






常常我们在抓取分析网页时会发现源码和在浏览器中看到的网页不一样,甚至通过requests抓取到的寥寥几十行代码在浏览器中所看到的却是绚丽多彩的网页。是不是网页偏爱浏览器,通过浏览器访问会给他更多数据…..当然不是!这是JavaScript渲染的结果。而有一种技术叫Ajax,即异步加载的JavaScript和XML,比如我们今天要爬取的微博,他就是使用了这样的技术。
就像这样的网页,就是典型的Ajax加载网页。通过Ajax技术不但可以保证页面在不被刷新、链接不改变的情况下交换数据,还可以在Web开发上减小前后端的分离,大大降低了服务器直接渲染页面带来的压力。因此,就Web发展大趋势来看,这种Ajax页面必将越来越多。 下面,就让我们来分析分析这种网页的加载方式和爬取方法。
0x00 查看请求
分析这种网页的加载,还需要浏览器的开发者工具。这里我以火狐浏览器为例进行介绍,其他浏览器也都大同小异。 我们先随便打开一个微博链接。注意,我们打开的必须要是手机版,电脑版页面不一样。即”https://m.weibo.cn/u/xxxxxxxxx"这种形式的。
 我们按下F12打开开发者工具,切换到Network选项卡,我们便可看到全部的请求。
我们按下F12打开开发者工具,切换到Network选项卡,我们便可看到全部的请求。
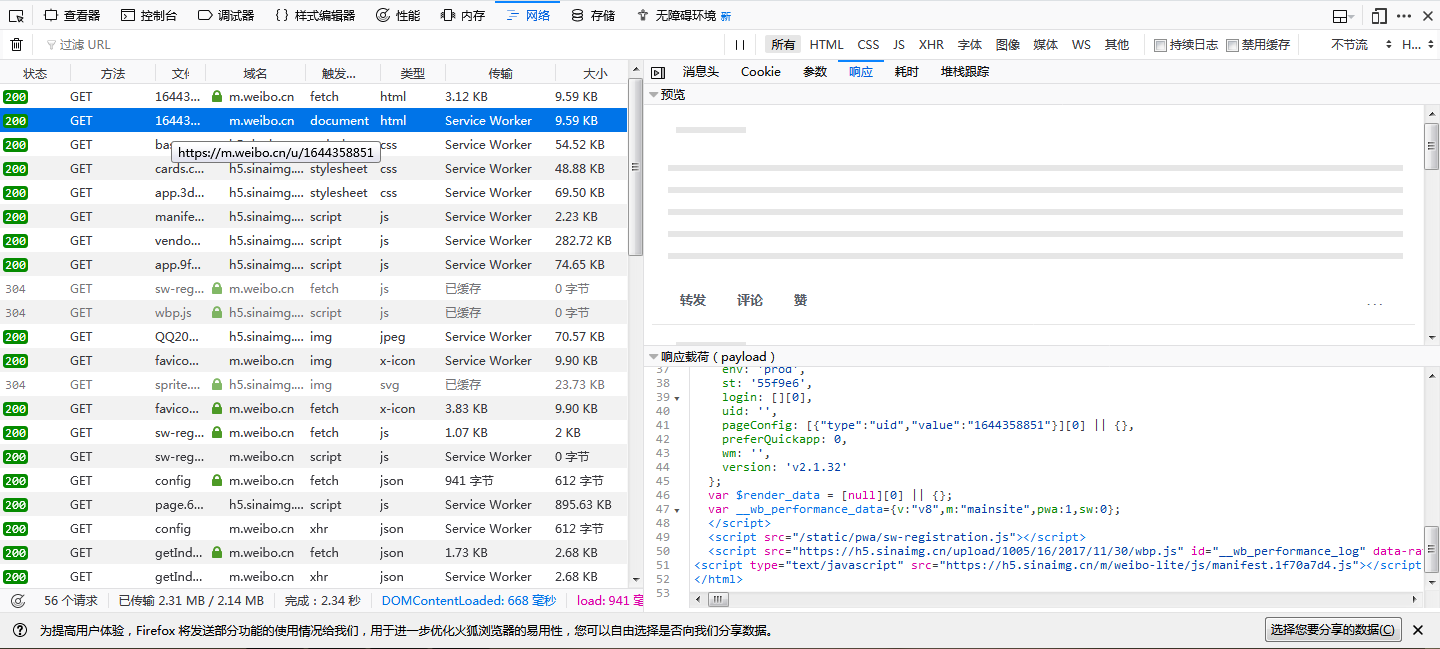
我们可以看到这个页面第一个请求,右边即Response,我们可以看到,其代码只有短短行,结构也非常简单,就是执行了一些JS脚本,意味着我们如果用常规的方法去爬取,只能得到这50行对我们来说毫无意义的代码。我们需要往下拉,寻找到我们所需的请求。 Ajax有特殊的请求类型,叫xhr。开发者选项栏对类型有归类,我们可以快速的找到这个请求。
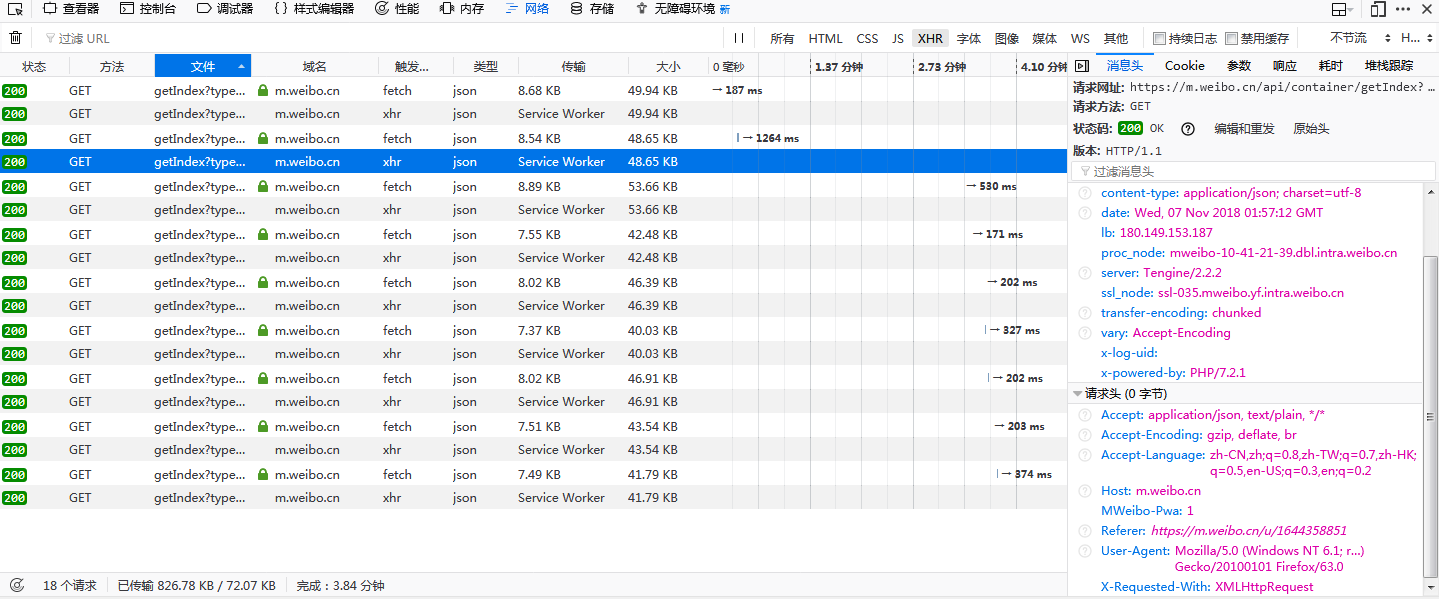 Nice!我们很快找到了这个以getIndex开头的请求。在右边不仅能看到网页与服务器交换数据的Request Headers、URL、Response等信息,还可以看到一个很重要的标志。
Nice!我们很快找到了这个以getIndex开头的请求。在右边不仅能看到网页与服务器交换数据的Request Headers、URL、Response等信息,还可以看到一个很重要的标志。

X-Requested-With:HttpRequest,这就标记了次请求是Ajax的。
我们再往下拉网页,

