






 本文深入浅出地介绍了递归的概念、生活中的递归场景以及递归在数据结构与算法中的应用,如二分查找、汉诺塔问题。同时,文章提醒了读者在编写递归代码时需要注意的堆栈溢出问题,并提供了避免策略。通过实例,如阶乘计算、归并排序、斐波那契数列等,帮助读者更好地理解和掌握递归的运用。
本文深入浅出地介绍了递归的概念、生活中的递归场景以及递归在数据结构与算法中的应用,如二分查找、汉诺塔问题。同时,文章提醒了读者在编写递归代码时需要注意的堆栈溢出问题,并提供了避免策略。通过实例,如阶乘计算、归并排序、斐波那契数列等,帮助读者更好地理解和掌握递归的运用。
头条的编辑器功能少、代码简直没法看,建议去微信公众号阅读,微信公众号:行知老王
递归是一种应用非常广泛的算法(或者编程技巧)。之后我们要讲的很多数据结构和算法的编码实现都要用到递归,比如 DFS 深度优先搜索、前中后序二叉树遍历等等。所以,搞懂递归非常重要,否则,后面复杂一些的数据结构和算法学起来就会比较吃力。
## 基本概念
维基百科的定义:递归(英语:Recursion),又译为递回,在数学与计算机科学中,是指在函数的定义中使用函数自身的方法。递归一词还较常用于描述以自相似方法重复事物的过程。例如,当两面镜子相互之间近似平行时,镜中嵌套的图像是以无限递归的形式出现的。也可以理解为自我复制的过程。
百度百科的定义:程序调用自身的编程技巧称为递归( recursion)。递归作为一种算法在程序设计语言中广泛应用。一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。递归的能力在于用有限的语句来定义对象的无限集合。一般来说,递归需要有边界条件、递归前进段和递归返回段。当边界条件不满足时,递归前进;当边界条件满足时,递归返回。
## 经典生活场景
- 从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!故事是什么呢?“从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!故事是什么呢?‘从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!故事是什么呢?……’”
- “你被绑架了!”,“谁呀?”,“你!”,“咋滴啦?”,“你被绑架了!”,“谁呀?”,“你!”,“咋滴啦?”,“你被绑架了!”,“谁呀?”.......
## 递归满足的条件
- 一个问题的解可以分解为几个子问题的解,子问题就是数据规模更小的问题。
- 这个问题与分解后的子问题,除了数据规模不同,求解思路完全一样。
- 存在终止条件,也就是把问题分解为子问题,再把子问题分解为子子问题,一层一层分解下去,不能存在无限循环,需要有终止条件。上面那俩生活场景的例子其实是没有终止条件的,不算是合规的递归。
## 递归三要素
递归其实是两个过程,去的过程叫递,回来的过程叫归。
由此,递归必须要有三要素:
- 边界条件,也就是终止条件。
- 递归的前进段,也就是递的过程。
- 递归的返回段,也就是回来的过程。
当边界条件不满足时,递归前进,也就是递;当边界条件满足时,递归返回,也就是归。
## 如何编写递归代码
写递归代码最关键的是写出递推公式,找到终止条件。也就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再找出终止条件,最后将递推公式和终止条件翻译成代码。这期间不用想一层层的调用关系,不要去分解递归的每个步骤。
## 警惕堆栈溢出
编写递归代码时,很可能会遇到堆栈溢出的问题,进而导致系统崩溃。
- 为什么递归会导致堆栈溢出呢?
我们先看一下函数调用时内存发生了什么:
- 当一个方法被调用时,它的参数和返回地址被压入一个栈中;
- 这个方法可以通过获取栈顶元素的值来访问它的参数;
- 当这个方法要返回时,它查看栈以获得返回地址,然后这个地址以及方法的所有参数退栈,并且销毁。
因为函数调用时会用栈来保存临时变量,每调用一个函数,都会将临时变量封装为栈帧压入内存栈中,当函数执行完成返回时,才出栈。系统栈或者虚拟机栈空间一般都不大,如果递归求解的数据规模很大,层次很深,一直往栈中压入数据,就会有堆栈溢出的风险,对java语言来说,就会抛出:
java.lang.StackOverflowError异常。
- 如何避免递归时出现堆栈溢出呢?
