






前言
分析本Benchmark的思路为:分析热点区域(热点函数,热点循环);分析热点区域功能(数据流特征及处理逻辑),分析热点区域间调用关系,分析可并行特征和可并行模式。
分析本Benchmark采用的工具为:
Gprof:分析得到代码中热点函数
VTune:主要为分析具体热点函数中的热点循环区域
。。。
1.Clustering
本Benchmark库中的聚类算法总结了kmeans聚类和谱聚类两种算法,现分别进行分析
1.1 Kmeans聚类
此聚类算法中仅有一个函数,即为kmeans函数本身。
1.1.1热点函数分析
/****
** initialization */
for (h = i = 0; i < k; h += n / k, i++) {
c1[i] = (double*)calloc(m, sizeof(double));
if (!centroids) {
c[i] = (double*)calloc(m, sizeof(double));
}
/* pick k points as initial centroids */
for (j = m; j-- > 0; c[i][j] = data[h][j]);
}
/****
** main loop */
do {
/* save error from last step */
old_error = error, error = 0;
/* clear old counts and temp centroids */
for (i = 0; i < k; counts[i++] = 0) {
for (j = 0; j < m; c1[i][j++] = 0);
}
for (h = 0; h < n; h++) {
/* identify the closest cluster */
double min_distance = DBL_MAX;
for (i = 0; i < k; i++) {
double distance = 0;
//最耗时部分
for (j = m; j-- > 0; distance += pow(data[h][j] - c[i][j], 2));
if (distance < min_distance) {
labels[h] = i;
min_distance = distance;
}
}
/* update size and temp centroid of the destination cluster */
for (j = m; j-- > 0; c1[labels[h]][j] += data[h][j]);
counts[labels[h]]++;
/* update standard error */
error += min_distance;
}
for (i = 0; i < k; i++) { /* update all centroids */
for (j = 0; j < m; j++) {
c[i][j] = counts[i] ? c1[i][j] / counts[i] : c1[i][j];
}
}
} while (fabs(error - old_error) > t);
printf("ERROR AT K=%d is %lf \n", k, error);
1.1.2性能剖视结果
 从上图的剖视结果得到:
从上图的剖视结果得到:
主函数kmeans占据运行时间的100%,为整个代码的唯一耗时函数。
1.1.3热点循环分析
对耗时函数进行分析,热点循环体如下:
综合热点循环如下:
//三层循环@ly
for (h = 0; h < n; h++) {
/* identify the closest cluster */
double min_distance = DBL_MAX;
for (i = 0; i < k; i++) {
double distance = 0;
for (j = m; j-- > 0; distance += pow(data[h][j] - c[i][j], 2)); //第一耗时片段
if (distance < min_distance) {
labels[h] = i; //第二耗时片段
min_distance = distance;
}
}
/* update size and temp centroid of the destination cluster */
for (j = m; j-- > 0; c1[labels[h]][j] += data[h][j]);
counts[labels[h]]++;
/* update standard error */
error += min_distance;
}
1.1.4热点区域功能分析
1.2 Spectral(谱)聚类
此聚类算法中仅有一个函数,即为kmeans函数本身。
1.1.1热点函数分析
qrevec
int qrevec(double *ev,double *evec,double *dp,int n)
{ double cc,sc,d,x,y,h,tzr=1.e-15;
int i,j,k,m,mqr=8*n;
double *p;
for(j=0,m=n-1;;++j){
while(1){ if(m<1) return 0; k=m-1;
if(fabs(dp[k])<=fabs(ev[m])*tzr) --m;
else{ x=(ev[k]-ev[m])/2.; h=sqrt(x*x+dp[k]*dp[k]);
if(m>1 && fabs(dp[m-2])>fabs(ev[k])*tzr) break;
if((cc=sqrt((1.+x/h)/2.))!=0.) sc=dp[k]/(2.*cc*h); else sc=1.;
x+=ev[m]; ev[m--]=x-h; ev[m--]=x+h;
for(i=0,p=evec+n*(m+1); i<n ;++i,++p){
h=p[0]; p[0]=cc*h+sc*p[n]; p[n]=cc*p[n]-sc*h;
}
}
}
if(j>mqr) return -1;
if(x>0.) d=ev[m]+x-h; else d=ev[m]+x+h;
cc=1.; y=0.; ev[0]-=d;
for(k=0; k<m ;++k){
x=ev[k]*cc-y; y=dp[k]*cc; h=sqrt(x*x+dp[k]*dp[k]);
if(k>0) dp[k-1]=sc*h;
ev[k]=cc*h; cc=x/h; sc=dp[k]/h; ev[k+1]-=d; y*=sc;
ev[k]=cc*(ev[k]+y)+ev[k+1]*sc*sc+d;
for(i=0,p=evec+n*k; i<n ;++i,++p){
h=p[0]; p[0]=cc*h+sc*p[n]; p[n]=cc*p[n]-sc*h;
}
}
ev[k]=ev[k]*cc-y; dp[k-1]=ev[k]*sc; ev[k]=ev[k]*cc+d;
}
return 0;
}
#### housev
void housev(double *a,double *d,double *dp,int n)
{ double sc,x,y,h;
int i,j,k,m,e;
double *qw,*qs,*pc,*p;
qs=(double *)calloc(n,sizeof(double));
for(j=0,pc=a; j<n-2 ;++j,pc+=n+1){
m=n-j-1;
for(i=1,sc=0.; i<=m ;++i) sc+=pc[i]*pc[i];
if(sc>0.){ sc=sqrt(sc);
if((x= *(pc+1))<0.){ y=x-sc; h=1./sqrt(-2.*sc*y);}
else{ y=x+sc; h=1./sqrt(2.*sc*y); sc= -sc;}
for(i=0,qw=pc+1; i<m ;++i){
qs[i]=0.; if(i) qw[i]*=h; else qw[i]=y*h;
}
for(i=0,e=j+2,p=pc+n+1,h=0.; i<m ;++i,p+=e++){
qs[i]+=(y=qw[i])* *p++;
for(k=i+1; k<m ;++k){
qs[i]+=qw[k]* *p; qs[k]+=y* *p++;
}
h+=y*qs[i];
}
for(i=0; i<m ;++i){
qs[i]-=h*qw[i]; qs[i]+=qs[i];
}
for(i=0,e=j+2,p=pc+n+1; i<m ;++i,p+=e++){
for(k=i; k<m ;++k) *p++ -=qw[i]*qs[k]+qs[i]*qw[k];
}
}
d[j]= *pc; dp[j]=sc;
}
d[j]= *pc; dp[j]= *(pc+1); d[j+1]= *(pc+=n+1);
free(qs);
for(i=0,m=n+n,p=pc; i<m ;++i) *p-- =0.;
*pc=1.; *(pc-=n+1)=1.; qw=pc-n;
for(m=2; m<n ;++m,qw-=n+1){
for(j=0,p=pc,*pc=1.; j<m ;++j,p+=n){
for(i=0,qs=p,h=0.; i<m ;) h+=qw[i++]* *qs++;
for(i=0,qs=p,h+=h; i<m ;) *qs++ -=h*qw[i++];
}
for(i=0,p=qw+m; i<n ;++i) *(--p)=0.;
*(pc-=n+1)=1.;
}
}
1.1.2性能剖视结果
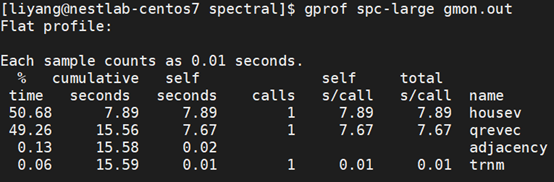
剖视结果可见,主要有两个热点函数:housev和qrevec
并且这两个热点函数为算法中调用的Eigen线性代数库的库函数。
1.1.3热点循环分析
对耗时函数进行分析,热点循环体如下:
(1)housev

(2)qrevec

(3)汇总两个热点函数中热点循环集合如下:
/* 1.housev */
//loop1
for(j=0,pc=a; j<n-2 ;++j,pc+=n+1){
m=n-j-1;
for(i=1,sc=0.; i<=m ;++i) sc+=pc[i]*pc[i];
if(sc>0.){ sc=sqrt(sc);
...
//loop1(1)四层循环
for(i=0,e=j+2,p=pc+n+1,h=0.; i<m ;++i,p+=e++){
qs[i]+=(y=qw[i])* *p++;
for(k=i+1; k<m ;++k){
qs[i]+=qw[k]* *p; qs[k]+=y* *p++; //最耗时片段
}
h+=y*qs[i];
...
//loop1(2)三层循环
for(i=0,e=j+2,p=pc+n+1; i<m ;++i,p+=e++){
for(k=i; k<m ;++k) *p++ -=qw[i]*qs[k]+qs[i]*qw[k];//最耗时片段
}
}
d[j]= *pc; dp[j]=sc;
}
//loop2-两层循环
for(m=2; m<n ;++m,qw-=n+1){
for(j=0,p=pc,*pc=1.; j<m ;++j,p+=n){
for(i=0,qs=p,h=0.; i<m ;) h+=qw[i++]* *qs++; //第一耗时片段
for(i=0,qs=p,h+=h; i<m ;) *qs++ -=h*qw[i++]; //第二耗时片段
}
for(i=0,p=qw+m; i<n ;++i) *(--p)=0.;
*(pc-=n+1)=1.;
}
/* 2.qrevec */
for(j=0,m=n-1;;++j){
...
if(j>mqr) return -1;
if(x>0.) d=ev[m]+x-h; else d=ev[m]+x+h;
cc=1.; y=0.; ev[0]-=d;
for(k=0; k<m ;++k){
x=ev[k]*cc-y; y=dp[k]*cc; h=sqrt(x*x+dp[k]*dp[k]);
if(k>0) dp[k-1]=sc*h;
ev[k]=cc*h; cc=x/h; sc=dp[k]/h; ev[k+1]-=d; y*=sc;
ev[k]=cc*(ev[k]+y)+ev[k+1]*sc*sc+d;
for(i=0,p=evec+n*k; i<n ;++i,++p){
h=p[0]; p[0]=cc*h+sc*p[n]; p[n]=cc*p[n]-sc*h; //最耗时片段
}
}
ev[k]=ev[k]*cc-y; dp[k-1]=ev[k]*sc; ev[k]=ev[k]*cc+d;
}
1.1.4热点区域功能分析
2.Lda
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。对本Benchmark中的LDA算法进行剖视,剖视结果如下。(部分执行时间较长的库函数: log_sse2, exp, mcount等未列入分析)
2.1 性能剖视结果
gprof与VTune 结果有一点差异
(1)Gprof结果
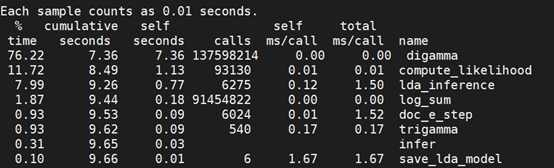
(2)VTune结果