可以看到Ajax请求不断被发出,新的微博内容不断被加载出来。有了这些请求,我们就可以正式对网页”下刀”了。
0x01 分析请求
打开一个Ajax请求,可以发现,这是一个GET类型的请求,它有4个参数:type、value、containerid_和_page 多观察几个Ajax请求就可以发现,他们的tyep、value和containerid是始终不变的,改变的值只有page,而且是累加上升的,明显就是控制分页的,得到了这个关键信息,我们才能控制爬虫往哪里爬,怎么爬。
0x02 分析响应
接下来我们需要来分析响应内容,这样我们才能处理爬取得到的这些数据。 我们点击Preview选项卡,或者直接通过浏览器访问Ajax请求的链接,可以发现响应是JSON格式的数据。这里Firefox为我们解析了JSON数据,方便查看分析。
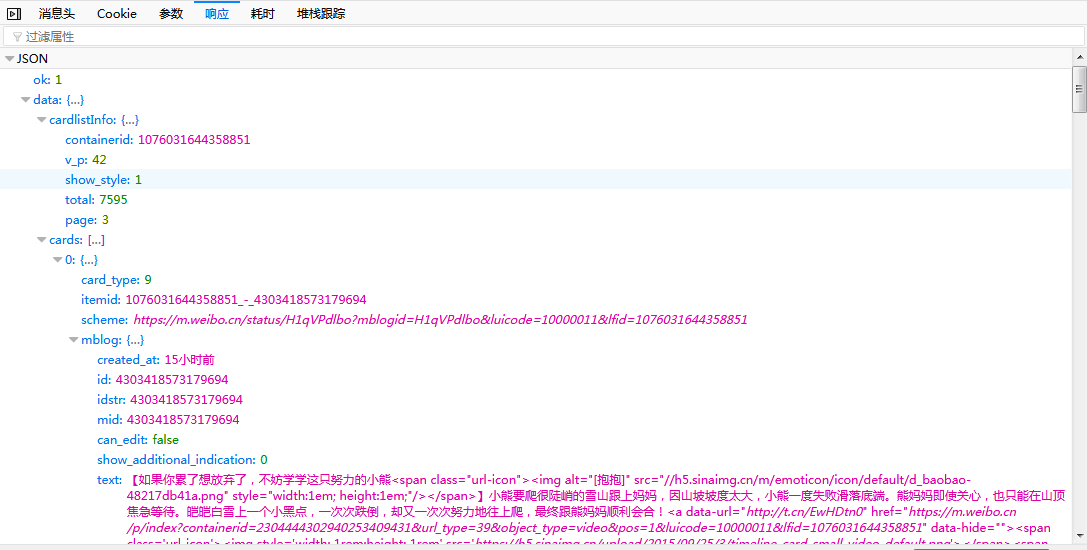
观察可以发现,这个JSON数据中,不但返回了昵称、简介、头像等个人信息,还包含请求得到的新的微博内容。JavaScript收到这些,再执行相应的渲染方法,就可渲染加载出整个页面了。 到此为止,我们已经分析出了Ajax请求的详细信息。接下来仅需构造爬虫迭代的访问Ajax请求地址即可不断的获得我们所需的数据。
0x03 爬虫构建
我们先进行初始化操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14import requests,re,sys,os,time
from urllib.parse import urlparse
from urllib.request import urlopen
from bs4 import BeautifulSoup
headers = {
'Host':'m.weibo.cn',
'Referer':'https://m.weibo.cn/u/2830678474',
'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'x-requested-with':'XMLHttpRequest' #Ajax的特殊请求类型
}
base_url = 'https://m.weibo.cn/api/container/getIndex?'
接下来我们需要迭代的访问各个分页,我们可以通过一个for循环和一个函数来构建GET请求的URL,并通过JSON数据中的ok值观察是否爬取完毕。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31def get_page(page):