我们可以通过限制递归的最大深度来解决,比如,递归调用超过一定深度后,就不再继续递归了,直接返回报错信息。当然,这也不是最好的解决方案,毕竟我们事先也不知道当前线程剩余的栈空间是多大,这种对最大深度比较小的递归适用。对于数据规模较大的情况,建议用循环来解决。也就是非递归的方式。因为递归的使用在方法的调用和返回都会有额外的开销,通常情况下,用递归能实现的,用循环都可以实现,而且循环的效率会更高。
# 应用
## 求一个数的阶乘 n!
- 阶乘公式:n! = n*(n-1)*(n-2)*......*1,也就是:n! = n*(n-1)!
- 同时规定:0!=1;1!=1;负数没有阶乘
/** * for循环求阶乘 * 0!=1,1!=1,负数没有阶乘,如果输入负数返回-1 * * @param n * @return */public static int getFactorialByFor(int n) { int temp = 1; if (n >= 0) { for (int i = 1; i <= n; i++) { temp = temp * i; } } else { return -1; } return temp;}/** * 递归求阶乘 * 0!=1,1!=1,负数没有阶乘,如果输入负数返回-1 * * @param n * @return */public static int getFactorialByRecursion(int n) { if (n >= 0) { if (n == 0) { System.out.println(n + "!=1"); return 1; } else { System.out.println(n); int temp = n * getFactorialByRecursion(n - 1); System.out.println(n + "!=" + temp); return temp; } } return -1;}上面求阶乘的终止条件就是n==0。
## 二分查找
之前讲数组的时候,我们说过,二分查找的数组一定是有序的。
在有序数组array[]中,不断将数组的中间值(mid)和被查找的值比较,如果被查找的值等于array[mid],就返回下标mid; 否则,就将查找范围缩小一半。如果被查找的值小于array[mid], 就继续在左半边查找;如果被查找的值大于array[mid], 就继续在右半边查找。直到查找到该值或者查找范围为空时,查找结束。这不就是递归么,终止条件就是找到该值或者查找范围为空。
二分查找的过程如下图所示:
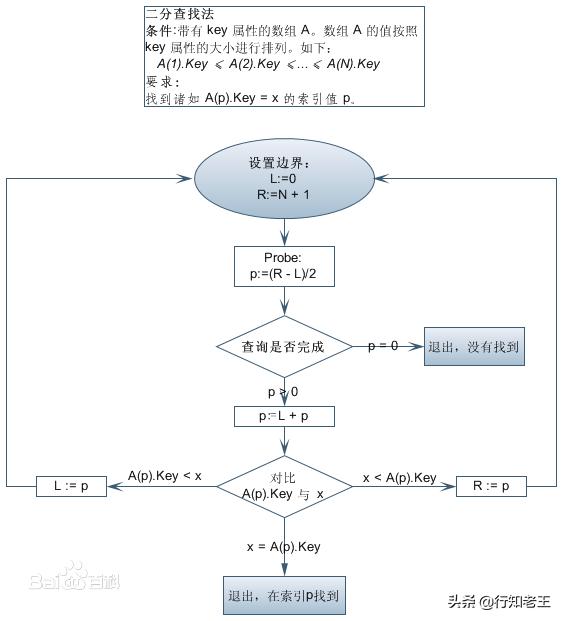
对50的非命中查找如下图所示:

普通循环实现二分查找:
/** * 普通循环实现二分查找,找到目标值返回数组下标,找不到返回-1 * * @param array * @param key * @return int */public static int findTwoPoint(int[] array, int key) { int start = 0; int last = array.length - 1; while (start <= last) { int mid = (last - start) / 2 + start;// 防止直接相加造成int范围溢出 if (key == array[mid]) {// 查找值等于当前值,返回数组下标 return mid; } if (key > array[mid]) {// 查找值比当前值大 start = mid + 1; } if (key < array[mid]) {// 查找值比当前值小 last = mid - 1; } } return -1;}递归实现二分查找:
/** * 递归实现二分查找,边界条件是找到当前值,或者查找范围为空。否则每一次查找都将范围缩小一半。 * * @param array * @param key * @param low * @param high * @return int */public static int search(int[] array, int key, int low, int high) { int mid = (high - low) / 2 + low; if (key == array[mid]) {// 查找值等于当前值,返回数组下标 return mid; } else if (low > high) {// 找不到查找值,返回-1 return -1; } else { if (key < array[mid]) {// 查找值比当前值小 return search(array, key, low, mid - 1); } if (key > array[mid]) {// 查找值比当前值大 return search(array, key, mid + 1, high); } } return -1;}递归的二分查找和非递归的二分查找效率都为O(logN),递归的二分查找更加简洁,便于理解,但是速度会比非递归的慢。
## 汉诺塔问题
汉诺塔问题是由很多放置在三个塔座上的盘子组成的一个古老的难题。如下图所示:
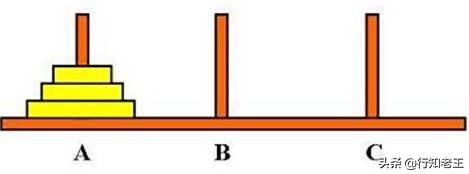
所有盘子的直径是不同的,并且盘子中央都有一个洞使得它们刚好可以放在塔座上。所有的盘子刚开始都放置在A 塔座上。这个难题的目标是将所有的盘子都从塔座A移动到塔座C上,每次只可以移动一个盘子,并且任何一个盘子都不可以放置在比自己小的盘子之上。
试想一下,如果只有两个盘子,盘子从小到大我们以数字命名(也可以想象为直径),两个盘子上面就是盘子1,下面是盘子2,那么我们只需要将盘子1先移动到B塔座上,然后将盘子2移动到C塔座,最后将盘子1移动到C塔座上。即完成2个盘子从A到C的移动。
如果有三个盘子,那么我们将盘子1放到C塔座,盘子2放到B塔座,在将C塔座的盘子1放到B塔座上,然后将A塔座的盘子3放到C塔座上,然后将B塔座的盘子1放到A塔座,将B塔座的盘子2放到C塔座,最后将A塔座的盘子1放到C塔座上。如下图所示:
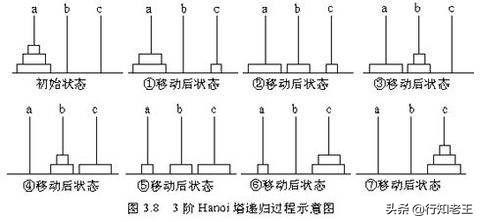
动起来:

如果有四个,五个,N个盘子,那么我们应该怎么去做?这时候递归的思想就很好解决这样的问题了,当只有两个盘子的时候,我们只需要将B塔座作为中介,将盘子1先放到中介塔座B上,然后将盘子2放到目标塔座C上,最后将中介塔座B上的盘子放到目标塔座C上即可。
所以无论有多少个盘子,我们都将其看做只有两个盘子。假设有 N 个盘子在塔座A上,我们将其看为两个盘子,其中(N-1)~1个盘子看成是一个盘子,最下面第N个盘子看成是一个盘子,那么解决办法为:
①、先将A塔座的第(N-1)~1个盘子看成是一个盘子,放到中介塔座B上,然后将第N个盘子放到目标塔座C上。
②、然后A塔座为空,看成是中介塔座,B塔座这时候有N-1个盘子,将第(N-2)~1个盘子看成是一个盘子,放到中介塔座A上,然后将B塔座的第(N-1)号盘子放到目标塔座C上。
③、这时候A塔座上有(N-2)个盘子,B塔座为空,又将B塔座视为中介塔座,重复①,②步骤,直到所有盘子都放到目标塔座C上结束。
简单来说,递归算法为:
1. 从初始塔座A上移动包含n-1个盘子到中介塔座B上。
2. 将初始塔座A上剩余的一个盘子(最大的一个盘子)放到目标塔座C上。
3. 将中介塔座B上n-1个盘子移动到目标塔座C上。
于是我们可以设计一个函数,它的功能是将n个在x柱子上的盘子借助y柱子移到z柱子上:hannoi(n,x,y,z)
于是我们上面的三步可以用程序语言来表达:
1. hannoi(n-1,A,C,B)
2. hannoi(1,A,B,C)
3. hannoi(n-1,B,A,C)
代码实现如下:
/** * 递归实现汉诺塔问题 * * @param dish * 盘子个数(也表示名称) * @param from * 初始塔座 * @param temp * 中介塔座 * @param to * 目标塔座 */public static void hannoi(int dish, String from, String temp, String to) { if (dish == 1) { System.out.println("将盘子" + dish + "从塔座" + from + "移动到目标塔座" + to); } else { hannoi(dish - 1, from, to, temp);// A为初始塔座,B为目标塔座,C为中介塔座 System.out.println("将盘子" + dish + "从塔座" + from + "移动到目标塔座" + to); hannoi(dish - 1, temp, from, to);// B为初始塔座,C为目标塔座,A为中介塔座 }}# 分治算法
当我们求解某些问题时,由于这些问题要处理的数据相当多,或求解过程相当复杂,使得直接求解法在时间上相当长,或者根本无法直接求出。对于这类问题,我们往往先把它分解成几个子问题,找到求出这几个子问题的解法后,再找到合适的方法,把它们组合成求整个问题的解法。如果这些子问题还较大,难以解决,可以再把它们分成几个更小的子问题,以此类推,直至可以直接求出解为止。这就是分治策略的基本思想。
上面讲的递归的二分查找法和下边的归并排序方法就是分治算法的典型例子,分治算法常常是一个方法,在这个方法中含有两个对自身的递归调用,分别对应于问题的两个部分。
二分查找中,将查找范围分成比查找值大的一部分和比查找值小的一部分,每次递归调用只会有一个部分执行,然后一次次缩小查找部分的范围。
## 归并排序
归并算法的中心是合并两个已经有序的数组。合并两个有序数组A和B,就生成了第三个有序数组C,数组C包含数组A和B的所有数据项。
我们先看看如果不用递归,如何合并两个有序数组:
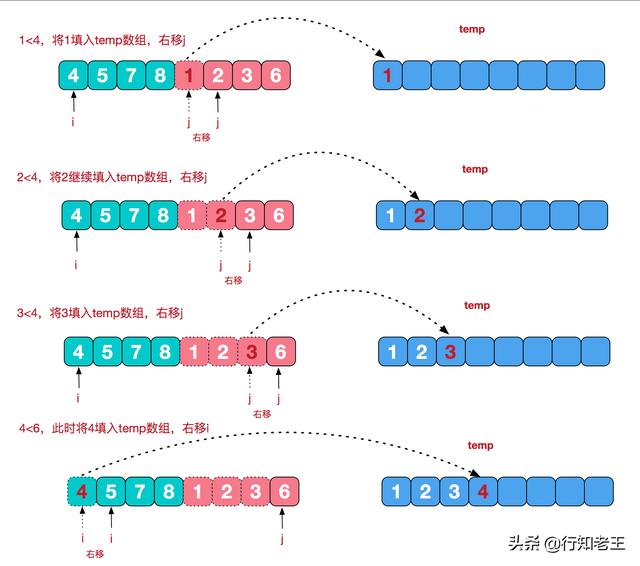
/** * 传入两个有序数组a和b,返回一个排好序的合并数组 * * @param 有序数组 a * @param 有序数组 b * @return */public static int[] sort(int[] a, int[] b) { int[] c = new int[a.length + b.length]; int aNum = 0, bNum = 0, cNum = 0; while (aNum < a.length && bNum < b.length) { if (a[aNum] >= b[bNum]) {// 比较a数组和b数组的元素,谁更小将谁赋值到c数组 c[cNum++] = b[bNum++]; } else { c[cNum++] = a[aNum++]; } } // 如果a数组全部赋值到c数组了,但是b数组还有元素,则将b数组剩余元素按顺序全部复制到c数组 while (aNum == a.length && bNum < b.length) { c[cNum++] = b[bNum++]; } // 如果b数组全部赋值到c数组了,但是a数组还有元素,则将a数组剩余元素按顺序全部复制到c数组 while (bNum == b.length && aNum < a.length) { c[cNum++] = a[aNum++]; } return c;}该方法有三个while循环,第一个while比较数组a和数组b的元素,并将较小的赋值到数组c;第二个while循环当a数组所有元素都已经赋值到c数组之后,而b数组还有元素,那么直接把b数组剩余的元素赋值到c数组;第三个while循环则是b数组所有元素都已经赋值到c数组了,而a数组还有剩余元素,那么直接把a数组剩余的元素全部赋值到c数组。
### 归并排序的思想:
1. 将待排序的线性表不断地切分成若干个子表,直到每个子表只包含一个元素,这时,可以认为只包含一个元素的子表是有序表。
2. 将子表两两合并,每合并一次,就会产生一个新的且更长的有序表,重复这一步骤,直到最后只剩下一个子表,这个子表就是排好序的线性表。
也就是我们把需要排序的数组分成两半,排序每一半,然后将排序好的两半用上面的合并方法进行合并,那分开的两半怎么排序呢,那就把每一半都分为四分之一,对每个四分之一进行排序,然后把它们归并成一个有序的一半。类似的,如何给每个四分之一数组排序呢?把每个四分之一分成八分之一,对每个八分之一进行排序,以此类推,反复的分割数组,直到得到的子数组是一个数据项,那这就是这个递归算法的边界值,也就是假定一个数据项的元素是有序的。
