






需求
最近公司需要搭建Hadoop集群 ,又听说移动云正在举办年中超惠活动,所以我们决定使用移动云来搭建我们的Hadoop集群
移动云介绍:
移动云弹性MapReduce(简称EMR)是构建于云端的大数据PaaS服务,包含Hadoop(HDFS/YARN/MapReduce)、Spark、Hive等开源技术。支持用户快速创建集群,进行海量数据存储与计算。
产品功能
集群管理
- 集群生命周期:支持集群订购、退订、删除等。
- 集群实例管理:支持集群资源管理、集群服务管理、集群用户管理等。
- 集群运营管理:支持集群配额管理、容量管理、权限管理等。
- 集群运维管理:支持集群监控告警、故障管理、参数配置管理等。
集群服务
- Hadoop(HDFS/YARN/MapReduce):作为大数据存储与计算平台。
- Spark:基于内存的新一代分布式计算引擎,主要用来构建大型的、低延迟的数据分析应用程序。
- Hive:基于Hadoop的离线分析型数据仓库,专门查询和分析大型数据集、表和存储管理服务。
产品优势
操作简单易用
用户无需关注硬件的购买与软件的配置,即可快速启动使用Hadoop集群。通过Web集群管理系统,可轻松实现对集群资源和集群用户的管理,以及对集群服务的管理、监控与运维,让工程师更专注于商业价值应用的开发与优化。
环境安全可靠
集群环境深度优化,集群数据安全可靠。采用LDAP、Kerberos、Ranger一套完整的技术体系,实现完备的安全管控与审计。
成本经济可控
用户可按需申请集群资源,及时且资源最优化满足各类上层应用的计算与存储需求。
生态完善开放
适配中国移动云计算、大数据、人工智能相关产品,紧随开源大数据生态,兼容开源大数据标准。
应用场景
离线数据分析
应用于通信、金融、能源、医疗、物联网、气象局等拥有海量数据的行业领域,助力企业级日志存储与分析、用户细分与建模、行为分析与预测等场景。
特点
- 计算分析引擎丰富:支持MapReduce、Spark、Hive等计算引擎。
- 应用形式多元化:借助EMR的数据分析能力,实现上层应用的百花齐放。
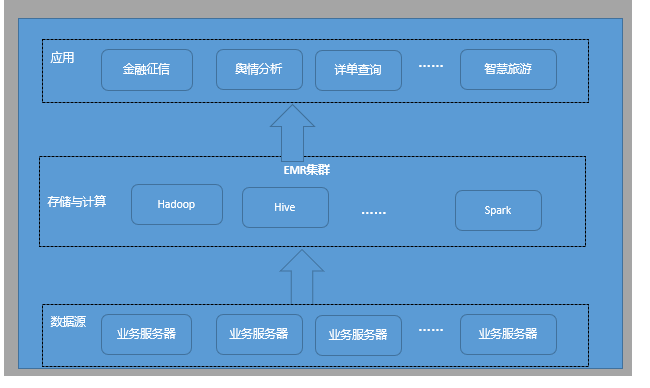
离线存储与计算
支持MapReduce、Spark等计算引擎,同时为移动云相关服务提供计算引擎功能。如DIG数据集成与治理需要使用EMR的计算引擎。
特点
- 丰富的存储类型:支持对象存储、云数据库存储、HDFS存储等。
- 丰富的计算引擎:支持MapReduce、Spark、Hive等计算引擎。
因为以上种种特点和优势, 我们公司决定立即开始搭建!
购买服务器
我们专门在移动云上购买了三台服务器,都是1C2G Linux CentOS7.5 X64的系统,分别命名为node1(172.24.38.209),node2(172.24.38.210),node3(172.24.38.211),确保三台服务器相互都能联通,然后我们对于这三台服务器组件集群的规划如下:

Hadoop集群节点规划
第一步,我们需要在每个节点上安装JDK运行环境,假设我们下载的JDK放在/root/soft目录下。
#进入JDK所在目录
cd /root/soft
#解压
tar zxvf jdk-8u65-linux-x64.tar.gz
#配置环境变量
vim /etc/profile
export JAVA_HOME=/root/soft/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
#验证
[root@iZuf6gmsvearrd5uc3emkyZ soft]# java -version
java version "1.8.0_241"
Java(TM) SE Runtime Environment (build 1.8.0_241-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, mixed mode)
第二步,我们需要在每个节点上确保时间同步和关闭防火墙。
#时间同步
ntpdate ntp5.aliyun.com
# 防火墙关闭
#查看防火墙状态
firewall-cmd --state
#停止firewalld服务
systemctl stop firewalld.service
#开机禁用firewalld服务
systemctl disable firewalld.service
第三步,我们需要开通node1到node1、node2、node3的ssh免密连接服务。
# 生成公钥密钥,全部回车下一步即可
ssh-keygen -t rsa
ssh-keygen -t dsa
#开通node1到node1的免密ssh
[root@iZuf6gmsvearrd5uc3emkyZ soft]# ssh-copy-id 172.24.38.209
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@172.24.38.209's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh '172.24.38.209'"
and check to make sure that only the key(s) you wanted were added.