2.2 热点函数分析
/* 1.digamma */
double digamma(double x)
{
double p;
x=x+6;
p=1/(x*x);
p=(((0.004166666666667*p-0.003968253986254)*p+
0.008333333333333)*p-0.083333333333333)*p;
p=p+log(x)-0.5/x-1/(x-1)-1/(x-2)-1/(x-3)-1/(x-4)-1/(x-5)-1/(x-6);
return p;
}
/* 2.lda_inference */
double lda_inference(document* doc, lda_model* model, double* var_gamma, double** phi)
{
double converged = 1;
double phisum = 0, likelihood = 0;
double likelihood_old = 0, oldphi[model->num_topics];
int k, n, var_iter;
double digamma_gam[model->num_topics];
// compute posterior dirichlet
for (k = 0; k < model->num_topics; k++)
{
var_gamma[k] = model->alpha + (doc->total/((double) model->num_topics));
digamma_gam[k] = digamma(var_gamma[k]);
for (n = 0; n
for (k = 0; k < model->num_topics; k++)
{
var_gamma[k] = model->alpha + (doc->total/((double) model->num_topics));
digamma_gam[k] = digamma(var_gamma[k]);
for (n = 0; n < doc->length; n++)
phi[n][k] = 1.0/model->num_topics;
}
var_iter = 0;
while ((converged > VAR_CONVERGED) &&
((var_iter < VAR_MAX_ITER) || (VAR_MAX_ITER == -1)))
{
var_iter++;
for (n = 0; n < doc->length; n++)
{
phisum = 0;
for (k = 0; k < model->num_topics; k++)
{
oldphi[k] = phi[n][k];
phi[n][k] =
digamma_gam[k] +
model->log_prob_w[k][doc->words[n]];
if (k > 0)
phisum = log_sum(phisum, phi[n][k]);
else
phisum = phi[n][k]; // note, phi is in log space
}
for (k = 0; k < model->num_topics; k++)
{
phi[n][k] = exp(phi[n][k] - phisum);
var_gamma[k] =
var_gamma[k] + doc->counts[n]*(phi[n][k] - oldphi[k]);
// !!! a lot of extra digamma's here because of how we're computing it
// !!! but its more automatically updated too.
digamma_gam[k] = digamma(var_gamma[k]);
}
}
likelihood = compute_likelihood(doc, model, phi, var_gamma);
assert(!isnan(likelihood));
converged = (likelihood_old - likelihood) / likelihood_old;
likelihood_old = likelihood;
// printf("[LDA INF] %8.5f %1.3e\n", likelihood, converged);
}
return(likelihood);
}
/* 3.compute likelihood */
double
compute_likelihood(document* doc, lda_model* model, double** phi, double* var_gamma)
{
double likelihood = 0, digsum = 0, var_gamma_sum = 0, dig[model->num_topics];}}
int k, n;
for (k = 0; k < model->num_topics; k++)
{
dig[k] = digamma(var_gamma[k]);
var_gamma_sum += var_gamma[k];
}
digsum = digamma(var_gamma_sum);
likelihood =
lgamma(model->alpha * model -> num_topics)
- model -> num_topics * lgamma(model->alpha)
- (lgamma(var_gamma_sum));
for (k = 0; k < model->num_topics; k++)
{
likelihood +=
(model->alpha - 1)*(dig[k] - digsum) + lgamma(var_gamma[k])
- (var_gamma[k] - 1)*(dig[k] - digsum);
for (n = 0; n < doc->length; n++)
{
if (phi[n][k] > 0)
{
likelihood += doc->counts[n]*
(phi[n][k]*((dig[k] - digsum) - log(phi[n][k])
+ model->log_prob_w[k][doc->words[n]]));
}
}
}
return(likelihood);
}
2.3热点循环分析
对耗时函数进行分析,热点循环体如下:
2.3.1 digamma

2.3.2 lda_inference

2.3.3 compute likelihood

2.3.4 汇总热点函数中热点循环
集合如下:
/* 1.digamma */
double p;
x=x+6;
p=1/(x*x);
p=(((0.004166666666667*p-0.003968253986254)*p+
0.008333333333333)*p-0.083333333333333)*p;
p=p+log(x)-0.5/x-1/(x-1)-1/(x-2)-1/(x-3)-1/(x-4)-1/(x-5)-1/(x-6);//最耗时片段
return p;
/* 2.compute_likelihood */
digsum = digamma(var_gamma_sum);
likelihood =
lgamma(model->alpha * model -> num_topics)
- model -> num_topics * lgamma(model->alpha)
- (lgamma(var_gamma_sum));
for (k = 0; k < model->num_topics; k++)
{
likelihood +=
(model->alpha - 1)*(dig[k] - digsum) + lgamma(var_gamma[k])
- (var_gamma[k] - 1)*(dig[k] - digsum);
for (n = 0; n < doc->length; n++)
{
if (phi[n][k] > 0)
{
likelihood += doc->counts[n]* //@ly 最耗时片段
(phi[n][k]*((dig[k] - digsum) - log(phi[n][k])
+ model->log_prob_w[k][doc->words[n]]));
}
}
}
/* 3.lda_inference */
while ((converged > VAR_CONVERGED) &&
((var_iter < VAR_MAX_ITER) || (VAR_MAX_ITER == -1)))
{
var_iter++;
//loop1(1) 三层循环
for (n = 0; n < doc->length; n++)
{
phisum = 0;
for (k = 0; k < model->num_topics; k++) //耗时片段
{
oldphi[k] = phi[n][k];
phi[n][k] =
digamma_gam[k] +
model->log_prob_w[k][doc->words[n]];
if (k > 0)
phisum = log_sum(phisum, phi[n][k]); //耗时片段
else
phisum = phi[n][k]; // note, phi is in log space
}
//loop1(2)三层循环
for (k = 0; k < model->num_topics; k++)
{
phi[n][k] = exp(phi[n][k] - phisum);
var_gamma[k] =
var_gamma[k] + doc->counts[n]*(phi[n][k] - oldphi[k]); //最耗时片段
// !!! a lot of extra digamma's here because of how we're computing it
// !!! but its more automatically updated too.
digamma_gam[k] = digamma(var_gamma[k]);
}
}
...
}
2.4 热点区域功能分析
3.Liblinear
liblinear是一个适用于大规模数据集的线性分类器,为libsvm的改进版本。
3.1 性能剖视结果
本Benchmark库liblinear剖视结果
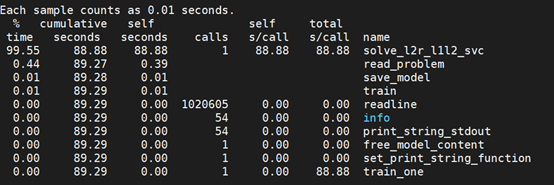
3.2 热点函数分析
/* solve_l2r_l1l2_svc */
static void solve_l2r_l1l2_svc(
const struct problem *prob, double *w, double eps,
double Cp, double Cn, int solver_type)
{
int l = prob->l;
int w_size = prob->n;
int i, s, iter = 0;
double C, d, G;
double *QD = (double*)malloc(l*sizeof(double));
int max_iter = 1000;
int *index = (int*)malloc(l*sizeof(int));
double *alpha = (double*)malloc(l*sizeof(double));
schar *y = (schar*)malloc(l*sizeof(schar));
int active_size = l;
// PG: projected gradient, for shrinking and stopping
double PG;
double PGmax_old = INF;
double PGmin_old = -INF;
double PGmax_new, PGmin_new;
// default solver_type: L2R_L2LOSS_SVC_DUAL
double diag[3] = {0.5/Cn, 0, 0.5/Cp};
double upper_bound[3] = {INF, 0, INF};
double v;
int nSV;
if(solver_type == L2R_L1LOSS_SVC_DUAL)
{
diag[0] = 0;
diag[2] = 0;
upper_bound[0] = Cn;
upper_bound[2] = Cp;
}
for(i=0; i<l; i++)
{
if(prob->y[i] > 0)
{
y[i] = +1;
}
else
{
y[i] = -1;
}
}
// Initial alpha can be set here. Note that
// 0 <= alpha[i] <= upper_bound[GETI(i)]
for(i=0; i<l; i++)
alpha[i] = 0;
for(i=0; i<w_size; i++)
w[i] = 0;
for(i=0; i<l; i++)
{
struct feature_node *xi;
QD[i] = diag[GETI(i)];
xi = prob->x[i];
while (xi->index != -1)
{
double val = xi->value;
QD[i] += val*val;
w[xi->index-1] += y[i]*alpha[i]*val;
xi++;
}
index[i] = i;
}
while (iter < max_iter)
{
PGmax_new = -INF;
PGmin_new = INF;
for (i=0; i<active_size; i++)
{
int j = i+rand()%(active_size-i);
//swapint(index[i], index[j]);
int swaptemp = index[i];
index[i] = index[j];
index[j] = swaptemp;
}
for (s=0; s<active_size; s++)
{
schar yi;
struct feature_node *xi;
i = index[s];
G = 0;
yi = y[i];
xi = prob->x[i];
while(xi->index!= -1)
{
G += w[xi->index-1]*(xi->value);
xi++;
}
G = G*yi-1;
C = upper_bound[GETI(i)];
G += alpha[i]*diag[GETI(i)];
PG = 0;
if (alpha[i] == 0)
{
if (G > PGmax_old)
{
int swaptemp;
active_size--;
//swapint(index[s], index[active_size]);
swaptemp = index[s];
index[s] = index[active_size];
index[active_size] = swaptemp;
s--;
continue;
}
else if (G < 0)
PG = G;
}
else if (alpha[i] == C)
{
if (G < PGmin_old)
{
int swaptemp;
active_size--;
//swapint(index[s], index[active_size]);
swaptemp = index[s];
index[s] = index[active_size];
index[active_size] = swaptemp;
s--;
continue;
}
else if (G > 0)
PG = G;
}
else
PG = G;
PGmax_new = (PGmax_new > PG)?PGmax_new : PG;
PGmin_new = (PGmin_new < PG)?PGmin_new : PG;
if(fabs(PG) > 1.0e-12)
{
double alpha_old = alpha[i];
alpha[i] = ((((alpha[i] - G/QD[i]) > 0.0)?(alpha[i] - G/QD[i]) : 0.0) < C)?(((alpha[i] - G/QD[i]) > 0.0)?(alpha[i] - G/QD[i]) : 0.0) : C;
d = (alpha[i] - alpha_old)*yi;
xi = prob->x[i];
while (xi->index != -1)
{
w[xi->index-1] += d*xi->value;
xi++;
}
}
}
iter++;
if(iter % 10 == 0)
info(".");
if(PGmax_new - PGmin_new <= eps)
{
if(active_size == l)
break;
else
{
active_size = l;
info("*");
PGmax_old = INF;
PGmin_old = -INF;
continue;
}
}
PGmax_old = PGmax_new;
PGmin_old = PGmin_new;
if (PGmax_old <= 0)
PGmax_old = INF;
if (PGmin_old >= 0)
PGmin_old = -INF;
}
info("\noptimization finished, #iter = %d\n",iter);
if (iter >= max_iter)
info("\nWARNING: reaching max number of iterations\nUsing -s 2 may be faster (also see FAQ)\n\n");
// calculate objective value
v = 0;
nSV = 0;
for(i=0; i<w_size; i++)
v += w[i]*w[i];
for(i=0; i<l; i++)
{
v += alpha[i]*(alpha[i]*diag[GETI(i)] - 2);
if(alpha[i] > 0)
++nSV;
}
info("Objective value = %lf\n",v/2);
info("nSV = %d\n",nSV);
free(QD);
free(alpha);
free(y);
free(index);
}
3.3热点循环分析
对耗时函数进行分析,热点循环体如下:


汇总热点函数中热点循环
集合如下:
/* solve_l2r_l1l2_svc */
while (iter < max_iter)
{
PGmax_new = -INF;
PGmin_new = INF;
//loop1(1) 两层循环 在函数中耗时占比1.7%
for (i=0; i<active_size; i++)
{
int j = i+rand()%(active_size-i);
//swapint(index[i], index[j]);
int swaptemp = index[i];
index[i] = index[j]; //耗时占比1%
index[j] = swaptemp;
}
//loop1(2)三层循环 本循环在函数中耗时占比最高:71.2%
for (s=0; s<active_size; s++)
{
schar yi;
struct feature_node *xi;
i = index[s]; //循环内 耗时第三片段 12.3%
G = 0;
yi = y[i];
xi = prob->x[i];
while(xi->index!= -1) //循环内 耗时第一片段 29.3%
{
G += w[xi->index-1]*(xi->value);
xi++; //循环内 耗时第二片段 24.2%
}
//loop1(3)两层循环 本循环在函数中耗时占比:4%
G = G*yi-1;
C = upper_bound[GETI(i)];
G += alpha[i]*diag[GETI(i)];
...
//loop1(4)四层循环 本循环在函数中耗时占比:9.5%
PGmax_new = (PGmax_new > PG)?PGmax_new : PG;
PGmin_new = (PGmin_new < PG)?PGmin_new : PG;
if(fabs(PG) > 1.0e-12)
{
double alpha_old = alpha[i];
alpha[i] = ((((alpha[i] - G/QD[i]) > 0.0)?(alpha[i] - G/QD[i]) : 0.0) < C)?(((alpha[i] - G/QD[i]) > 0.0)?(alpha[i] - G/QD[i]) : 0.0) : C; // 循环内 耗时第一片段 4.3%
d = (alpha[i] - alpha_old)*yi;
xi = prob->x[i];
while (xi->index != -1) //循环内 耗时第三片段 1.8%
{
w[xi->index-1] += d*xi->value; //循环内 耗时第二片段 2.5%
xi++;
}
}
}
...
}
3.4 热点区域功能分析
4.Motion-estimation
运动估计用于确定描述一个2D图像到另一个2D图像的变换的运动矢量。
4.1 性能剖视结果
本Benchmark库me剖视结果
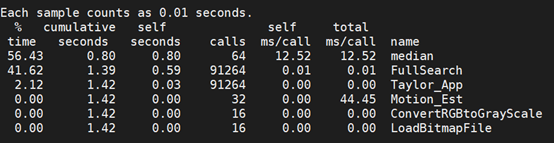
4.2 热点函数分析
/* 1.median */
double median(double *num, int length)
{
int i, j, flag = 1; // set flag to 1 to start first pass
double temp; // holding variable
int numLength = length;
//for (int i = 0; i < numLength; i++)
// printf("num[%d] = %lf\n", i, num[i]);
for (i = 1; (i <= numLength) && flag; i++)
{
flag = 0;
for (j = 0; j < (numLength - 1); j++)
{
if (num[j + 1] > num[j]) // ascending order simply changes to <
{
temp = num[j]; // swap elements
num[j] = num[j + 1];
num[j + 1] = temp;
flag = 1;
/* 2.FullSearch */
void FullSearch(Image* block, Image* img_ref, int yc, int xc, int SearchLimit, int BlockSize, double* dx, double* dy)
{
int xt, yt, x_min = 0, y_min = 0;
double SADmin = 100000.0;
double MVx_int = 0, MVy_int = 0;
double* block_ref;
int i, j, ii, jj;
for (i = -SearchLimit; i < SearchLimit; i++)
{
for (j = -SearchLimit; j < SearchLimit; j++)
{
xt = xc + j;
yt = yc + i;
block_ref = img_ref->data + yt*(img_ref->x_length) + xt;
//SAD = sum(abs(Block(:) - Block_ref(:))) / (BlockSize ^ 2);
double SAD = 0;
for (ii = 0; ii < BlockSize; ii++)
{
for (jj = 0; jj < BlockSize; jj++)
{
SAD += abs(block->data[ii*(block->x_length) + jj] - block_ref[ii*(img_ref->x_length) + jj]);
//SAD += abs((block->data[ii*(block->x_length) + jj] * block->data[ii*(block->x_length) + jj]) - (block_ref[ii*(img_ref->x_length) + jj] * block_ref[ii*(img_ref->x_length) + jj]));
}
}
SAD = SAD / (BlockSize*BlockSize);
if (SAD < SADmin)
{
SADmin = SAD;
x_min = xt;
y_min = yt;
}
//MVx_int = xc - x_min;
//MVy_int = yc - y_min;
MVx_int = x_min - xc;
MVy_int = y_min - yc;
}
}
Image block_ref1;
double MVx_frac = 0, MVy_frac = 0;
block_ref1.x_length = img_ref->x_length;
block_ref1.y_length = img_ref->y_length;
block_ref1.data = img_ref->data + y_min*(img_ref->x_length) + x_min;
//block_ref1.data = img_ref->data + yc*(img_ref->x_length) + xc;
Taylor_App(block, &block_ref1, BlockSize, &MVx_frac, &MVy_frac);
*dx = MVx_int + MVx_frac;
//*dx = MVx_frac;
*dy = MVy_int + MVy_frac;
//*dy = MVy_frac;
}
4.3热点循环分析
对耗时函数进行分析,热点循环体如下:
(1)median

