





这篇文章分享给做AI搜索的朋友们。少走一些重复的路把。希望这些结果能够帮到大家。
这里再分享一些心得。其实我们也在想,为什么现在已经有的AI搜素,他们的联网查询为何这么快?为什么这么稳定?像国内AI搜索做的比较好的,kimi,秘塔,360ai搜索。其中秘塔是被猎豹控股的(猎豹本身就是做搜索引擎的),360浏览器本身也是做搜索引擎的。他们的联网搜索并不是走的爬取网页的方式。前段时间分析过kimi的联网查询,大概率是bing的接口。不过现在就不一定了。
搜索引擎的搜索通常只有快照信息。也就是不包括网页的完整的正文内容。大概爬取一次搜索引擎就需要1s(在过防爬的前提下),然后根据返回的原网页的链接,再获取网页的正文,至少需要5s,如果是动态加载的网页,安全认证的网页,所需的时间就更长了。平均一次获取网页的详情在10s左右。这和jina的 reader是一致的。
这篇文章给大家分享我了解到的搜索引擎的API供应商和获取详情页的供应商。
需求: 一个快速的(5s内获取正文并返回)、稳定的(能够跳过验证,跳过防爬,能够解析动态加载的网页)、支持高并发的、能够获取到内容详情页的联网查询接口。
快报:只有jina reader能够满足以上的需求(但是jina reader的解析能力不够,有些权限验证它无法通过)。

参考文章:
2023年15个最佳搜索引擎结果页面 API | 代理 • Proxy
一、测试结论
1.1 搜索过程分两步
第一步根据query从搜索引擎上获取搜索快照,第二步根据返回的url获取网页的内容。
除了crawlbase 以外,其余的搜索引擎API返回的结果都只包含搜索快照。
crawlbase 获取页面详情页的接口,需要额外调用。价格为149美元每月,总计100W个请求。每秒可支持的获取详情页的并发为30,换算成Ai搜索为3个请求(每个请求,获取10个快照页)。可以解析需要动态加载的网页,耗时在 4s- 10s。
1.2 对比jina reader
jina reader 提供了联网查询并返回页面top5数据的接口。能够支持的访问速率,40/每分钟 (提供了升级的支持,需要提交公司信息,没有提到升级的价格),平均响应时间10s。收费标准:按照输出的token计算。10亿/ 20美元

二、搜索引擎
用户获取搜索快照
2.1 brightdata
登录方式
github 或者 google 账号,需要邮箱验证
5美元试用
SERP API - SERP scraper API - Free Trial
试用体验地址
Bright Data - Web Data Platform
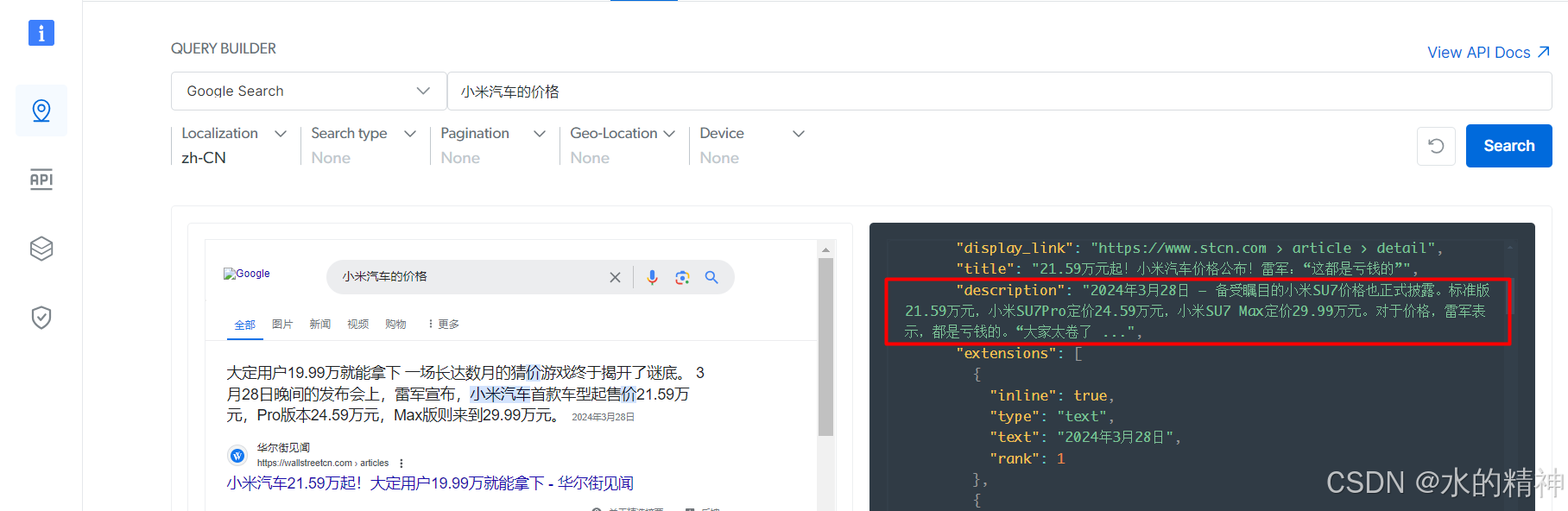
问题点:
给的示例代码无法获取到数据。
在体验页面上获取的数据,只有快照,没有正文内容。
得到脚本和python代码,执行都报错,请求被终止。
urllib.error.URLError: <urlopen error [WinError 10054] 远程主机强迫关闭了一个现有的连接。
2.2 serpApi
免注册,可以体验: SerpApi: Google Search API
没有全文,只有快照。
2.3 crawlbase
149美元/月 100W个请求
30并发
可以解析需要动态加载的网页(官方描述)
4s- 10s
Scraper API - 自动抓取和爬取 | 爬虫库
可以通过传入完整的url,获取到全文的内容。
2.4 scale SERP
Scale SERP - Free, Real-Time Google Search API
文档上看到有全文的json和html,但是该内容只是快照页的,不是详情页的内容。