#开通node1到node2的免密ssh
[root@iZuf6gmsvearrd5uc3emkyZ soft]# ssh-copy-id 172.24.38.210
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host '172.24.38.210 (172.24.38.210)' can't be established.
ECDSA key fingerprint is SHA256:ah4dSYvdlmiJv/Q8aJ5Vdm/PtYGCLE61/hl8waEeeSg.
ECDSA key fingerprint is MD5:4b:53:93:61:2b:a7:6d:79:67:c4:54:ca:24:11:86:26.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@172.24.38.210's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh '172.24.38.210'"
and check to make sure that only the key(s) you wanted were added.
#开通node1到node3的免密ssh
[root@iZuf6gmsvearrd5uc3emkyZ soft]# ssh-copy-id 172.24.38.211
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host '172.24.38.211 (172.24.38.211)' can't be established.
ECDSA key fingerprint is SHA256:F1oP0hFY+V3VHUL5rOSLEeTCv3m+y92u5RCW6RpBNDI.
ECDSA key fingerprint is MD5:ed:c7:a5:0b:f2:25:71:7b:fc:a8:e1:ce:fd:eb:19:7b.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@172.24.38.211's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh '172.24.38.211'"
and check to make sure that only the key(s) you wanted were added.
#node1免密ssh到node1实验
[root@iZuf6gmsvearrd5uc3emkyZ soft]# ssh 172.24.38.209
Last login: Wed Nov 2 15:31:22 2024 from 172.24.38.209
Welcome to Alibaba Cloud Elastic Compute Service !
[root@iZuf6gmsvearrd5uc3emkyZ ~]# exit
logout
Connection to 172.24.38.209 closed.
#node1免密ssh到node2实验
[root@iZuf6gmsvearrd5uc3emkyZ soft]# ssh 172.24.38.210
Last login: Wed Nov 2 15:13:46 2024 from 122.193.199.200
Welcome to Alibaba Cloud Elastic Compute Service !
[root@iZuf6gmsvearrd5uc3emkzZ ~]# exit
logout
Connection to 172.24.38.210 closed.
#node1免密ssh到node3实验
[root@iZuf6gmsvearrd5uc3emkyZ soft]# ssh 172.24.38.211
Last login: Wed Nov 2 14:50:32 2024 from 122.193.199.232
Welcome to Alibaba Cloud Elastic Compute Service !
[root@iZuf6gmsvearrd5uc3eml0Z ~]# exit
logout
Connection to 172.24.38.211 closed.
第四步,我们需要在每个节点上安装Hadoop,假设我们下载的Hadoop放在/root/soft目录下,可以先在一台服务器上完成修改后,再将Hadoop文件夹scp到其它两台服务器。
#进入目录
cd /root/soft
#解压
tar zxvf hadoop-3.3.4.tar.gz
#修改hadoop配置文件hadoop-env.sh
cd /root/soft/hadoop-3.3.4/etc/hadoop
vim hadoop-env.sh
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#改成你自己的JAVA_HOME地址
export JAVA_HOME=/root/soft/jdk1.8.0_241
#设置HADOOP环境变量
vim /etc/profile
export HADOOP_HOME=/root/soft/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
然后再修改core-site.xml配置文件:
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.24.38.209:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/data/hadoop</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
然后再修改hdfs-site.xml配置文件:
<!-- 设置SecondNameNode进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>172.24.38.210:9868</value>
</property>
然后再修改mapred-site.xml配置文件:
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>172.24.38.209:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>172.24.38.209:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
然后再修改yarn-site.xml配置文件:
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>172.24.38.209</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://172.24.38.209:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
然后再修改workers配置文件:
172.24.38.209
172.24.38.210
172.24.38.211
然后将修改好的hadoop-3.3.4文件夹远程拷贝到其它两台服务器:
scp -r hadoop-3.3.4 root@172.24.38.210:/root/soft
scp -r hadoop-3.3.4 root@172.24.38.211:/root/soft
最后,我们需要在每一台服务器上配置Hadoop的环境变量:
vim /etc/profile
export HADOOP_HOME=/root/soft/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
第五步,我们首次启动时,需要在node1上进行namenode的格式化:
hdfs namenode -format
#格式化成功的部分日志
2024-11-02 16:40:49,064 INFO common.Storage: Storage directory /root/data/hadoop/dfs/name has been successfully formatted.
