









之前我们已经学过了主从复制了,那么如果遇到这种情况该怎么办?
复制架构中出现宕机情况,怎么办?
如果在主从复制架构中出现宕机的情况,需要分情况看:
- 从Redis宕机
- 这个相对而言比较简单,在Redis中从库重新启动后会自动加入到主从架构中,自动完成同步数据;
- 问题? 如果从库在断开期间,主库的变化不大,从库再次启动后,主库依然会将所有的数据做RDB操作吗?还是增量更新?(从库有做持久化的前提下)
- 不会的,因为在Redis2.8版本后就实现了,主从断线后恢复的情况下实现增量复制。
- 主Redis宕机
- 这个相对而言就会复杂一些,需要以下2步才能完成
- 第一步,在从数据库中执行SLAVEOF NO ONE命令,断开主从关系并且提升为主库继续服务;
- 第二步,将主库重新启动后,执行SLAVEOF命令,将其设置为其他库的从库,这时数据就能更新回来;
- 这个手动完成恢复的过程其实是比较麻烦的并且容易出错,有没有好办法解决呢?当前有的,Redis提供的哨兵(sentinel)的功能。
- 这个相对而言就会复杂一些,需要以下2步才能完成
接下来就介绍一下哨兵。
一、 哨兵(sentinel)
顾名思义,哨兵的作用就是对Redis的系统的运行情况的监控,它是一个独立进程。它的功能有2个:
- 监控主数据库和从数据库是否运行正常;
- 主数据出现故障后自动将从数据库转化为主数据库;
1.1 原理
单个哨兵的架构:

多个哨兵的架构:

多个哨兵,不仅同时监控主从数据库,而且哨兵之间互为监控。
1.2 环境
当前处于一主多从的环境中: 输入info replication 查看主从配置关系
192.168.19.26:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.19.26,port=6380,state=online,offset=4088,lag=0
slave1:ip=192.168.19.26,port=6381,state=online,offset=4088,lag=1
1.3 配置哨兵
启动哨兵进程首先需要创建哨兵配置文件:
vi sentinel.conf(自己创建的)
输入内容:
sentinel monitor myMaster 192.168.19.26 6379 1
说明:
myMaster:监控主数据的名称,自定义即可。
192.168.19.26:监控的主数据库的IP
6379:监控的主数据库的端口
1:最低通过票数
启动哨兵进程:
redis-sentinel ./sentinel.conf
哨兵无需配置slave,只需要指定master,哨兵会自动发现slave
二、从数据库宕机
kill掉从redis进程后,30秒后哨兵的控制台输出:
2989:X 05 Jun 20:09:33.509 # +sdown slave 192.168.19.26:6380 192.168.19.26 6380 @ myMaster 192.168.19.26 6379
说明已经监控到slave宕机了,那么,如果我们将6380端口的redis实例启动后,会自动加入到主从复制吗?
2989:X 05 Jun 20:13:22.716 * +reboot slave 192.168.19.26:6380 192.168.19.26 6380 @ myMaster 192.168.19.26 6379
2989:X 05 Jun 20:13:22.788 # -sdown slave 192.168.19.26:6380 192.168.19.26 6380 @ myMaster 192.168.19.26 6379
可以看出,slave从新加入到了主从复制中。-sdown:说明是恢复服务。
三、 主库宕机
哨兵控制台打印出如下信息:
2989:X 05 Jun 20:16:50.300 # +sdown master ttMaster 127.0.0.1 6379 说明master服务已经宕机
2989:X 05 Jun 20:16:50.300 # +odown master ttMaster 127.0.0.1 6379 #quorum 1/1
2989:X 05 Jun 20:16:50.300 # +new-epoch 1
2989:X 05 Jun 20:16:50.300 # +try-failover master ttMaster 127.0.0.1 6379 开始恢复故障
2989:X 05 Jun 20:16:50.304 # +vote-for-leader 9059917216012421e8e89a4aa02f15b75346d2b7 1 投票选举哨兵leader,现在就一个哨兵所以leader就自己
2989:X 05 Jun 20:16:50.304 # +elected-leader master myMaster 127.0.0.1 6379 选中leader
2989:X 05 Jun 20:16:50.304 # +failover-state-select-slave master myMaster 127.0.0.1 6379 选中其中的一个slave当做master
2989:X 05 Jun 20:16:50.357 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myMaster 127.0.0.1 6379 选中6381
2989:X 05 Jun 20:16:50.357 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ myMaster 127.0.0.1 6379 发送slaveof no one命令
2989:X 05 Jun 20:16:50.420 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ myMaster 127.0.0.1 6379 等待升级master
2989:X 05 Jun 20:16:50.515 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myMaster 127.0.0.1 6379 升级6381为master
2989:X 05 Jun 20:16:50.515 # +failover-state-reconf-slaves master ttMaster 127.0.0.1 6379
2989:X 05 Jun 20:16:50.566 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ myMaster 127.0.0.1 6379
2989:X 05 Jun 20:16:51.333 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ myMaster 127.0.0.1 6379
2989:X 05 Jun 20:16:52.382 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ myMaster 127.0.0.1 6379
2989:X 05 Jun 20:16:52.438 # +failover-end master ttMaster 127.0.0.1 6379 故障恢复完成
2989:X 05 Jun 20:16:52.438 # +switch-master ttMaster 127.0.0.1 6379 127.0.0.1 6381 主数据库从6379转变为6381
2989:X 05 Jun 20:16:52.438 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myMaster 127.0.0.1 6381 添加6380为6381的从库
2989:X 05 Jun 20:16:52.438 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ ttMaster 127.0.0.1 6381 添加6379为6381的从库
2989:X 05 Jun 20:17:22.463 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ ttMaster 127.0.0.1 6381 发现6379已经宕机,等待6379的恢复

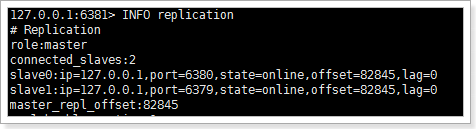
可以看出,目前,6381为master,拥有一个slave为6380.
接下来,我们恢复6379查看状态:
2989:X 05 Jun 20:35:32.172 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ myMaster 127.0.0.1 6381 6379已经恢复服务
2989:X 05 Jun 20:35:42.137 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ myMaster 127.0.0.1 6381 将6379设置为6381的slave















 89
89











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