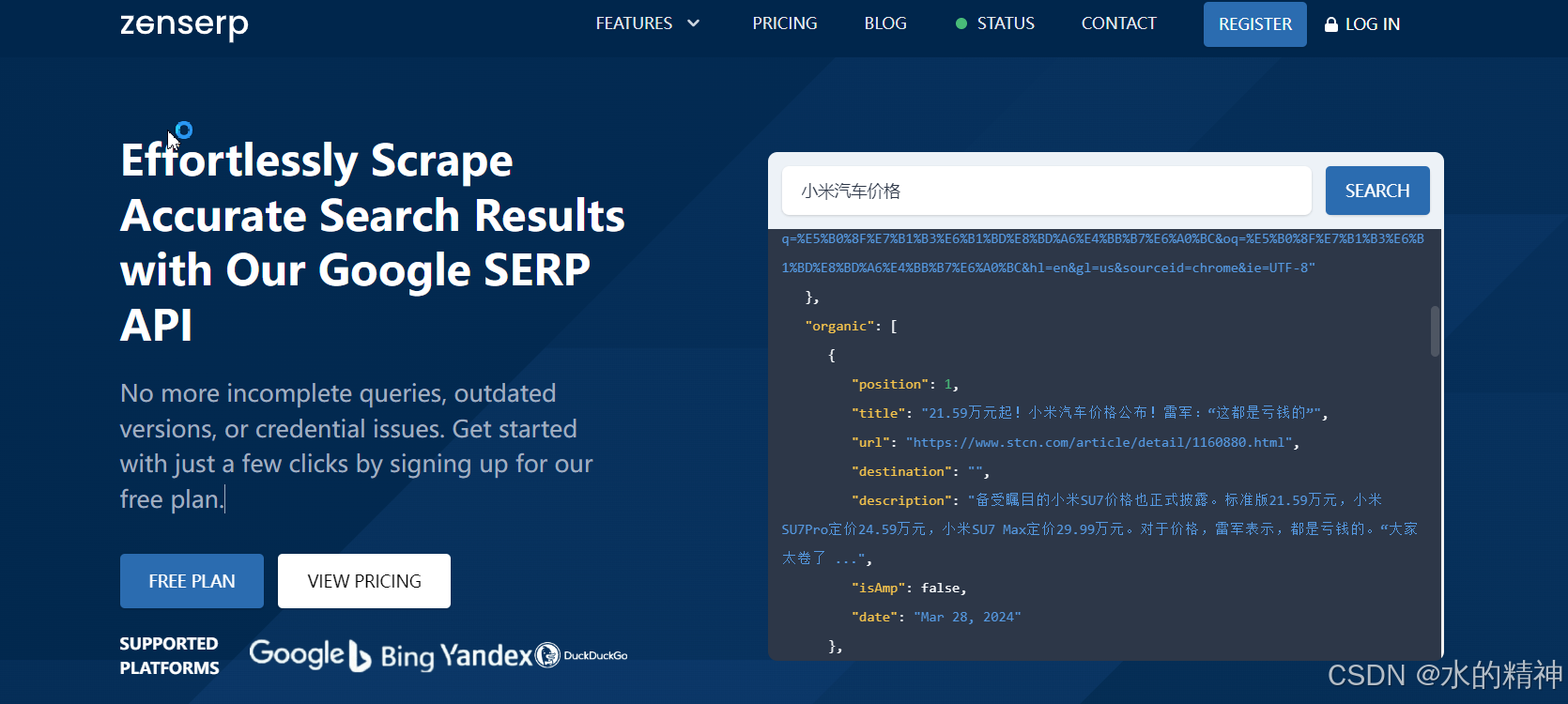
2.5 scraperapi
可以直接体验,免注册
只有快照如下:
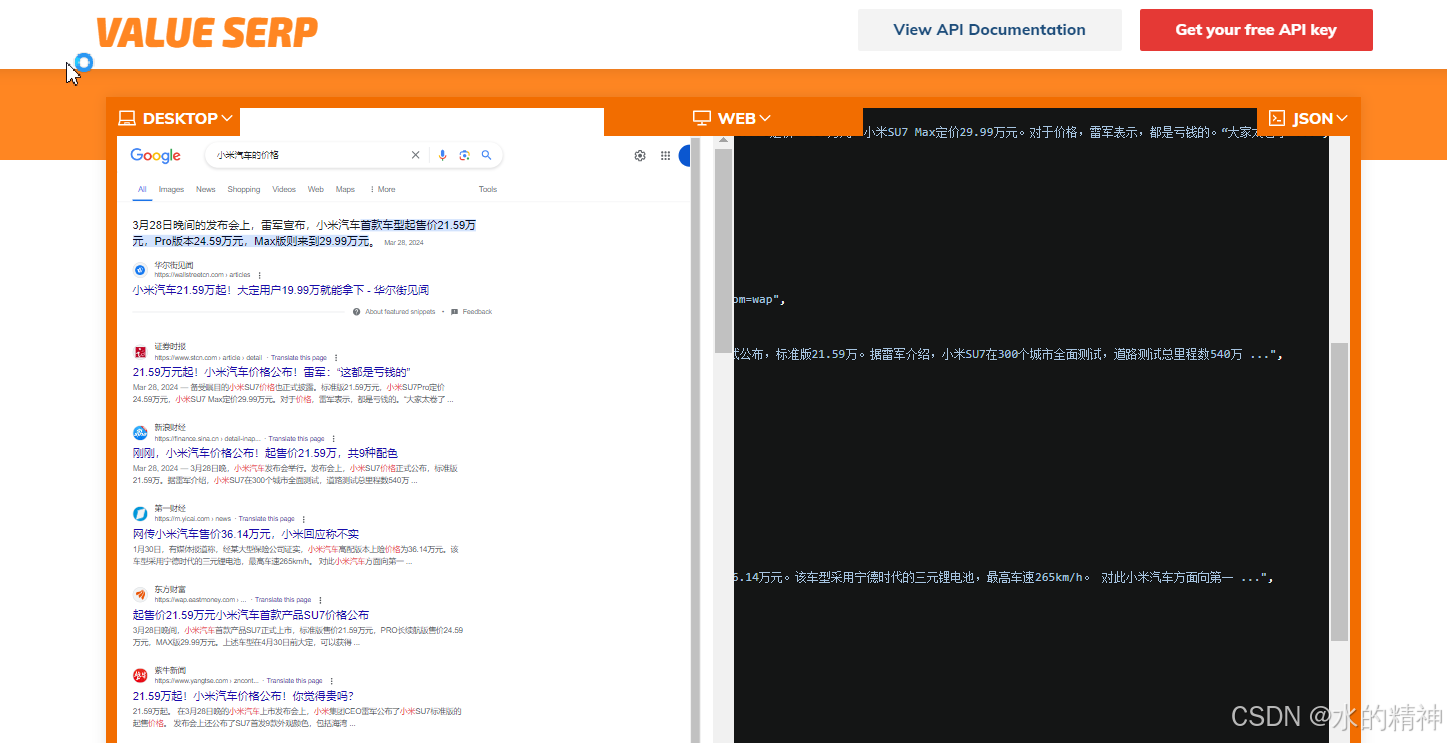
2.6 valueserp
在线体验地址
VALUE SERP - The World’s Best Value SERP API
只有快照
2.7 serpsbot
只有快照数据
2.8 scrapingbee
只有快照数据,文档中有提到full html,还未测试,应该是快照页的html
Google search API | ScrapingBee
2.9 google search api
只有快照
Google Search API for real-time SERP scraping
三、官方API
3.1 google 官方API
每天免费提供100次API调用,之后每1000次为5美元,最多可达每天1万次。这里也只是快照。
四、根据URL获取解析后的正文
4.1 穿云
穿云API:从任意URL提取高质量数据,无需繁琐开发 – 穿云API技术博客
4.2 crawlbase
同2.3
知乎的安全验证没有通过!















 1714
1714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