第六步,启动我们的hadoop hdfs集群:
#启动HDFS集群,停止命令为stop-dfs.sh
[root@iZuf6gmsvearrd5uc3emkyZ hadoop]# start-dfs.sh
Starting namenodes on [iZuf6gmsvearrd5uc3emkyZ]
Last login: Wed Nov 2 16:51:29 CST 2024 on pts/1
Starting datanodes
Last login: Wed Nov 2 16:53:30 CST 2024 on pts/1
172.24.38.210: WARNING: /root/soft/hadoop-3.3.4/logs does not exist. Creating.
172.24.38.211: WARNING: /root/soft/hadoop-3.3.4/logs does not exist. Creating.
Starting secondary namenodes [172.24.38.210]
Last login: Wed Nov 2 16:53:33 CST 2024 on pts/1
#在node1上查看java进程,检验计划的hdfs角色是否都启动了
[root@iZuf6gmsvearrd5uc3emkyZ hadoop]# jps
8055 DataNode
8333 Jps
7919 NameNode
#在node2上查看java进程,检验计划的hdfs角色是否都启动了
[root@iZuf6gmsvearrd5uc3emkzZ hadoop]# jps
1793 Jps
1738 SecondaryNameNode
1643 DataNode
#在node3上查看java进程,检验计划的hdfs角色是否都启动了
[root@iZuf6gmsvearrd5uc3eml0Z hadoop]# jps
1605 DataNode
1671 Jps
结果显示,和我们计划的集群角色一致,hdfs集群启动成功。
第七步,启动我们的hadoop yarn集群:
#启动YARN集群,停止命令为stop-yarn.sh
[root@iZuf6gmsvearrd5uc3emkyZ hadoop]# start-yarn.sh
Starting resourcemanager
Last login: Wed Nov 2 16:53:43 CST 2024 on pts/1
Starting nodemanagers
Last login: Wed Nov 2 17:02:08 CST 2024 on pts/1
#在node1上查看java进程,检验计划的hdfs和yarn角色是否都启动了
[root@iZuf6gmsvearrd5uc3emkyZ hadoop]# jps
8947 Jps
8487 ResourceManager
8055 DataNode
8617 NodeManager
7919 NameNode
#在node2上查看java进程,检验计划的hdfs和yarn角色是否都启动了
[root@iZuf6gmsvearrd5uc3emkzZ hadoop]# jps
1875 NodeManager
1973 Jps
1738 SecondaryNameNode
1643 DataNode
#在node3上查看java进程,检验计划的hdfs和yarn角色是否都启动了
[root@iZuf6gmsvearrd5uc3eml0Z hadoop]# jps
1605 DataNode
1835 Jps
1741 NodeManager
结果显示,和我们计划的集群角色一致,hdfs集群和yarn集群都启动成功。如果嫌弃两个集群需要一个个启动麻烦,也可以使用一键启动命令:
#一键启动HDFS和YARN集群
start-all.sh
#一键停止HDFS和YARN集群
stop-all.sh
hdfs和yarn都为用户提供了WebUI界面,因为默认情况下,我们在移动云创建的服务器是不对外开放不需要的接口的,所以想要能在公网访问WebUI界面,需要在移动云的控制台安全组里面开放服务器的hdfs和yarn端口:
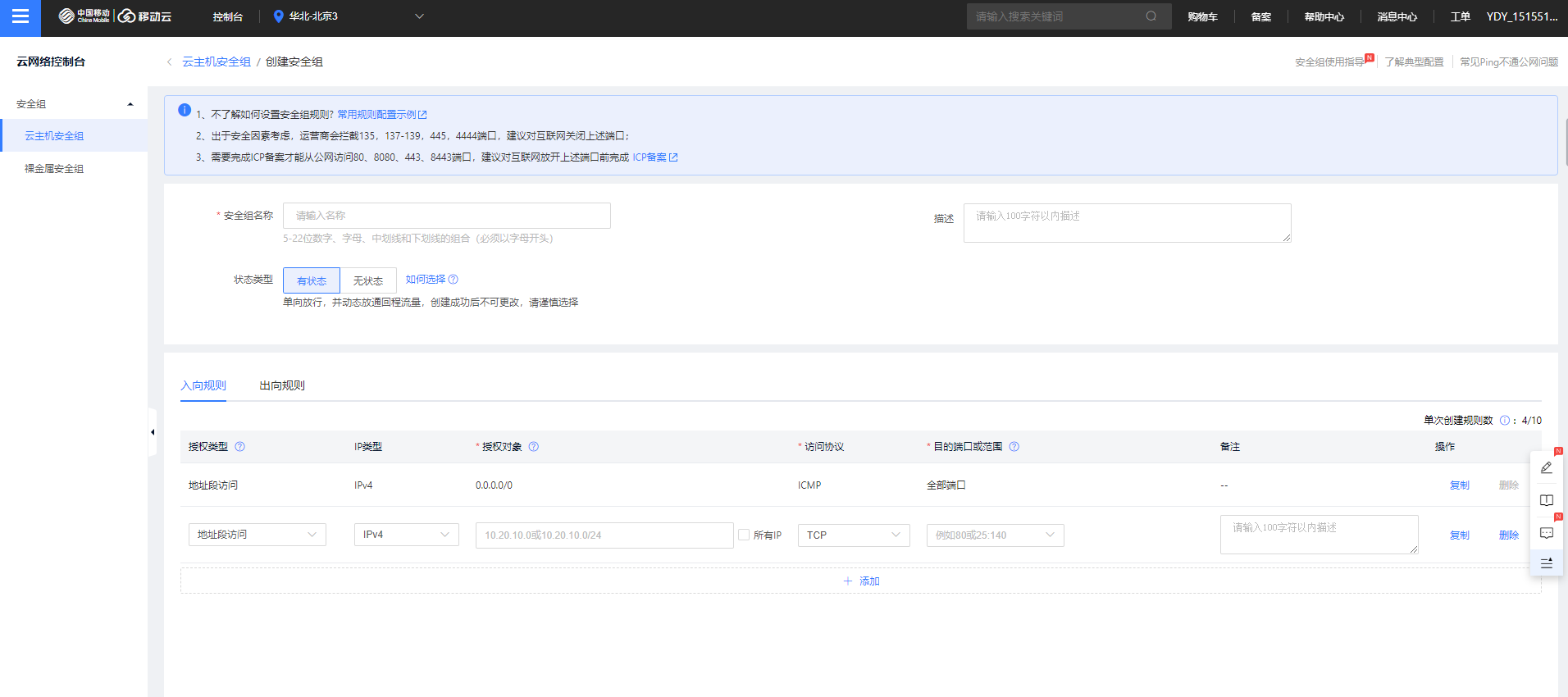
移动云服务器开放hdfs和yarn的web UI端口
然后访问node1(NameNode和ResourceManger所在的服务器)的公网域名加端口就能使用HDFS和YARN了。
最后,我们使用官方自带的MapReduce案例来计算一下圆周率的值:
# 进入案例所在目录
[root@iZuf6gmsvearrd5uc3emkyZ ~]# cd /root/soft/hadoop-3.3.4/share/hadoop/mapreduce/
[root@iZuf6gmsvearrd5uc3emkyZ mapreduce]# ls
hadoop-mapreduce-client-app-3.3.4.jar hadoop-mapreduce-client-hs-plugins-3.3.4.jar hadoop-mapreduce-client-shuffle-3.3.4.jar lib-examples
