






原创作者:爱可生开源社区
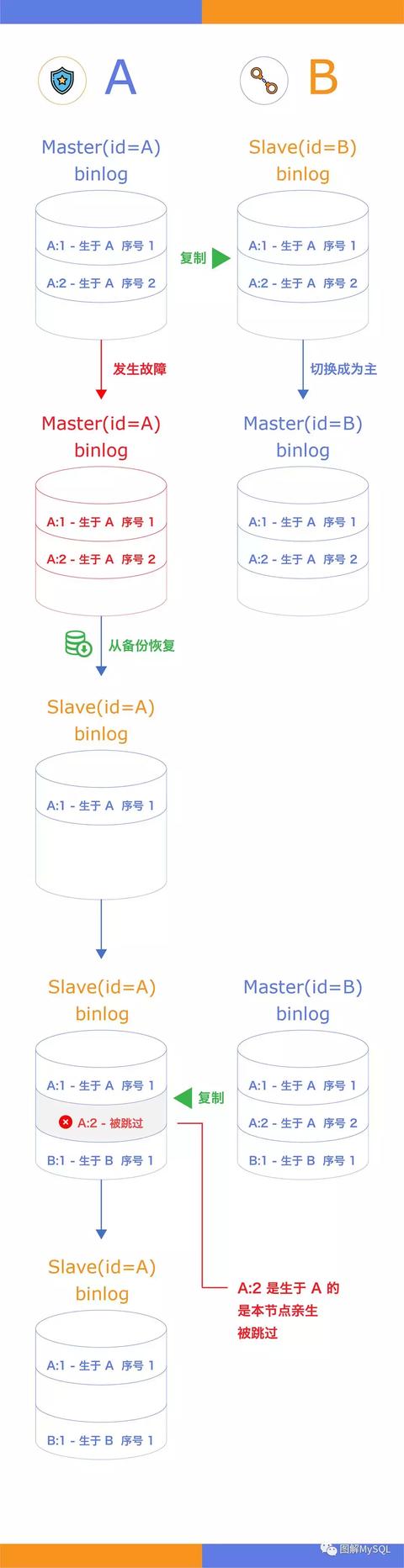
本文我们来看一个场景,两台MySQL实例使用主从复制,当master故障,触发高可用切换,新master上线后,通过备份重建旧master并建立复制后,数据发生丢失。
以下我们通过图解还原一遍当时的场景:
注:图中标注的id指的是MySQL的server_id
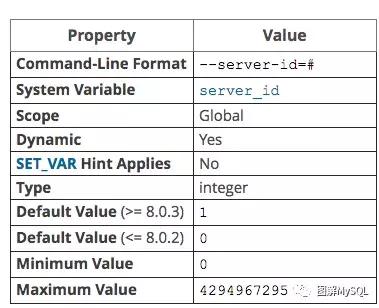
server_id配置:
- 默认值1或0
- 需要配置时通过参数server-id指定
背景:
- 当配置MySQL复制时,server_id是必填项,用来区分复制拓扑中的各个实例,例如在循环的级联复制中(A=>B=>C=>A),避免重复数据不必要的复制(C=>A数据重复,不必要)
- 当slave的io线程发现binlog中的server_id与自身一样时,默认不会将该binlog写入自身的relay log中,即跳过了该数据的复制,同时也能减少写relay log对磁盘的压力
- 然而这种机制在高可用切换场景下会引入潜在的隐患:
- 隐患一:
- 如上图所示,从备份恢复的旧master仍沿用了原来的server_id A,导致io线程跳过了A:2事务,最终丢失了A:2的数据
- 隐患二:
- 级联复制中,当不相邻实例的server_id相同时,也会出现复制数据丢失
- 上述两种隐患的存在都是因为在复制拓扑中非直接相连的MySQL server_id重复。在普通的一对主从复制中,slave的io线程会检查与自己相连的master的server_id是否与自身重复,若发现重复会停止复制抛出错误
- 注:可通过配置--replicate-same-server-id改变以上默认行为
使用建议:
- 配置MySQL复制时,为每个实例配置不同的server_id
- 通过备份工具还原实例后,为实例配置一个新的server_id
附加题:
除了server_id,MySQL5.6起引入了server_uuid
server_uuid配置:
当MySQL启动时
- 尝试从 data_dir/auto.cnf中读取 uuid
- 如果1尝试失败,则生成一个新的uuid并写入data_dir/auto.cnf
背景:
- 主从复制中,要求master和slave的server_uuid不同,否则在复制初始化时会出现报错
- GTID就是使用了server_uuid做为全局唯一的标识
使用建议:
- 如果直接拷贝master的数据文件来建立slave,注意要删除auto.cnf,重启使MySQL重新生成一个新的server_uuid,否则复制将会异常
本文参考:
https://dev.mysql.com/doc/refman/8.0/en/replication-options-slave.html















 1597
1597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









