






本文总结了了不同场景下的多种网络IO线程/进程模型,并给出了各种模型的优缺点及其性能优化方法,非常适合服务端开发、中间件开发、数据库开发等开发人员借鉴。
1. 线程模型一:单线程网络IO复用模型
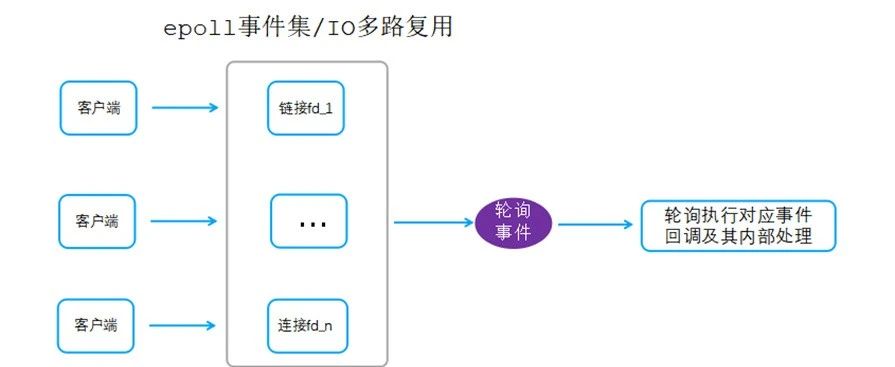
说明:
所有网络IO事件(accept事件、读事件、写事件)注册到epoll事件集;
主循环中通过epoll_wait一次性获取内核态收集到的epoll事件信息,然后轮询执行各个事件对应的回调;
事件注册、epoll_wait事件获取、事件回调执行全部由一个线程处理。
1.1一个完整请求组成
一个完整的请求处理过程主要包含以下几个部分:
步骤1:通过epoll_wait一次性获取网络IO事件;
步骤2:读取数据及协议解析;
步骤3:解析成功后进行业务逻辑处理,然后应答客户端。
1.2 该网络线程模型缺陷
所有工作都由一个线程执行,包括epoll事件获取、事件处理(数据读写)、只要任一一个请求的事件回调处理阻塞,其他请求都会阻塞。例如redis的hash结构,如果filed过多,假设一个hash key包含数百万filed,则该Hash key过期的时候,整个redis阻塞。
单线程工作模型,CPU会成为瓶颈,如果QPS过高,整个CPU负载会达到100%,时延抖动厉害。
1.3 典型案例
redis缓存
推特缓存中间件twemproxy
1.4 主循环工作流程
while (1) { //epoll_wait等待网络事件,如果有网络事件则返回,或者超时范围 size_t numevents= epoll_wait(); //遍历前面epoll获取到的网络事件,执行对应事件回调 for (j = 0; j < numevents; j++) { if(读事件) { //读数据 readData() //解析 parseData() //读事件处理、读到数据后的业务逻辑处理 requestDeal() } else if(写事件) { //写事件处理,写数据逻辑处理 writeEentDeal() } else { //异常事件处理 errorDeal() } } }
说明:后续多线程/进程模型中,每个线程/进程的主流程和该while()流程一致。
1.5 redis源码分析及异步网络IO复用精简版demo
由于之前工作需要,需要对redis内核做二次优化开发,因此对整个redis代码做了部分代码注释,同时把redis的网络模块独立出来做成了简单demo,该demo对理解epoll网络事件处理及Io复用实现会有帮助,代码比较简短,可以参考如下地址:
《redis源码详细注释分析》:https://github.com/y123456yz/Reading-and-comprehense-redis-cluster