(2)FullSearch

汇总热点函数中热点循环
集合如下:
/* 1.median */
//本函数就一个三层循环
for (i = 1; (i <= numLength) && flag; i++)
{
flag = 0;
for (j = 0; j < (numLength - 1); j++) //3.4%
{
if (num[j + 1] > num[j]) //循环内 耗时第一片段: 33.6%
// ascending order simply changes to <
{
temp = num[j]; // swap elements
num[j] = num[j + 1]; // 3.8%
num[j + 1] = temp; //@ly 循环内耗时第二片段: 9%
flag = 1; // 3.0%
// indicates that a swap occurred.
}
}
}
/* 2.FullSearch */
//loop1(1)四层循环 本循环在函数中耗时最高 38.7%(占总算法百分比)
for (i = -SearchLimit; i < SearchLimit; i++)
{
for (j = -SearchLimit; j < SearchLimit; j++)
{
xt = xc + j;
yt = yc + i;
block_ref = img_ref->data + yt*(img_ref->x_length) + xt;
//SAD = sum(abs(Block(:) - Block_ref(:))) / (BlockSize ^ 2);
double SAD = 0;
for (ii = 0; ii < BlockSize; ii++) // 占比2.5%
{
for (jj = 0; jj < BlockSize; jj++) // 占比8.5%
{
SAD += abs(block->data[ii*(block->x_length) + jj] - block_ref[ii*(img_ref->x_length) + jj]); //循环内 耗时第一片段: 27.7%
//SAD += abs((block->data[ii*(block->x_length) + jj] * block->data[ii*(block->x_length) + jj]) - (block_ref[ii*(img_ref->x_length) + jj] * block_ref[ii*(img_ref->x_length) + jj]));
}
}
//loop1(2)就单条if语句,为三层循环
SAD = SAD / (BlockSize*BlockSize);
if (SAD < SADmin) // 3%
...
}
}
4.4 热点区域功能分析
5.PCA
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。
5.1 性能剖视结果
本Benchmark库pca剖视结果
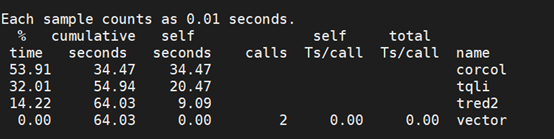
5.2 热点函数分析
/* 1.corcol */
void corcol(data, n, m, symmat)
float **data, **symmat;
int n, m;
/* Create m * m correlation matrix from given n * m data matrix. */
{
float eps = 0.005;
float x, *mean, *stddev, *vector();
int i, j, j1, j2;
/* Allocate storage for mean and std. dev. vectors */
mean = vector(m);
stddev = vector(m);
/* Determine mean of column vectors of input data matrix */
for (j = 1; j <= m; j++)
{
mean[j] = 0.0;
for (i = 1; i <= n; i++)
{
mean[j] += data[i][j];
}
mean[j] /= (float)n;
}
/*ZPRINT
printf("\nMeans of column vectors:\n");
for (j = 1; j <= m; j++) {
printf("%7.1f",mean[j]); } printf("\n");
*/
/* Determine standard deviations of column vectors of data matrix. */
for (j = 1; j <= m; j++)
{
stddev[j] = 0.0;
for (i = 1; i <= n; i++)
{
stddev[j] += ( ( data[i][j] - mean[j] ) *
( data[i][j] - mean[j] ) );
}
stddev[j] /= (float)n;
stddev[j] = sqrt(stddev[j]);
/* The following in an inelegant but usual way to handle
near-zero std. dev. values, which below would cause a zero-
divide. */
if (stddev[j] <= eps) stddev[j] = 1.0;
}
/*ZPRINT
printf("\nStandard deviations of columns:\n");
for (j = 1; j <= m; j++) { printf("%7.1f", stddev[j]); }
printf("\n");
*/
/* Center and reduce the column vectors. */
for (i = 1; i <= n; i++)
{
for (j = 1; j <= m; j++)
{
data[i][j] -= mean[j];
x = sqrt((float)n);
x *= stddev[j];
data[i][j] /= x;
}
}
/* Calculate the m * m correlation matrix. */
for (j1 = 1; j1 <= m-1; j1++)
{
symmat[j1][j1] = 1.0;
for (j2 = j1+1; j2 <= m; j2++)
{
symmat[j1][j2] = 0.0;
for (i = 1; i <= n; i++)
{
symmat[j1][j2] += ( data[i][j1] * data[i][j2]);
}
symmat[j2][j1] = symmat[j1][j2];
}
}
symmat[m][m] = 1.0;
return;
}
/* 2.tqli */
void tqli(d, e, n, z)
float d[], e[], **z;
int n;
{
int m, l, iter, i, k;
float s, r, p, g, f, dd, c, b;
void erhand();
for (i = 2; i <= n; i++)
e[i-1] = e[i];
e[n] = 0.0;
for (l = 1; l <= n; l++)
{
iter = 0;
do
{
for (m = l; m <= n-1; m++)
{
dd = fabs(d[m]) + fabs(d[m+1]);
if (fabs(e[m]) + dd == dd) break;
}
if (m != l)
{
if (iter++ == 3000) erhand("No convergence in TLQI.");
g = (d[l+1] - d[l]) / (2.0 * e[l]);
r = sqrt((g * g) + 1.0);
g = d[m] - d[l] + e[l] / (g + SIGN(r, g));
s = c = 1.0;
p = 0.0;
for (i = m-1; i >= l; i--)
{
f = s * e[i];
b = c * e[i];
if (fabs(f) >= fabs(g))
{
c = g / f;
r = sqrt((c * c) + 1.0);
e[i+1] = f * r;
c *= (s = 1.0/r);
}
else
{
s = f / g;
r = sqrt((s * s) + 1.0);
e[i+1] = g * r;
s *= (c = 1.0/r);
}
g = d[i+1] - p;
r = (d[i] - g) * s + 2.0 * c * b;
p = s * r;
d[i+1] = g + p;
g = c * r - b;
for (k = 1; k <= n; k++)
{
f = z[k][i+1];
z[k][i+1] = s * z[k][i] + c * f;
z[k][i] = c * z[k][i] - s * f;
}
}
d[l] = d[l] - p;
e[l] = g;
e[m] = 0.0;
}
} while (m != l);
}
}
/* 3.tred2 */
void tred2(a, n, d, e)
float **a, *d, *e;
/* float **a, d[], e[]; */
int n;
/* Householder reduction of matrix a to tridiagonal form.
Algorithm: Martin et al., Num. Math. 11, 181-195, 1968.
Ref: Smith et al., Matrix Eigensystem Routines -- EISPACK Guide
Springer-Verlag, 1976, pp. 489-494.
W H Press et al., Numerical Recipes in C, Cambridge U P,
1988, pp. 373-374. */
{
int l, k, j, i;
float scale, hh, h, g, f;
for (i = n; i >= 2; i--)
{
l = i - 1;
h = scale = 0.0;
if (l > 1)
{
for (k = 1; k <= l; k++)
scale += fabs(a[i][k]);
if (scale == 0.0)
e[i] = a[i][l];
else
{
for (k = 1; k <= l; k++)
{
a[i][k] /= scale;
h += a[i][k] * a[i][k];
}
f = a[i][l];
g = f>0 ? -sqrt(h) : sqrt(h);
e[i] = scale * g;
h -= f * g;
a[i][l] = f - g;
f = 0.0;
for (j = 1; j <= l; j++)
{
a[j][i] = a[i][j]/h;
g = 0.0;
for (k = 1; k <= j; k++)
g += a[j][k] * a[i][k];
for (k = j+1; k <= l; k++)
g += a[k][j] * a[i][k];
e[j] = g / h;
f += e[j] * a[i][j];
}
hh = f / (h + h);
for (j = 1; j <= l; j++)
{
f = a[i][j];
e[j] = g = e[j] - hh * f;
for (k = 1; k <= j; k++)
a[j][k] -= (f * e[k] + g * a[i][k]);
}
}
}
else
e[i] = a[i][l];
d[i] = h;
}
d[1] = 0.0;
e[1] = 0.0;
for (i = 1; i <= n; i++)
{
l = i - 1;
if (d[i])
{
for (j = 1; j <= l; j++)
{
g = 0.0;
for (k = 1; k <= l; k++)
g += a[i][k] * a[k][j];
for (k = 1; k <= l; k++)
a[k][j] -= g * a[k][i];
}
}
d[i] = a[i][i];
a[i][i] = 1.0;
for (j = 1; j <= l; j++)
a[j][i] = a[i][j] = 0.0;
}
}
5.3热点循环分析
对耗时函数进行分析,热点循环体如下:
(1)corcol