params = {
'type' : 'uid',
'value' : '2830678474',
'containerid' : '1076032830678474',
'page' : page
}
return params
num = 1
sum = 0
for page in range(9999999999):
html = requests.get(base_url,headers=headers,params=get_page(page))
time.sleep(1)
json = html.json()
if json['ok'] == 0:
break
sum = sum + len(json['data']['cards'])
for card in range(len(json['data']['cards'])+1):
try:
mblog = json['data']['cards'][card]['mblog']
mblog_text = del_tag(mblog['text'])
if mblog_text.strip(' ') == '':
continue #自动跳过不带文字的微博
print('num:{} text:{} \n转发次数:{} 评论次数:{} 获赞数:{}'.format(num,mblog_text,mblo['reposts_count'],mblog['comments_count'],mblog['attitudes_count']))
num = num + 1
except:
continue
print('总微博数:',sum)
这里,我们还构建了一个函数用于处理JSON数据中的Tag。
1
2
3def del_tag(text):
reg = re.compile(']*>')
return reg.sub('', text)
这样,我们就顺利通过分析Ajax并编写了爬虫爬取得到微博。本文的主要内容是带领大家分析Ajax界面,而不是如何爬去更多的数据。因此代码中过滤了正文无内容的微博,至于微博全文查看、图像下载、跟踪转发等功能的实现,那就”登高作赋,是所望于群公”了。 本文到此结束,若有写错还请指正。若是大家对Python的学习有什么心得体会欢迎大家与我进行交流。















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