### 归并排序的步骤:
1. 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
2. 设定两个指针,最初位置分别为两个已经排序序列的起始位置;
3. 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
4. 重复步骤 3 直到某一指针达到序列尾;
5. 将另一序列剩下的所有元素直接复制到合并序列尾。
### 实例演示
我们看下如何用归并排序对数组[8,4,5,7,1,3,6,2]进行排序:
1. 将数组拆分成一个个的子数组,可以通过递归拆分,一直拆分到无法再拆分为止,这个步骤叫“分”,如下图所示:
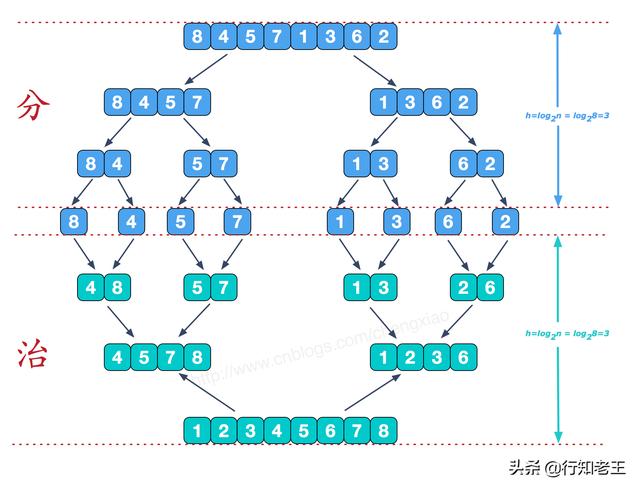
2. 合并相邻有序子序列,这个阶段叫“治”,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],如下图所示:
实现代码如下:
import java.util.Arrays;public class MergeSort { public static void main(String[] args) { int[] arr = {2,7,8,3,1,6,9,0,5,4}; sort(arr); System.out.println(Arrays.toString(arr)); } public static void sort(int[] arr) { int[] temp = new int[arr.length];// 在排序前,先建好一个长度等于原数组长度的临时数组,避免递归中频繁开辟空间 sort(arr, 0, arr.length - 1, temp); } private static void sort(int[] arr, int left, int right, int[] temp) { if (left < right) { int mid = (left + right) / 2; sort(arr, left, mid, temp);// 左边归并排序,使得左子序列有序 sort(arr, mid + 1, right, temp);// 右边归并排序,使得右子序列有序 merge(arr, left, mid, right, temp);// 将两个有序子数组合并操作 } } private static void merge(int[] arr, int left, int mid, int right, int[] temp) { int i = left;// 左序列指针 int j = mid + 1;// 右序列指针 int t = 0;// 临时数组指针 while (i <= mid && j <= right) { if (arr[i] <= arr[j]) { temp[t++] = arr[i++]; } else { temp[t++] = arr[j++]; } } while (i <= mid) {// 将左边剩余元素填充进temp中 temp[t++] = arr[i++]; } while (j <= right) {// 将右序列剩余元素填充进temp中 temp[t++] = arr[j++]; } t = 0; // 将temp中的元素全部拷贝到原数组中 while (left <= right) { arr[left++] = temp[t++]; } }}## 求一个数的乘方
一般稍微复杂一点的计算器上面都能求一个数的乘法,通常计算器上面的标志是 x^y 这样的按键,表示求 x 的 y 次方。一般情况下我们是如何求一个数的乘法的呢?
比如2^8,我们可以会求表达式2*2*2*2*2*2*2*2 的值,但是如果y的值很大,这个会显得表达式很冗长。那么由没有更快一点方法呢?
