushed\n");
res = 0;
goto exit;
}
else if (ret == AVERROR(EAGAIN))
{
// printf("audio avcodec_receive_frame(): output is not available in this state - "
// "user must try to send new input\n");
need_new = true;
}
else if (ret == AVERROR(EINVAL))
{
printf("audio avcodec_receive_frame(): codec not opened, or it is an encoder\n");
res = -1;
goto exit;
}
else
{
printf("audio avcodec_receive_frame(): legitimate decoding errors\n");
res = -1;
goto exit;
}
}
else
{
// s_audio_param_tgt是SDL可接受的音频帧数,是main()中取得的参数
// 在main()函数中又有“s_audio_param_src = s_audio_param_tgt”
// 此处表示:如果frame中的音频参数 == s_audio_param_src == s_audio_param_tgt,那音频重采样的过程就免了(因此时s_audio_swr_ctx是NULL)
// 否则使用frame(源)和s_audio_param_src(目标)中的音频参数来设置s_audio_swr_ctx,并使用frame中的音频参数来赋值s_audio_param_src
if (p_frame->format != s_audio_param_src.fmt ||
p_frame->channel_layout != s_audio_param_src.channel_layout ||
p_frame->sample_rate != s_audio_param_src.freq)
{
swr_free(&s_audio_swr_ctx);
// 使用frame(源)和is->audio_tgt(目标)中的音频参数来设置is->swr_ctx
s_audio_swr_ctx = swr_alloc_set_opts(NULL,
s_audio_param_tgt.channel_layout,
s_audio_param_tgt.fmt,
s_audio_param_tgt.freq,
p_frame->channel_layout,
p_frame->format,
p_frame->sample_rate,
0,
NULL);
if (s_audio_swr_ctx == NULL || swr_init(s_audio_swr_ctx) < 0)
{
printf("Cannot create sample rate converter for conversion of %d Hz %s %d channels to %d Hz %s %d channels!\n",
p_frame->sample_rate, av_get_sample_fmt_name(p_frame->format), p_frame->channels,
s_audio_param_tgt.freq, av_get_sample_fmt_name(s_audio_param_tgt.fmt), s_audio_param_tgt.channels);
swr_free(&s_audio_swr_ctx);
return -1;
}
// 使用frame中的参数更新s_audio_param_src,第一次更新后后面基本不用执行此if分支了,因为一个音频流中各frame通用参数一样
s_audio_param_src.channel_layout = p_frame->channel_layout;
s_audio_param_src.channels = p_frame->channels;
s_audio_param_src.freq = p_frame->sample_rate;
s_audio_param_src.fmt = p_frame->format;
}
if (s_audio_swr_ctx != NULL) // 重采样
{
// 重采样输入参数1:输入音频样本数是p_frame->nb_samples
// 重采样输入参数2:输入音频缓冲区
const uint8_t **in = (const uint8_t **)p_frame->extended_data;
// 重采样输出参数1:输出音频缓冲区尺寸
// 重采样输出参数2:输出音频缓冲区
uint8_t **out = &s_resample_buf;
// 重采样输出参数:输出音频样本数(多加了256个样本)
int out_count = (int64_t)p_frame->nb_samples * s_audio_param_tgt.freq / p_frame->sample_rate + 256;
// 重采样输出参数:输出音频缓冲区尺寸(以字节为单位)
int out_size = av_samples_get_buffer_size(NULL, s_audio_param_tgt.channels, out_count, s_audio_param_tgt.fmt, 0);
if (out_size < 0)
{
printf("av_samples_get_buffer_size() failed\n");
return -1;
}
if (s_resample_buf == NULL)
{
av_fast_malloc(&s_resample_buf, &s_resample_buf_len, out_size);
}
if (s_resample_buf == NULL)
{
return AVERROR(ENOMEM);
}
// 音频重采样:返回值是重采样后得到的音频数据中单个声道的样本数
nb_samples = swr_convert(s_audio_swr_ctx, out, out_count, in, p_frame->nb_samples);
if (nb_samples < 0)
{
printf("swr_convert() failed\n");
return -1;
}
if (nb_samples == out_count)
{
printf("audio buffer is probably too small\n");