《redis网络模块精简版demo》:https://github.com/y123456yz/middleware_development_learning/tree/master/第一阶段-手把手教你做分布式缓存二次开发、性能优化/异步网络框架零基础学习%2B客户端结构组织%2B网络协议解析等/asyn_network%2BclientManager%2BprotocolParse
《推特缓存中间件twemproxy源码分析实现》:https://github.com/y123456yz/Reading-and-comprehense-twemproxy0.4.1
2. 线程模型二:单listener+固定worker线程
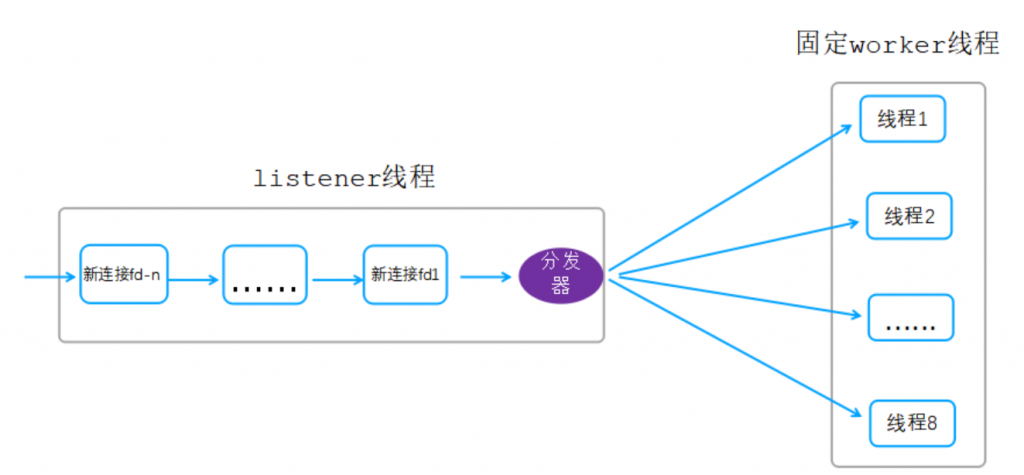
该线程模型图如下图所示:
说明:
listener线程负责接受所有的客户端链接;
listener线程每接收到一个新的客户端链接产生一个新的fd,然后通过分发器发送给对应的工作线程(hash方式);
工作线程获取到对应的新链接fd后,后续该链接上的所有网络IO读写都由该线程处理;
假设有32个链接,则32个链接建立成功后,每个线程平均处理4个链接上的读写、报文处理、业务逻辑处理。
2.1 该网络线程模型缺陷
进行accept处理的listener线程只有一个,在瞬间高并发场景容易成为瓶颈;
一个线程通过IO复用方式处理多个链接fd的数据读写、报文解析及后续业务逻辑处理,这个过程会有严重的排队现象,例如某个链接的报文接收解析完毕后的内部处理时间过长,则其他链接的请求就会阻塞排队。
2.2 典型案例
memcache缓存,适用于内部处理比较快的缓存场景、代理中间场景。
memcache源码实现中文分析可以详见:
https://github.com/y123456yz/Reading-and-comprehense-memcached-1.4.22
3. 线程模型三:固定worker线程模型(reuseport)
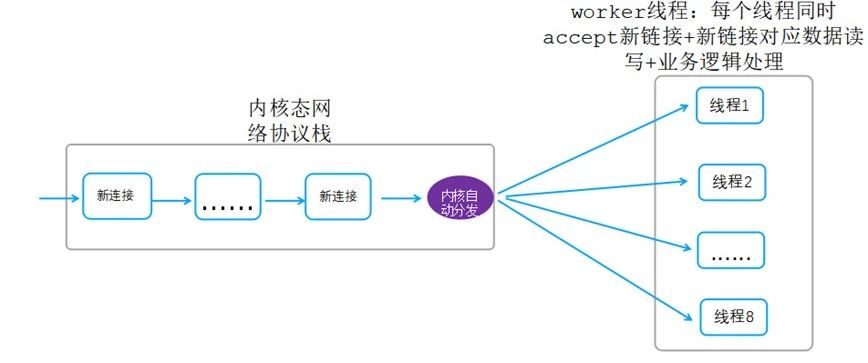
该模型原型图如下:
说明:
Linux kernel 3.9开始支持reuseport功能,内核协议栈每获取到一个新链接自动均衡分发给用户态worker线程。
该模型解决了模型一的listener单点瓶颈问题,多个进程/线程同时做为listener,都可以accept客户端新链接。
3.1 该网络进程/线程模型缺陷
reuseport支持后,内核通过负载均衡的方式分发不同新链接到多个用户态worker进程/线程,每个进程/线程通过IO复用方式处理多个客户端新链接fd的数据读写、报文解析、解析后的业务逻辑处理。每个工作进程/线程同时处理多个链接的请求,如果某个链接的报文接收解析完毕后的内部处理时间过长,则其他链接的请求就会阻塞排队。