数学公式如下是成立的:(X^a)^b = X^(a*b)
如果如果求2的8次方,我们可以先假定2^2=a,于是2^8 = (2^2)^4 ,那么就是a^4 ;假定 a^2 = b,那么 a^4 = b^2,而b^2可以写成(b^2)^1。于是现在2的8次方就转换成:b*b。
也就是说我们将乘方的运算转换为乘法的运算。
求xy的值,当y是偶数的时候,最后能转换成两个数相乘,当时当y是奇数的时候,最后我们必须要在返回值后面额外的乘以一个x。
x^y= (x^2)^(y/2),定义a=x^2,b=y/2, 则得到形如:x^y= a^b;
/** * 求x的y次方 * @param x 底数 * @param y 指数 * @return * int */public static int pow(int x, int y) { if (x == 0 || x == 1) { return x; } if (y > 1) { int b = y / 2; int a = x * x; if (y % 2 == 1) {// y为奇数 return pow(a, b) * x; } else {// y为偶数 return pow(a, b); } } else if (y == 0) { return 1; } else {// y==1 return x; }}## 背包问题
背包问题也是计算机中的经典问题。在最简单的形式中,包括试图将不同重量的数据项放到背包中,以使得背包最后达到指定的总重量。
比如:假设想要让背包精确地承重20磅,并且有 5 个可以放入的数据项,它们的重量分别是 11 磅,8 磅,7 磅,6 磅,5 磅。这个问题可能对于人类来说很简单,我们大概就可以计算出 8 磅+ 7 磅 + 5 磅 = 20 磅。但是如果让计算机来解决这个问题,就需要给计算机设定详细的指令了。
算法如下:
1. 如果在这个过程的任何时刻,选择的数据项的总和符合目标重量,那么工作便完成了。
2. 从选择的第一个数据项开始,剩余的数据项的加和必须符合背包的目标重量减去第一个数据项的重量,这是一个新的目标重量。
3. 逐个的试每种剩余数据项组合的可能性,但是注意不要去试所有的组合,因为只要数据项的和大于目标重量的时候,就停止添加数据。
4. 如果没有合适的组合,放弃第一个数据项,并且从第二个数据项开始再重复一遍整个过程。
5. 继续从第三个数据项开始,如此下去直到你已经试验了所有的组合,这时才知道有没有解决方案。
具体实现过程:
public class Knapsack { private int[] weights; // 可供选择的重量 private boolean[] selects; // 记录是否被选择 public Knapsack(int[] weights) { this.weights = weights; selects = new boolean[weights.length]; } /** * 找出符合承重重量的组合 * * @param total * 总重量 * @param index * 可供选择的重量下标 */ public void knapsack(int total, int index) { if (total < 0 || total > 0 && index >= weights.length) { return;// 没找到解决办法,直接返回 } if (total == 0) {// 总重量为0,则找到解决办法了 for (int i = 0; i < index; i++) { if (selects[i] == true) { System.out.println(weights[i] + " "); } } System.out.println(); return; } selects[index] = true; knapsack(total - weights[index], index + 1); selects[index] = false; knapsack(total, index + 1); } public static void main(String[] args) { int array[] = { 11, 9, 7, 6, 5 }; int total = 20; Knapsack k = new Knapsack(array); k.knapsack(total, 0); }}## 找最终推荐人
推荐注册返佣金的这个功能我想你应该不陌生吧?现在很多App都有这个功能。这个功能中,用户A推荐用户B来注册,用户B又推荐了用户C来注册。我们可以说,用户C的“最终推荐人”为用户A,用户B的“最终推荐人”也为用户A,而用户A没有“最终推荐人”。一般来说,我们会通过数据库来记录这种推荐关系。在数据库表中,我们可以记录两行数据,其中actor_id表示用户id,referrer_id, 表示推荐人id。这个结构就是个树形结构,找“最终推荐人”就是通过树叶找到树根。伪代码如下:
long findRootReferrerId(long actorId) { Long referrerId = select referrer_id from [table] where actor_id = actorId; if (referrerId == null) return actorId; return findRootReferrerId(referrerId);}以上的伪代码在递归很深时,有内存溢出的问题,如果有脏数据,比如如果A的推荐人是B,B的推荐人是C,C的推荐人是A,这样就会发生死循环。递归的深度我们可以限制,死循环也可以用递归深度限制,但是我们也可以检测“环”的存在。检测环可以构造一个set集合或者散列表。每次获取到上层推荐人就去散列表里先查,没有查到的话就加入,如果存在则表示存在环了。当然,每一次查询都是一个自己的散列表,不能共用。
## 斐波那契数列
斐波那契数列指的是这样一个数列 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377,610,987,1597,2584,4181,6765,10946,17711,28657,46368……
特别指出:
- 第0项是0,第1项是第一个1。
- 这个数列从第三项开始,每一项都等于前两项之和。
代码如下:
public static long fibonacci(long number) { if ((number == 0) || (number == 1)) return number; else return fibonacci(number - 1) + fibonacci(number - 2);}public static void main(String[] args) { for (int counter = 0; counter <= 10; counter++) { System.out.printf("Fibonacci of %d is: %d

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