(2)tqli

(3)tred2

汇总热点函数中热点循环
集合如下:
/* 1.corcol */
// 耗时最高的循环
xunhuan
/* Calculate the m * m correlation matrix. */
for (j1 = 1; j1 <= m-1; j1++)
{
symmat[j1][j1] = 1.0;
for (j2 = j1+1; j2 <= m; j2++)
{
symmat[j1][j2] = 0.0;
for (i = 1; i <= n; i++) //3.6%
{
symmat[j1][j2] += ( data[i][j1] * data[i][j2]); //48%
}
symmat[j2][j1] = symmat[j1][j2];
}
}
symmat[m][m] = 1.0;
return;
/* 2.tqli */
//五层循环 耗时占比 32.9%
for (l = 1; l <= n; l++)
{
iter = 0;
do
{
for (m = l; m <= n-1; m++)
...
if (m != l)
{
if (iter++ == 3000) erhand("No convergence in TLQI.");
g = (d[l+1] - d[l]) / (2.0 * e[l]);
r = sqrt((g * g) + 1.0);
g = d[m] - d[l] + e[l] / (g + SIGN(r, g));
s = c = 1.0;
p = 0.0;
for (i = m-1; i >= l; i--)
{
f = s * e[i];
b = c * e[i];
...(无关循环)
g = d[i+1] - p;
r = (d[i] - g) * s + 2.0 * c * b;
p = s * r;
d[i+1] = g + p;
g = c * r - b;
//占比时间集中在最内层循环
for (k = 1; k <= n; k++) //1.1%
{
f = z[k][i+1]; //18.8%
z[k][i+1] = s * z[k][i] + c * f; //8.2%
z[k][i] = c * z[k][i] - s * f; //4.8%
}
}
...
}
} while (m != l);
}
/* 3.tred2 */
//loop1 四层循环 本循环耗时 2.6%(占总算法百分比)
for (i = n; i >= 2; i--)
{
l = i - 1;
h = scale = 0.0;
if (l > 1)
{
for (k = 1; k <= l; k++)
scale += fabs(a[i][k]);
if (scale == 0.0)
e[i] = a[i][l];
else
{
...
f = a[i][l];
g = f>0 ? -sqrt(h) : sqrt(h);
e[i] = scale * g;
h -= f * g;
a[i][l] = f - g;
f = 0.0;
for (j = 1; j <= l; j++)
{
a[j][i] = a[i][j]/h;
g = 0.0;
for (k = 1; k <= j; k++)
g += a[j][k] * a[i][k];
for (k = j+1; k <= l; k++)
g += a[k][j] * a[i][k]; //占比1.5%
e[j] = g / h;
f += e[j] * a[i][j];
}
...
}
}
}
//loop2 三层循环
for (i = 1; i <= n; i++)
{
l = i - 1;
if (d[i])
{
for (j = 1; j <= l; j++)
{
g = 0.0;
for (k = 1; k <= l; k++)
g += a[i][k] * a[k][j]; //占比4.9%
for (k = 1; k <= l; k++)
a[k][j] -= g * a[k][i]; //占比5.5%
}
}
...
}
5.4 热点区域功能分析
6.rbm
受限玻尔兹曼机(Restricted Boltzmann Machine)是一个两层的神经网络,是基于能量的概率分布模型。
6.1 性能剖视结果
本Benchmark库rbm剖视结果
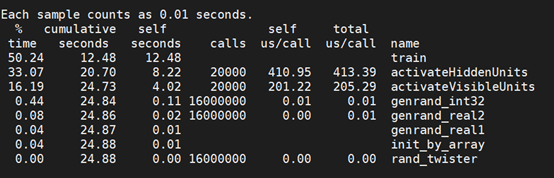
6.2 热点函数分析
/* 1.activateHiddenUnits */
void activateHiddenUnits(int visible[], int stochastic, int hidden[])
{
// Calculate activation energy for hidden units
double hiddenEnergies[NUM_HIDDEN];
int h;
for (h = 0; h < NUM_HIDDEN; h++)
{
// Get the sum of energies
double sum = 0;
int v;
for (v = 0; v < NUM_VISIBLE + 1; v++) // remove the +1 if you want to skip the bias
{
if (visible[v] != -1)
sum += (double) visible[v] * edges[v][h];
}
hiddenEnergies[h] = sum;
}
// Activate hidden units
for (h = 0; h < NUM_HIDDEN; h++)
{
double prob = 1.0 / (1.0 + exp(-hiddenEnergies[h]));
if (stochastic)
{
if (RAND < prob)
hidden[h] = 1;
else
hidden[h] = 0;
}
else
{
if (prob > 0.5)
hidden[h] = 1;
else
hidden[h] = 0;
}
}
hidden[NUM_HIDDEN] = 1; // turn on bias
}
/* 2.train */
void train()
{
int user;
for (user = 0; user < USERS; user++)
{
// ==> Phase 1: Activate hidden units
int data[NUM_VISIBLE + 1];
memcpy(data, trainingData[user], NUM_VISIBLE * sizeof(int)); // copy entire array
data[NUM_VISIBLE] = 1; // turn on bias
// Activate hidden units
int hidden[NUM_HIDDEN + 1];
activateHiddenUnits(data, 1, hidden);
// Get positive association
int pos[NUM_VISIBLE + 1][NUM_HIDDEN + 1];
int v;
for (v = 0; v < NUM_VISIBLE + 1; v++)
{
if (data[v] != -1)
{
int h;
for (h = 0; h < NUM_HIDDEN + 1; h++)
pos[v][h] = data[v] * hidden[h];
}
}
// ==> Phase 2: Reconstruction (activate visible units)
// Activate visible units
int visible[NUM_VISIBLE + 1];
activateVisibleUnits(hidden, 1, visible);
// Get negative association
int neg[NUM_VISIBLE + 1][NUM_HIDDEN + 1];
for (v = 0; v < NUM_VISIBLE + 1; v++)
{
if (data[v] != -1)
{
int h;
for (h = 0; h < NUM_HIDDEN + 1; h++)
neg[v][h] = hidden[h] * visible[v];
}
}
// ==> Phase 3: Update the weights
for (v = 0; v < NUM_VISIBLE + 1; v++)
{
int h;
for (h = 0; h < NUM_HIDDEN + 1; h++)
edges[v][h] = edges[v][h] + LEARN_RATE * (pos[v][h] - neg[v][h]);
}
}
}
/* 3.activateVisibleUnits */
void activateVisibleUnits(int hidden[], int stochastic, int visible[])
{
// Calculate activation energy for visible units
double visibleEnergies[NUM_VISIBLE];
int v;
for (v = 0; v < NUM_VISIBLE; v++)
{
// Get the sum of energies
double sum = 0;
int h;
for (h = 0; h < NUM_HIDDEN + 1; h++) // remove the +1 if you want to skip the bias
sum += (double) hidden[h] * edges[v][h];
visibleEnergies[v] = sum;
}
// Activate visible units, handles K visible units at a time
for (v = 0; v < NUM_VISIBLE; v += K)
{
double exps[K]; // this is the numerator
double sumOfExps = 0.0; // this is the denominator
int j;
for (j = 0; j < K; j++)
{
exps[j] = exp(visibleEnergies[v + j]);
sumOfExps += exps[j];
}
// Getting the probabilities
double probs[K];
for (j = 0; j < K; j++)
probs[j] = exps[j] / sumOfExps;
// Activate units
if (stochastic) // used for training
{
for (j = 0; j < K; j++)
{
if (RAND < probs[j])
visible[v + j] = 1;
else
visible[v + j] = 0;
}
}
else // used for prediction: uses expectation
{
double expectation = 0.0;
for (j = 0; j < K; j++)
expectation += j * probs[j]; // we will predict rating between 0 to K-1, not between 1 to K
long prediction = round(expectation);
for (j = 0; j < K; j++)
{
if (j == prediction)
visible[v + j] = 1;
else
visible[v + j] = 0;
}
}
}
visible[NUM_VISIBLE] = 1; // turn on bias
}
6.3热点循环分析
对耗时函数进行分析,热点循环体如下:
(1)activateHiddenUnits

(2)train

(3)activateVisibleUnits

汇总热点函数中热点循环
集合如下:
/* 1.activateHiddenUnits */
//两层循环 耗时占比 40.7%
for (h = 0; h < NUM_HIDDEN; h++)
{
// Get the sum of energies
double sum = 0;
int v;
for (v = 0; v < NUM_VISIBLE + 1; v++) // remove the +1 if you want to skip the bias
{
if (visible[v] != -1) // 3.2%
sum += (double) visible[v] * edges[v][h]; //37.5%
}
hiddenEnergies[h] = sum;
}
/* 2.train */
// loop1 三层循环:包含三个子循环
for (user = 0; user < USERS; user++)
{
...
// ==> Phase 1: Activate hidden units
//loop1(1) 耗时占比5.6%
for (v = 0; v < NUM_VISIBLE + 1; v++)
{
if (data[v] != -1) //0.1%
{
int h;
for (h = 0; h < NUM_HIDDEN + 1; h++) //0.5%
pos[v][h] = data[v] * hidden[h]; //5.4%
}
}
...
// ==> Phase 2: Reconstruction (activate visible units
//loop1(2) 耗时占比6.7%
for (v = 0; v < NUM_VISIBLE + 1; v++)
{
if (data[v] != -1) //0.2%
{
int h;
for (h = 0; h < NUM_HIDDEN + 1; h++) //0.4%
neg[v][h] = hidden[h] * visible[v]; //6.1%
}
}
// ==> Phase 3: Update the weights
//loop1(3) 耗时占比24.8%
for (v = 0; v < NUM_VISIBLE + 1; v++)
{
int h;
for (h = 0; h < NUM_HIDDEN + 1; h++) //0.5%
edges[v][h] = edges[v][h] + LEARN_RATE * (pos[v][h] - neg[v][h]); //24.3%
}
}
}
/* 3.activateVisibleUnits */
//两层循环 本循环在函数中耗时 12.8%
for (v = 0; v < NUM_VISIBLE; v++)
{
// Get the sum of energies
double sum = 0;
int h;
for (h = 0; h < NUM_HIDDEN + 1; h++) // 占比3.5%
// remove the +1 if you want to skip the bias
sum += (double) hidden[h] * edges[v][h]; // 9.3%
visibleEnergies[v] = sum;
}
6.4 热点区域功能分析
7.sphinx
CMU Sphinx(简称Sphinx)是卡内基梅隆大学开发的开源语音识别系统。
Sphinx speech recognition has a number hidden markov
model computations that cause slowdown in the application.
The recognizing algorithm utilizes Viterbi algorithm, Hidden Markov Model (HMM), and n-gram language model.
The HMM in this program take a big part of the total
runtime, the majority of which is located in two main operations. This includes the evaluation of finding the optimal HMM
sequence using the Viterbi algorithm, a dynamic programming
algorithm [18] and the search of most likely sentence using n-gram model [19].
7.1 性能剖视结果
本Benchmark库rbm剖视结果
(1)Gprof