该模型虽然解决了listener单点瓶颈问题,但是工作线程内部的排队问题没有解决。
不过,Nginx作为七层转发代理,由于都是内存处理,所以内部处理时间比较短,所以适用于该模型。
3.2典型案例
nginx (nginx用的是进程,模型原理一样),该模型适用于内部业务逻辑简单的场景,如nginx代理等。
reuseport支持性能提升过程可以参考另一篇分享:《Nginx多进程高并发、低时延、高可靠机制在缓存(redis、memcache)twemproxy代理中的应用》(https://my.oschina.net/u/4087916/blog/3016162)
另,参考《nginx源码中文注释分析》(https://github.com/y123456yz/reading-code-of-nginx-1.9.2)
4. 线程模型四:一个链接一个线程模型
该线程模型图如下图:
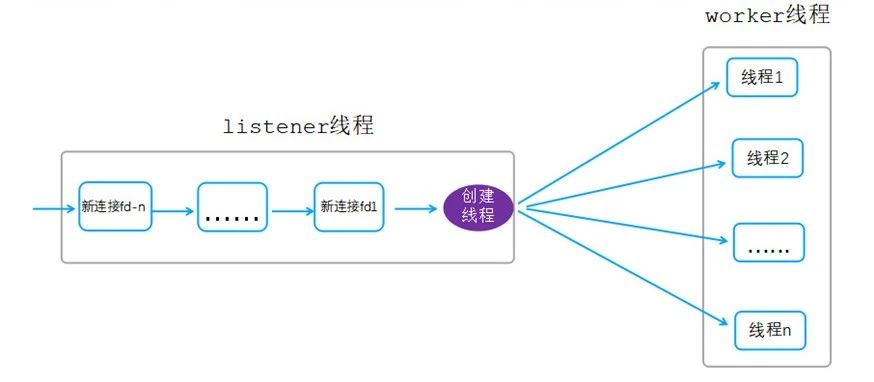
说明:
listener线程负责接受所有的客户端链接。
listener线程每接收到一个新的客户端链接就创建一个线程,该线程只负责处理该链接上的数据读写、报文解析、业务逻辑处理。
4.1 该网络线程模型缺陷
一个链接创建一个线程,如果10万个链接,那么就需要10万个线程,线程数太多,系统负责、内存消耗也会很多;
当链接关闭的时候,线程也需要销毁,频繁的线程创建和消耗进一步增加系统负载。
4.2 典型案例
mysql默认方式、MongoDB同步线程模型配置,适用于请求处理比较耗时的场景,如数据库服务;
Apache web服务器,该模型限制了apache性能,nginx优势会更加明显。
5. 线程模型五:单listener+动态worker线程(单队列)
该线程模型图如下图所示:
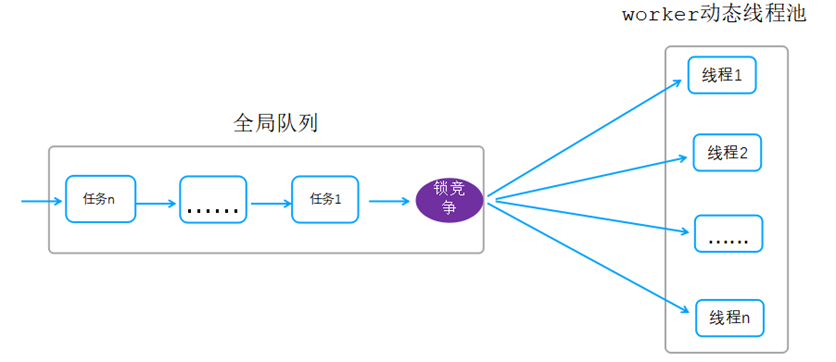
说明:
listener线程接收到一个新链接fd后,把该fd交由线程池处理,后续该链接的所有读写、报文解析、业务处理都由线程池中多个线程处理。
该模型把一次请求转换为多个任务(网络数据读写、报文解析、报文解析后的业务逻辑处理)入队到全局队列,线程池中的线程从队列中获取任务执行。
同一个请求访问被拆分为多个任务,一次请求可能由多个线程处理。
当任务太多,系统压力大的时候,线程池中线程数动态增加。
当任务减少,系统压力减少的时候,线程池中线程数动态减少。
5.1 工作线程运行时间相关的几个统计
T1: 调用底层asio库接收一个完整MongoDB报文的时间
T2: 接收到报文后的后续所有处理(含报文解析、认证、引擎层处理、发送数据给客户端等)
T3: 线程等待数据的时间(例如:长时间没有流量,则现在等待读取数据)
5.2单个工作线程如何判断自己处于”空闲”状态