hadoop-mapreduce-client-common-3.3.4.jar hadoop-mapreduce-client-jobclient-3.3.4.jar hadoop-mapreduce-client-uploader-3.3.4.jar sources
hadoop-mapreduce-client-core-3.3.4.jar hadoop-mapreduce-client-jobclient-3.3.4-tests.jar hadoop-mapreduce-examples-3.3.4.jar
hadoop-mapreduce-client-hs-3.3.4.jar hadoop-mapreduce-client-nativetask-3.3.4.jar jdiff
# 执行计算任务
[root@iZuf6gmsvearrd5uc3emkyZ mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.4.jar pi 2 4
Number of Maps = 2
Samples per Map = 4
Wrote input for Map #0
Wrote input for Map #1
Starting Job
# 由Yarn的ResourceManager来分配资源
2024-11-02 17:31:41,735 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /172.24.38.209:8032
2024-11-02 17:31:42,738 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1667379747044_0002
2024-11-02 17:31:43,046 INFO input.FileInputFormat: Total input files to process : 2
2024-11-02 17:31:43,953 INFO mapreduce.JobSubmitter: number of splits:2
2024-11-02 17:31:44,735 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1667379747044_0002
2024-11-02 17:31:44,736 INFO mapreduce.JobSubmitter: Executing with tokens: []
2024-11-02 17:31:45,110 INFO conf.Configuration: resource-types.xml not found
2024-11-02 17:31:45,110 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2024-11-02 17:31:45,264 INFO impl.YarnClientImpl: Submitted application application_1667379747044_0002
2024-11-02 17:31:45,349 INFO mapreduce.Job: The url to track the job: http://iZuf6gmsvearrd5uc3emkyZ:8088/proxy/application_1667379747044_0002/
2024-11-02 17:31:45,350 INFO mapreduce.Job: Running job: job_1667379747044_0002
2024-11-02 17:31:59,929 INFO mapreduce.Job: Job job_1667379747044_0002 running in uber mode : false
2024-11-02 17:31:59,931 INFO mapreduce.Job: map 0% reduce 0%
2024-11-02 17:32:14,551 INFO mapreduce.Job: map 50% reduce 0%
2024-11-02 17:32:15,568 INFO mapreduce.Job: map 100% reduce 0%
2024-11-02 17:32:23,754 INFO mapreduce.Job: map 100% reduce 100%
2024-11-02 17:32:25,819 INFO mapreduce.Job: Job job_1667379747044_0002 completed successfully
2024-11-02 17:32:26,168 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=830664