(2)VTune

对比两个工具可见:
gprof的函数时间是total时间,如在性能列表中仅列出了prune_channels父函数所有的时间;而VTune中显示了三个子函数的各自耗时,隐藏了父函数 prune_channels
7.2 热点函数分析
仅截取耗时占比超过5%的函数分析,由于代码过长仅放置耗时最长的三个函数,其他的函数热点区域请看热点循环分析。
/* 1.prune_nonroot_chan */
prune_nonroot_chan(ngram_search_t *ngs, int frame_idx)
{
chan_t *hmm, *nexthmm;
int32 nf, w, i;
int32 thresh, newphone_thresh, lastphn_thresh, newphone_score;
chan_t **acl, **nacl; /* active list, next active list */
lastphn_cand_t *candp;
phone_loop_search_t *pls;
nf = frame_idx + 1;
thresh = ngs->best_score + ngs->dynamic_beam;
newphone_thresh = ngs->best_score + ngs->pbeam;
lastphn_thresh = ngs->best_score + ngs->lpbeam;
pls = (phone_loop_search_t *)ps_search_lookahead(ngs);
acl = ngs->active_chan_list[frame_idx & 0x1]; /* currently active HMMs in tree */
nacl = ngs->active_chan_list[nf & 0x1] + ngs->n_active_chan[nf & 0x1];
for (i = ngs->n_active_chan[frame_idx & 0x1], hmm = *(acl++); i > 0;
--i, hmm = *(acl++)) {
assert(hmm_frame(&hmm->hmm) >= frame_idx);
if (hmm_bestscore(&hmm->hmm) BETTER_THAN thresh) {
/* retain this channel in next frame */
if (hmm_frame(&hmm->hmm) != nf) {
hmm_frame(&hmm->hmm) = nf;
*(nacl++) = hmm;
}
/* transition to all next-level channel in the HMM tree */
newphone_score = hmm_out_score(&hmm->hmm) + ngs->pip;
if (pls != NULL || newphone_score BETTER_THAN newphone_thresh) {
for (nexthmm = hmm->next; nexthmm; nexthmm = nexthmm->alt) {
int32 pl_newphone_score = newphone_score
+ phone_loop_search_score(pls, nexthmm->ciphone);
if ((pl_newphone_score BETTER_THAN newphone_thresh)
&& ((hmm_frame(&nexthmm->hmm) < frame_idx)
|| (pl_newphone_score
BETTER_THAN hmm_in_score(&nexthmm->hmm)))) {
if (hmm_frame(&nexthmm->hmm) != nf) {
/* Keep this HMM on the active list */
*(nacl++) = nexthmm;
}
hmm_enter(&nexthmm->hmm, pl_newphone_score,
hmm_out_history(&hmm->hmm), nf);
}
}
}
/*
* Transition to last phone of all words for which this is the
* penultimate phone (the last phones may need multiple right contexts).
* Remember to remove the temporary newword_penalty.
*/
if (pls != NULL || newphone_score BETTER_THAN lastphn_thresh) {
for (w = hmm->info.penult_phn_wid; w >= 0;
w = ngs->homophone_set[w]) {
int32 pl_newphone_score = newphone_score
+ phone_loop_search_score
(pls, dict_last_phone(ps_search_dict(ngs),w));
if (pl_newphone_score BETTER_THAN lastphn_thresh) {
candp = ngs->lastphn_cand + ngs->n_lastphn_cand;
ngs->n_lastphn_cand++;
candp->wid = w;
candp->score =
pl_newphone_score - ngs->nwpen;
candp->bp = hmm_out_history(&hmm->hmm);
}
}
}
}
else if (hmm_frame(&hmm->hmm) != nf) {
hmm_clear(&hmm->hmm);
}
}
ngs->n_active_chan[nf & 0x1] = nacl - ngs->active_chan_list[nf & 0x1];
}
/* 2.acmod_activate_hmm */
void
acmod_activate_hmm(acmod_t *acmod, hmm_t *hmm)
{
int i;
if (acmod->compallsen)
return;
if (hmm_is_mpx(hmm)) {
switch (hmm_n_emit_state(hmm)) {
case 5:
MPX_BITVEC_SET(acmod, hmm, 4);
MPX_BITVEC_SET(acmod, hmm, 3);
case 3:
MPX_BITVEC_SET(acmod, hmm, 2);
MPX_BITVEC_SET(acmod, hmm, 1);
MPX_BITVEC_SET(acmod, hmm, 0);
break;
default:
for (i = 0; i < hmm_n_emit_state(hmm); ++i) {
MPX_BITVEC_SET(acmod, hmm, i);
}
}
}
else {
switch (hmm_n_emit_state(hmm)) {
case 5:
NONMPX_BITVEC_SET(acmod, hmm, 4);
NONMPX_BITVEC_SET(acmod, hmm, 3);
case 3:
NONMPX_BITVEC_SET(acmod, hmm, 2);
NONMPX_BITVEC_SET(acmod, hmm, 1);
NONMPX_BITVEC_SET(acmod, hmm, 0);
break;
default:
for (i = 0; i < hmm_n_emit_state(hmm); ++i) {
NONMPX_BITVEC_SET(acmod, hmm, i);
}
}
}
}
/* 3.hmm_vit_eval */
int32
hmm_vit_eval(hmm_t * hmm)
{
if (hmm_is_mpx(hmm)) {
if (hmm_n_emit_state(hmm) == 5)
return hmm_vit_eval_5st_lr_mpx(hmm);
else if (hmm_n_emit_state(hmm) == 3)
return hmm_vit_eval_3st_lr_mpx(hmm);
else
return hmm_vit_eval_anytopo(hmm);
}
else {
if (hmm_n_emit_state(hmm) == 5)
return hmm_vit_eval_5st_lr(hmm);
else if (hmm_n_emit_state(hmm) == 3)
return hmm_vit_eval_3st_lr(hmm);
else
return hmm_vit_eval_anytopo(hmm);
}
}
7.3热点循环分析
对耗时函数进行分析,热点循环体如下:
(1)prune_nonroot_chan

(2)last_phone_transition

(3)prune_root_chan

(4)acmod_activate_hmm

(5)hmm_vit_eval

(6)find_bg

(7)ngram_model_set_score

汇总热点函数中热点循环
集合如下:
/* 1.prune_nonroot_chan */
// 循环体内if语句中计算最为耗时
for (i = ngs->n_active_chan[frame_idx & 0x1], hmm = *(acl++); i > 0;
--i, hmm = *(acl++))
{
assert(hmm_frame(&hmm->hmm) >= frame_idx); //1.9%
if (hmm_bestscore(&hmm->hmm) BETTER_THAN thresh)
{
...
newphone_score = hmm_out_score(&hmm->hmm) + ngs->pip;
if (pls != NULL || newphone_score BETTER_THAN newphone_thresh)
{
for (nexthmm = hmm->next; nexthmm; nexthmm = nexthmm->alt)
{
int32 pl_newphone_score = newphone_score
+ phone_loop_search_score(pls, nexthmm->ciphone);
//整个if判断语句 占比2.7%
if ((pl_newphone_score BETTER_THAN newphone_thresh)
&& ((hmm_frame(&nexthmm->hmm) < frame_idx)
|| (pl_newphone_score
BETTER_THAN hmm_in_score(&nexthmm->hmm))))
/* {
if (hmm_frame(&nexthmm->hmm) != nf)
{
*(nacl++) = nexthmm;
} */
...
}
}
}
if (pls != NULL || ...
}
/* 2.last_phone_transition */
//loop1 一层for循环 调用了ngram_search_exit_score函数,较为耗时
for (i = 0, candp = ngs->lastphn_cand; i < ngs->n_lastphn_cand; i++, candp++)
{
int32 start_score;
if (candp->bp == -1)
continue;
bpe = &(ngs->bp_table[candp->bp]);
start_score = ngram_search_exit_score //0.9%
(ngs, bpe, dict_first_phone(ps_search_dict(ngs), candp->wid));
/*
assert(start_score BETTER_THAN WORST_SCORE);
candp->score -= start_score;
...
*/
//loop2 三层for循环,调用了ngram_search_exit_score函数,较为耗时
for (i = 0; i < n_cand_sf; i++)
{
/* For the i-th unique end frame... */
bp = ngs->bp_table_idx[ngs->cand_sf[i].bp_ef];
bpend = ngs->bp_table_idx[ngs->cand_sf[i].bp_ef + 1];
for (bpe = &(ngs->bp_table[bp]); bp < bpend; bp++, bpe++) //0.4%
{
if (!bpe->valid)
continue;
for (j = ngs->cand_sf[i].cand; j >= 0; j = candp->next)
{
int32 n_used;
candp = &(ngs->lastphn_cand[j]);
dscr = ngram_search_exit_score
(ngs, bpe, dict_first_phone(ps_search_dict(ngs), candp->wid)); //1.3%
...
}
}
}
/* 3.prune_root_chan */
//两层循环
for (i = 0, rhmm = ngs->root_chan; i < ngs->n_root_chan; i++, rhmm++) {
E_DEBUG(3,("Root channel %d frame %d score %d thresh %d\n",
i, hmm_frame(&rhmm->hmm), hmm_bestscore(&rhmm->hmm), thresh));
/* 不耗时
if (hmm_frame(&rhmm->hmm) < frame_idx)
continue;
if (hmm_bestscore(&rhmm->hmm) BETTER_THAN thresh)
{
hmm_frame(&rhmm->hmm) = nf;
E_DEBUG(3,("Preserving root channel %d score %d\n", i, hmm_bestscore(&rhmm->hmm)));
newphone_score = hmm_out_score(&rhmm->hmm) + ngs->pip;
if (pls != NULL || newphone_score BETTER_THAN newphone_thresh)
{
*/
for (hmm = rhmm->next; hmm; hmm = hmm->alt)
{
int32 pl_newphone_score = newphone_score
+ phone_loop_search_score(pls, hmm->ciphone);
if (pl_newphone_score BETTER_THAN newphone_thresh)
{
//此if语句较为耗时 1%
if ((hmm_frame(&hmm->hmm) < frame_idx)
|| (pl_newphone_score BETTER_THAN hmm_in_score(&hmm->hmm)))
{
hmm_enter(&hmm->hmm, pl_newphone_score,
hmm_out_history(&rhmm->hmm), nf); //0.2%
*(nacl++) = hmm;
}
}
}
}
if (pls != NULL ||...
}
/* 4.acmod_activate_hmm */
//if-else
if (hmm_is_mpx(hmm)){ //4.8%
switch (hmm_n_emit_state(hmm))
{
case 5:
MPX_BITVEC_SET(acmod, hmm, 4);
MPX_BITVEC_SET(acmod, hmm, 3);
case 3:
MPX_BITVEC_SET(acmod, hmm, 2);
MPX_BITVEC_SET(acmod, hmm, 1);
MPX_BITVEC_SET(acmod, hmm, 0);
break;
default:
for (i = 0; i < hmm_n_emit_state(hmm); ++i)
{
MPX_BITVEC_SET(acmod, hmm, i);
}
}
}
else
{
switch (hmm_n_emit_state(hmm))
{
case 5:
NONMPX_BITVEC_SET(acmod, hmm, 4);
NONMPX_BITVEC_SET(acmod, hmm, 3);
case 3:
NONMPX_BITVEC_SET(acmod, hmm, 2); //0.4%
NONMPX_BITVEC_SET(acmod, hmm, 1); //0.5%
NONMPX_BITVEC_SET(acmod, hmm, 0);
break;
default:
for (i = 0; i < hmm_n_emit_state(hmm); ++i)
{
NONMPX_BITVEC_SET(acmod, hmm, i);
}
}
}
/* 5.hmm_vit_eval */
//if-else
if (hmm_is_mpx(hmm)){ //5.3%
if (hmm_n_emit_state(hmm) == 5)
return hmm_vit_eval_5st_lr_mpx(hmm);
else if (hmm_n_emit_state(hmm) == 3)
return hmm_vit_eval_3st_lr_mpx(hmm);
else
return hmm_vit_eval_anytopo(hmm);
}
/* 不耗时 0.1%
else
{
if (hmm_n_emit_state(hmm) == 5)
return hmm_vit_eval_5st_lr(hmm);
else if (hmm_n_emit_state(hmm) == 3)
return hmm_vit_eval_3st_lr(hmm);
else
return hmm_vit_eval_anytopo(hmm);
}
*/
/* 6.find_bg */
//loop1 3.4%
while (e - b > BINARY_SEARCH_THRESH)
{
i = (b + e) >> 1;
if (bg[i].wid < w) //2.1%
b = i + 1;
else if (bg[i].wid > w)
e = i;
else
return i;
}
//loop2 1%
for (i = b; (i < e) && (bg[i].wid != w); i++); //0.9%
return ((i < e) ? i : -1);
/* 7.ngram_model_set_score */
// if-else
if (n_hist > base->n - 1)
n_hist = base->n - 1;
if (set->cur == -1) {
/* 不耗时
score = base->log_zero;
for (i = 0; i < set->n_models; ++i) {
int32 j;
mapwid = set->widmap[wid][i];
for (j = 0; j < n_hist; ++j) {
if (history[j] == NGRAM_INVALID_WID)
set->maphist[j] = NGRAM_INVALID_WID;
else
set->maphist[j] = set->widmap[history[j]][i];
}
score = logmath_add(base->lmath, score,
set->lweights[i] +
ngram_ng_score(set->lms[i],
mapwid, set->maphist, n_hist, n_used));
}
*/
}
else {
int32 j;
mapwid = set->widmap[wid][set->cur]; // 1.3%
for (j = 0; j < n_hist; ++j) {
if (history[j] == NGRAM_INVALID_WID)
set->maphist[j] = NGRAM_INVALID_WID;
else
set->maphist[j] = set->widmap[history[j]][set->cur];
}
score = ngram_ng_score(set->lms[set->cur],
mapwid, set->maphist, n_hist, n_used);
}
7.4 热点区域功能分析
8. Srr
Super-resolution Reconstruction (超分辨率重建),在一系列低分辨率图像中编码的信息的微小变化可用于恢复高分辨率图像。
8.1 性能剖视结果
本Benchmark库rbm剖视结果