if (swr_init(s_audio_swr_ctx) < 0)
swr_free(&s_audio_swr_ctx);
}
// 重采样返回的一帧音频数据大小(以字节为单位)
p_cp_buf = s_resample_buf;
cp_len = nb_samples * s_audio_param_tgt.channels * av_get_bytes_per_sample(s_audio_param_tgt.fmt);
}
else // 不重采样
{
// 根据相应音频参数,获得所需缓冲区大小
frm_size = av_samples_get_buffer_size(
NULL,
p_codec_ctx->channels,
p_frame->nb_samples,
p_codec_ctx->sample_fmt,
1);
printf("frame size %d, buffer size %d\n", frm_size, buf_size);
assert(frm_size <= buf_size);
p_cp_buf = p_frame->data[0];
cp_len = frm_size;
}
// 将音频帧拷贝到函数输出参数audio_buf
memcpy(audio_buf, p_cp_buf, cp_len);
res = cp_len;
goto exit;
}
// 2 向解码器喂数据,每次喂一个packet
if (need_new)
{
ret = avcodec_send_packet(p_codec_ctx, p_packet);
if (ret != 0)
{
printf("avcodec_send_packet() failed %d\n", ret);
av_packet_unref(p_packet);
res = -1;
goto exit;
}
}
}
exit:
av_frame_unref(p_frame);
return res;
}
回调函数
// 音频处理回调函数。读队列获取音频包,解码,播放
// 此函数被SDL按需调用,此函数不在用户主线程中,因此数据需要保护
// \param[in] userdata用户在注册回调函数时指定的参数
// \param[out] stream 音频数据缓冲区地址,将解码后的音频数据填入此缓冲区
// \param[out] len 音频数据缓冲区大小,单位字节
// 回调函数返回后,stream指向的音频缓冲区将变为无效
// 双声道采样点的顺序为LRLRLR
void sdl_audio_callback(void *userdata, uint8_t *stream, int len)
{
AVCodecContext *p_codec_ctx = (AVCodecContext *)userdata;
int copy_len; //
int get_size; // 获取到解码后的音频数据大小
static uint8_t s_audio_buf[(MAX_AUDIO_FRAME_SIZE * 3) / 2]; // 1.5倍声音帧的大小
static uint32_t s_audio_len = 0; // 新取得的音频数据大小
static uint32_t s_tx_idx = 0; // 已发送给设备的数据量
AVPacket *p_packet;
int frm_size = 0;
int ret_size = 0;
int ret;
while (len > 0) // 确保stream缓冲区填满,填满后此函数返回
{
if (s_decode_finished)
{
return;
}
if (s_tx_idx >= s_audio_len)
{ // audio_buf缓冲区中数据已全部取出,则从队列中获取更多数据
p_packet = (AVPacket *)av_malloc(sizeof(AVPacket));
// 1. 从队列中读出一包音频数据
if (packet_queue_pop(&s_audio_pkt_queue, p_packet, 1) <= 0)
{
if (s_input_finished)
{
av_packet_unref(p_packet);
p_packet = NULL; // flush decoder
printf("Flushing decoder...\n");
}
else
{
av_packet_unref(p_packet);
return;
}
}
// 2. 解码音频包
get_size = audio_decode_frame(p_codec_ctx, p_packet, s_audio_buf, sizeof(s_audio_buf));
if (get_size < 0)
{
// 出错输出一段静音
s_audio_len = 1024; // arbitrary?
memset(s_audio_buf, 0, s_audio_len);
av_packet_unref(p_packet);
}
else if (get_size == 0) // 解码缓冲区被冲洗,整个解码过程完毕
{
s_decode_finished = true;
}
else
{
s_audio_len = get_size;
av_packet_unref(p_packet);
}
s_tx_idx = 0;
if (p_packet->data != NULL)
{
// av_packet_unref(p_packet);
}
}
copy_len = s_audio_len - s_tx_idx;
if (copy_len > len)
{
copy_len = len;
}
// 将解码后的音频帧(s_audio_buf+)写入音频设备缓冲区(stream),播放
memcpy(stream, (uint8_t *)s_audio_buf + s_tx_idx, copy_len);
len -= copy_len;
stream += copy_len;
s_tx_idx += copy_len;
}
}
参考
- FFmpeg简易播放器的实现2-视频播放 - 叶余 - 博客园 (cnblogs.com)
- 最简单的基于FFMPEG+SDL的视频播放器 ver2 (采用SDL2.0)_雷霄骅的博客-CSDN博客_ffmpeg sdl
- [总结]视音频编解码技术零基础学习方法_雷霄骅的博客-CSDN博客_音视频编解码入门















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