线程运行总时间=T1 + T2 +T3,其中T3是无用等待时间。如果T3的无用等待时间占比很大,则说明线程比较空闲。工作线程每一次循环处理后判断有效时间占比,如果小于指定阀值,则自己直接exit退出销毁。
5.3 如何判断线程池中工作线程“太忙”
控制线程专门用于判断线程池中工作线程的压力情况,以此来决定是否在线程池中创建新的工作线程来提升性能。
控制线程每过一定时间循环检查线程池中的线程压力状态,实现原理就是简单的实时记录线程池中的线程当前运行情况,为以下两类计数:总线程数_threadsRunning、当前正在运行task任务的线程数_threadsInUse。如果_threadsRunning=_threadsRunning,说明所有工作线程当前都在处理task任务,线程池中线程压力大,这时候控制线程就开始增加线程池中线程数。
5.4 该网络线程模型缺陷
线程池获取任务执行,有锁竞争,这里就会成为系统瓶颈。
5.5 典型案例
MongoDB动态adaptive线程模型,适用于请求处理比较耗时的场景,如数据库服务
该模型详细源码优化分析实现过程同样参考:
6. 线程模型六:单listener+动态worker线程(多队列)-MongoDB网络线程模型优化实践
该线程模型图如下:
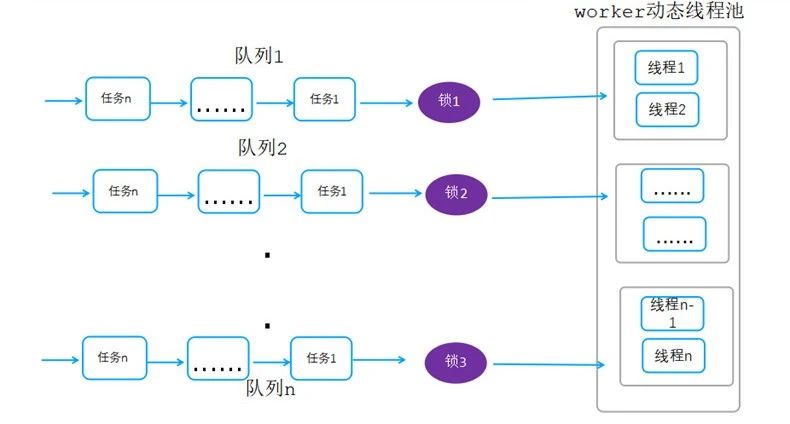
说明:
把一个全局队列拆分为多个队列,任务入队的时候按照hash散列到各自的队列,工作线程获取获取任务的时候,同理通过hash的方式去对应的队列获取任务,通过这种方式减少锁竞争,同时提升整体性能。
6.1典型案例
OPPO自研MongoDB内核多队列adaptive线程模型优化,性能有很好的提升,适用于请求处理比较耗时的场景,如数据库服务。该模型详细源码优化分析实现过程再次参考:《MongoDB网络传输处理源码实现及性能调优——体验内核性能极致设计》
6.2 疑问?为什么MySQL、MongoDB等数据库没有利用内核的reuseport特殊-多线程同时处理accept请求?
答:实际上所有服务都可以利用这一特性,包括数据库服务(MongoDB、mysql等)。但是因为数据库服务访问时延一般都是ms级别,如果reuseport特性利用起来,时延会有几十us的性能提升,这相比数据库内部处理的ms级时延,这几十us的性能提升,基本上可以忽略掉,这也是大部分数据库服务没有支持该功能的原因。
缓存,代理等中间件,由于本身内部处理时间就比较小,也是us级别,所以需要充分利用该特性。
杨亚洲
前滴滴出行技术专家,现任OPPO数据库团队负责人,一直专注于分布式缓存、高性能服务器、数据库、中间件等相关研发。Github账号地址:














 7862
7862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