8.2 热点函数分析
/* 1.Matmul */
void MatMul (double** mat1, double mat2[], double result[])
{
int i,j;
for (i = 0; i< (l*l); i++)
{
for (j = 0; j <(l*l); j++)
{
result[i] += mat1[i][j] * mat2[j];
}
}
}
/* 2.GaussSeidel */
void GaussSeidel(double** A1,double* X,double* Y)
{
//double temp[(l*l)];
//int flag = 0;
int i,j;
double A[(l*l)][(l*l)];
for(i = 0;i<(l*l);i++)
{
for(j = 0;j<(l*l);j++)
{
A[i][j] = A1[i][j];
}
}
for(i = 0;i<(l*l);i++)
{
Y[i] = Y[i]/A[i][i];
for(j = 0;j<(l*l);j++)
if(i!=j)
A[i][j] = (double)A[i][j]/(double)A[i][i];
}
int cnt = 0;
while(cnt < 1)
{
cnt++;
/*for(i = 0;i<(l*l);i++)
temp[i] = X[i];*/
for(i = 0;i<(l*l);i++)
{
X[i] = Y[i];
for(j = 0;j<(l*l);j++)
if(j!=i)
X[i] = X[i]-A[i][j]*X[j];
}
}
}
/* 3.get_g */
void get_g(int rn,int pn)
{
int i;
if(rn<0 || pn<0 || rn>=y_dim ||pn>=x_dim)
{
for(i = 0; i<(l*l); i++)
g[i] = 0;
}
else
{
for (i = 0; i < l*l; i++)
{
int temp_pn = 0;
int temp_rn = 0;
//if(abs(mv[i].x) > (double)1.0) pn -= floor(mv[i].x);
if (mv[i].x >(double)1.0) temp_pn = pn - floor(mv[i].x);
else if (mv[i].x <(double)-1.0) temp_pn = pn + abs(floor(mv[i].x)) - 1;
else temp_pn = pn;
//if(abs(mv[i].y) > (double)1.0) rn -= floor(mv[i].y);
if (mv[i].y >(double)1.0) temp_rn = rn - floor(mv[i].x);
else if (mv[i].y < (double)-1.0) temp_rn = rn + abs(floor(mv[i].x)) - 1;
else temp_rn = rn;
//if (rn < 0 || pn < 0 || rn >= n / l || pn >= n / l) g[i] = 0;
if (temp_rn < 0) temp_rn = 0;
if (temp_pn < 0) temp_pn = 0;
if (temp_rn >= y_dim) temp_rn = y_dim - 1;
if (temp_pn >= x_dim) temp_pn = x_dim - 1;
g[i] = LR[i][temp_rn][temp_pn];
}
}
}
/* 4.get_b */
void get_b(int rn)
{
int i,j;
double temp1[l*l] = {0},temp2[l*l] = {0};
flush_b();
for (i = 1 ; i <= x_dim ; i++)
{
get_g(rn-2,i-2);
MatMul(AT11,g,temp1);
get_g(rn-1,i-2);
MatMul(AT10,g,temp2);
MatAdd(temp1,temp2);
flush_arr(temp2);
get_g(rn,i-2);
MatMul(AT1bar1,g,temp2);
MatAdd(temp1,temp2);
flush_arr(temp2);
get_g(rn-2,i-1);
MatMul(AT01,g,temp2);
MatAdd(temp1,temp2);
flush_arr(temp2);
get_g(rn-1,i-1);
MatMul(AT00,g,temp2);
MatAdd(temp1,temp2);
flush_arr(temp2);
get_g(rn,i-1);
MatMul(AT0bar1,g,temp2);
MatAdd(temp1,temp2);
flush_arr(temp2);
get_g(rn-2,i);
MatMul(ATbar11,g,temp2);
MatAdd(temp1,temp2);
flush_arr(temp2);
get_g(rn-1,i);
MatMul(ATbar10,g,temp2);
MatAdd(temp1,temp2);
flush_arr(temp2);
get_g(rn,i);
MatMul(ATbar1bar1,g,temp2);
MatAdd(temp1,temp2);
flush_arr(temp2);
for(j = 0;j<(l*l);j++)
gCap[j] = temp1[j];
flush_arr(temp1);
MatMul(Abar11,f[rn+1][i-1],temp1);
MatMul(A01,f[rn+1][i],temp2);
MatAdd(temp1,temp2);
flush_arr(temp2);
MatMul(A11,f[rn+1][i+1],temp2);
MatAdd(temp1,temp2);
MatSub(gCap,temp1,b[i-1]);
flush_arr(temp1);
flush_arr(temp2);
MatMul(Abar1bar1,f[rn-1][i-1],temp1);
MatMul(A0bar1,f[rn-1][i],temp2);
MatAdd(temp1,temp2);
flush_arr(temp2);
MatMul(A1bar1,f[rn-1][i+1],temp2);
MatAdd(temp1,temp2);
//flush_arr(temp2);
MatSub(b[i-1],temp1,b[i-1]);
flush_arr(temp1);
flush_arr(temp2);
}
}
8.3热点循环分析
对耗时函数进行分析,热点循环体如下:
(1)MatMul

(2)GaussSeidel

(3)get_g

(4)get_b

汇总热点函数中热点循环
集合如下:
/* 1.MatMul */
//本函数就一个两层循环 51.1%
void MatMul (double** mat1, double mat2[], double result[])
{ // 1.3%
int i,j;
for (i = 0; i< (l*l); i++)
{
for (j = 0; j <(l*l); j++) //16.8%
{
result[i] += mat1[i][j] * mat2[j]; //32.9%
}
}
}
/* 2.GaussSeidel */
//loop1 两层循环 占比 1.9%
for(i = 0;i<(l*l);i++)
{
for(j = 0;j<(l*l);j++)
{
A[i][j] = A1[i][j];
}
}
//loop2 两层循环 占比 22.3%
for(i = 0;i<(l*l);i++) //0.1%
{
Y[i] = Y[i]/A[i][i]; //1.3%
for(j = 0;j<(l*l);j++)
if(i!=j) //0.1%
A[i][j] = (double)A[i][j]/(double)A[i][i]; //20.8%
}
//loop3 三层循环 占比 5.5%
while(cnt < 1)
{
cnt++;
/*for(i = 0;i<(l*l);i++)
temp[i] = X[i];*/
for(i = 0;i<(l*l);i++)
{
X[i] = Y[i];
for(j = 0;j<(l*l);j++) //0.1%
if(j!=i) //0.3%
X[i] = X[i]-A[i][j]*X[j]; //5.1%
}
}
/* 3.get_g */
//本函数为一层for循环,循环内仅包含if-else语句
if(rn<0 || pn<0 || rn>=y_dim ||pn>=x_dim)
/* {
for(i = 0; i<(l*l); i++)
g[i] = 0;
*/ }
else
{
for (i = 0; i < l*l; i++) //0.5%
{
int temp_pn = 0;
int temp_rn = 0;
//if(abs(mv[i].x) > (double)1.0) pn -= floor(mv[i].x);
if (mv[i].x >(double)1.0) temp_pn = pn - floor(mv[i].x);//0.6%
else if (mv[i].x <(double)-1.0) temp_pn = pn + abs(floor(mv[i].x)) - 1; //0.7%
else temp_pn = pn;
//if(abs(mv[i].y) > (double)1.0) rn -= floor(mv[i].y);
if (mv[i].y >(double)1.0) temp_rn = rn - floor(mv[i].x); //0.7%
else if (mv[i].y < (double)-1.0) temp_rn = rn + abs(floor(mv[i].x)) - 1; //0.5%
else temp_rn = rn;
//if (rn < 0 || pn < 0 || rn >= n / l || pn >= n / l) g[i] = 0;
if (temp_rn < 0) temp_rn = 0; //0.9%
if (temp_pn < 0) temp_pn = 0;
if (temp_rn >= y_dim) temp_rn = y_dim - 1;
if (temp_pn >= x_dim) temp_pn = x_dim - 1;
g[i] = LR[i][temp_rn][temp_pn]; // 3.4%
}
}
/* 4.get_b */
// VTune与Gprof结果有一点出入,百分比来自VTune,供参考
// 本函数耗时片段调用了之前的MatMul函数
for (i = 1 ; i <= x_dim ; i++)
{
for(j = 0;j<(l*l);j++) // 0.1%
gCap[j] = temp1[j];
flush_arr(temp1);
MatMul(Abar11,f[rn+1][i-1],temp1); //0.1%
MatMul(A01,f[rn+1][i],temp2); //0.1%
MatAdd(temp1,temp2);
flush_arr(temp2);
MatMul(A11,f[rn+1][i+1],temp2); //0.1%
MatAdd(temp1,temp2);
MatSub(gCap,temp1,b[i-1]);
flush_arr(temp1);
flush_arr(temp2);
MatMul(Abar1bar1,f[rn-1][i-1],temp1); //0.1%
MatMul(A0bar1,f[rn-1][i],temp2); //0.1%
MatAdd(temp1,temp2);
flush_arr(temp2);
MatMul(A1bar1,f[rn-1][i+1],temp2); //0.1%
MatAdd(temp1,temp2);
//flush_arr(temp2);
MatSub(b[i-1],temp1,b[i-1]);
flush_arr(temp1);
flush_arr(temp2);
}
8.4 热点区域功能分析
9. Svd3
奇异值分解(Singular Value Decomposition),类似于PCA,多用于图像压缩,数据降维。
9.1 性能剖视结果
本Benchmark库rbm剖视结果