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=536
HDFS: Number of bytes written=215
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=24774
Total time spent by all reduces in occupied slots (ms)=6828
Total time spent by all map tasks (ms)=24774
Total time spent by all reduce tasks (ms)=6828
Total vcore-milliseconds taken by all map tasks=24774
Total vcore-milliseconds taken by all reduce tasks=6828
Total megabyte-milliseconds taken by all map tasks=25368576
Total megabyte-milliseconds taken by all reduce tasks=6991872
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input split bytes=300
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=56
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=781
CPU time spent (ms)=2500
Physical memory (bytes) snapshot=537804800
Virtual memory (bytes) snapshot=8220102656
Total committed heap usage (bytes)=295051264
Peak Map Physical memory (bytes)=213385216
Peak Map Virtual memory (bytes)=2737229824
Peak Reduce Physical memory (bytes)=113819648
Peak Reduce Virtual memory (bytes)=2745643008
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
Job Finished in 44.671 seconds
# 计算结果
Estimated value of Pi is 3.50000000000000000000
如果任务执行时间较久,也可以手动停止:
# 查看运行中任务列表
[root@iZuf6gmsvearrd5uc3emkyZ ~]# yarn application -list -appStates RUNNING
2024-11-02 17:29:29,506 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /172.24.38.209:8032
Total number of applications (application-types: [], states: [RUNNING] and tags: []):1
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1667379747044_0001 QuasiMonteCarlo MAPREDUCE root default RUNNING UNDEFINED 27.5%http://iZuf6gmsvearrd5uc3emkyZ:36895
# 停止指定的任务
[root@iZuf6gmsvearrd5uc3emkyZ ~]# yarn application -kill application_1667379747044_0001
2024-11-02 17:29:58,805 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /172.24.38.209:8032
Killing application application_1667379747044_0001
2024-11-02 17:30:00,183 INFO impl.YarnClientImpl: Killed application application_1667379747044_0001
至此,一个完整的Hadoop集群搭建教程已经完成。
总结
在企业的实际应用中,目前主流的都是直接使用移动云云厂商提供的Hadoop集群,在创建MapReduce集群的时候就可以选择对应的集群类型,无需用户自己搭建,非常便捷。
















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