9.2 热点函数分析
/* svd */
代码过长,因此仅在下方热点展示热点区域
9.3热点循环分析
对耗时函数进行分析,热点循环体如下:
(1)

(2)

(3)

(4)
(5)

汇总热点函数中热点循环
集合如下:
/* svd */
//loop1 /* Householder reduction to bidiagonal form */
int m = input->height;
int n = input->width;
for (i = 0; i < n; i++)
{
//loop1(1) 三层for循环 占比10.4% 热点片段由两个并列子片段组成
l = i + 1;
rv1[i] = scale * g;
g = s = scale = 0.0;
if (i < m)
{
for (k = i; k < m; k++)
{
scale += fabs((double)a(k, i));
}
if (scale)
{
f = (double)a(i,i);
g = -SIGN(sqrt(s), f);
h = f * g - s;
a(i,i) = (float)(f - g);
if (i != n - 1)
{
for (j = l; j < n; j++)
{
//loop1(1)(1) 4.5%
for (s = 0.0, k = i; k < m; k++) //0.3%
s += ((double)a(k,i) * (double)a(k,j)); //4.2%
f = s / h;
//loop1(1)(2) 4.8%
for (k = i; k < m; k++) //0.5%
a(k,j) += (float)(f * (double)a(k,i)); //4.3%
}
}
...
}
}
//loop1(2) 三层for循环 占比8.4% 热点片段由两个并列子片段组成
if (i < m && i != n - 1)
{
for (k = l; k < n; k++)
scale += fabs((double)a(i,k));
if (scale)
{
for (k = l; k < n; k++)
{
a(i,k) = (float)((double)a(i,k)/scale);
s += ((double)a(i,k) * (double)a(i,k));
}
f = (double)a(i,l);
g = -SIGN(sqrt(s), f);
h = f * g - s;
a(i,l) = (float)(f - g);
for (k = l; k < n; k++)
rv1[k] = (double)a(i,k) / h;
if (i != m - 1)
{
for (j = l; j < m; j++) //0.2%
{
//loop1(2)(1) 4.5%
for (s = 0.0, k = l; k < n; k++) //0.3%
s += ((double)a(j,k) * (double)a(i,k)); //4.2%
//loop1(2)(2) 3.7%
for (k = l; k < n; k++) //0.5%
a(j,k) += (float)(s * rv1[k]); //3.2%
}
}
for (k = l; k < n; k++)
a(i,k) = (float)((double)a(i,k)*scale);
}
}
...
}
//loop2 /* accumulate the right-hand transformation */
//三层for循环 占比11.1% 热点片段由两个并列子片段组成
for (i = n - 1; i >= 0; i--)
{
if (i < n - 1)
{
if (g)
{
...
/* double division to avoid underflow */
for (j = l; j < n; j++)
{
for (s = 0.0, k = l; k < n; k++) //0.2%
s += ((double)a(i,k) * (double)v(k,j)); //4.4%
for (k = l; k < n; k++) //0.8%
v(k,j) += (float)(s * (double)v(k,i)); //5.7%
}
}
...
}
...
}
//loop3 /* accumulate the left-hand transformation */
//三层for循环 占比11% 热点片段由两个并列子片段组成
w(i) = (float)(scale * g);
...
for (i = n - 1; i >= 0; i--)
{
l = i + 1;
g = (double)w(i);
...
if (g)
{
g = 1.0 / g;
if (i != n - 1)
{
for (j = l; j < n; j++)
{
for (s = 0.0, k = l; k < m; k++) // 0.5%
s += ((double)a(k,i) * (double)a(k,j)); //4.4%
f = (s / (double)a(i,i)) * g;
for (k = i; k < m; k++) //0.6%
a(k,j) += (float)(f * (double)a(k,i)); //5.5%
}
}
//for (j = i; j < m; j++)
// a(j,i) = (float)((double)a(j,i)*g);
}
// else
{
// for (j = i; j < m; j++)
// a(j,i) = 0.0;
}
++a(i,i);
}
//loop4 /* diagonalize the bidiagonal form */
//四层for循环 占比54.7% 热点片段由两个并列子片段组成
for (k = n - 1; k >= 0; k--)
{
for (its = 0; its < 30; its++)
{
flag = 1;
...
/* shift from bottom 2 x 2 minor */
x = (double)w(l);
nm = k - 1;
y = (double)w(nm);
g = rv1[nm];
h = rv1[k];
f = ((y - z) * (y + z) + (g - h) * (g + h)) / (2.0 * h * y);
g = PYTHAG(f, 1.0);
f = ((x - z) * (x + z) + h * ((y / (f + SIGN(g, f))) - h)) / x;
/* next QR transformation */
c = s = 1.0;
for (j = l; j <= nm; j++)
{
i = j + 1;
g = rv1[i];
y = (double)w(i);
h = s * g;
g = c * g;
z = PYTHAG(f, h);
rv1[j] = z;
c = f / z;
s = h / z;
f = x * c + g * s;
g = g * c - x * s;
h = y * s;
y = y * c;
//loop4(1) 四层for循环 占比25.3%
for (jj = 0; jj < n; jj++) //0.5%
{
x = (double)v(jj,j); //5.8%
z = (double)v(jj,i); //7.6%
v(jj,j) = (float)(x * c + z * s); //8.4%
v(jj,i) = (float)(z * c - x * s); //3%
}
z = PYTHAG(f, h);
w(j) = (float)z;
if (z)
{
z = 1.0 / z; //0.2%
c = f * z;
s = h * z;
}
f = (c * g) + (s * y);
x = (c * y) - (s * g);
//loop4(2) 四层循环 占比29.2%
for (jj = 0; jj < m; jj++) //0.7%
{
y = (double)a(jj,j); //5.3%
z = (double)a(jj,i); //9.8%
a(jj,j) = (float)(y * c + z * s); //11.2%
a(jj,i) = (float)(z * c - y * s); //2.2%
}
}
// rv1[l] = 0.0;
rv1[k] = f;
// w(k) = (float)x;
}
}
9.4 热点区域功能分析
10. Word2vec
词向量:利用神经网络训练一个模型可以将一个词映射到高维语义空间,在该空间距离相近的词具有相似的意义。
10.1 性能剖视结果
本Benchmark库Word2vec剖视结果

10.2 热点函数分析
函数过长,仅截取热点循环置于下方
10.3热点循环分析
对耗时函数进行分析,热点循环体如下:
(1)

(2)

汇总热点函数中热点循环
集合如下:
/* Thread */
//loop1
while (1)
{
...
word = sen[sentence_position];
if (word == -1) continue;
for (c = 0; c < layer1_size; c++) neu1[c] = 0;
for (c = 0; c < layer1_size; c++) neu1e[c] = 0;
next_random = next_random * (unsigned long long)25214903917 + 11;
b = next_random % window;
//train the cbow architecture
//loop1
if (cbow)
{
// in -> hidden
cw = 0;
//loop1(1) 三层循环 (最外层-最内层)占比2.1%
for (a = b; a < window * 2 + 1 - b; a++) if (a != window){
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
for (c = 0; c < layer1_size; c++)
neu1[c] += syn0[c + last_word * layer1_size]; //2.1%
cw++;
}
//loop1(2)
if (cw)
{
//loop1(2)(1)//占比3.3%
for (c = 0; c < layer1_size; c++)
neu1[c] /= cw; //3.3%
...
//loop1(2)(2)
if (negative > 0) for (d = 0; d < negative + 1; d++)
{
//loop1(2)(2)(1) 占比16.8% 仅包含if-else
if (d == 0)
{
target = word;
label = 1;
}
else
{
next_random = next_random * (unsigned long long)25214903917 + 11;
target = table[(next_random >> 16) % table_size]; //1.4%
if (target == 0)
target = next_random % (vocab_size - 1) + 1; //15%
if (target == word)
continue;
label = 0;
}
//loop1(2)(2)(2) 占比67.9% 包含三个并列的两层子循环
l2 = target * layer1_size;
f = 0;
for (c = 0; c < layer1_size; c++)
f += neu1[c] * syn1neg[c + l2]; //35.8%
if (f > MAX_EXP) g = (label - 1) * alpha;
else if (f < -MAX_EXP) g = (label - 0) * alpha;
else g = (label - expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha; //1%
for (c = 0; c < layer1_size; c++)
neu1e[c] += g * syn1neg[c + l2]; //14.7%
for (c = 0; c < layer1_size; c++)
syn1neg[c + l2] += g * neu1[c]; //16.1%
}
//loop1(2)(3) 三层循环 5.8%
// hidden -> in
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
for (c = 0; c < layer1_size; c++) syn0[c + last_word * layer1_size] += neu1e[c]; //5.6%
}
}
}
else...
}
10.4 热点区域功能分析
11. CNN(过大,运行错误,暂时不列入)
11.1 性能剖视结果
本Benchmark库rbm剖视结果
11.2 热点函数分析
/* 1.median */
/* 2.FullSearch */
11.3热点循环分析
对耗时函数进行分析,热点循环体如下:
(1)activateHiddenUnits
(2)train
(3)activateVisibleUnits
汇总热点函数中热点循环
集合如下:
/* 1.median */
//本函数就一个三层循环
/* 2.FullSearch */
//loop1(1)四层循环 本循环在函数中耗时最高 38.7%(占总算法百分比)
11.4 热点区域功能分析
后续使用
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' | ‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" | “Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash | – is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。1
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图:
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









