






一.用户定义的变量
适用于测试计划中不需要随迭代发生改变的参数(只取一次值的参数)设置在此处。例如,被测应用的host和port值。
1.添加用户定义的变量
添加-配置元件-用户定义的变量
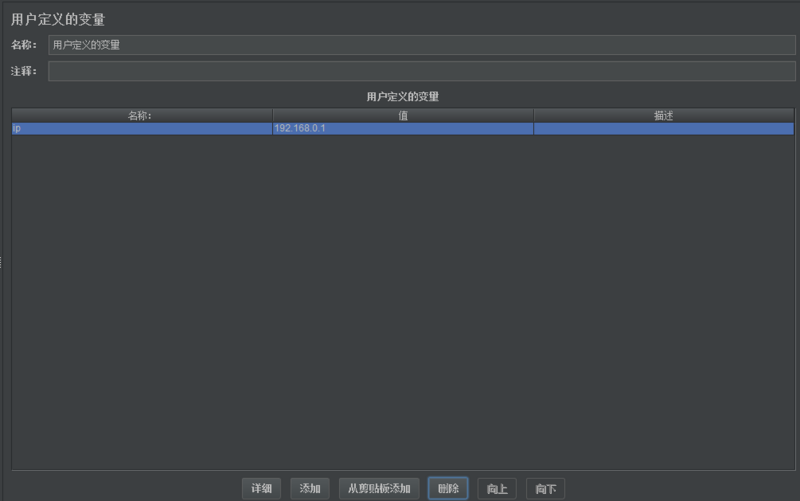
2.配置项
添加变量名称和变量值
3.使用方法
在需要使用参数位置使用${ip}替代
二.用户参数
1.添加用户参数
添加-前置处理器-用户参数
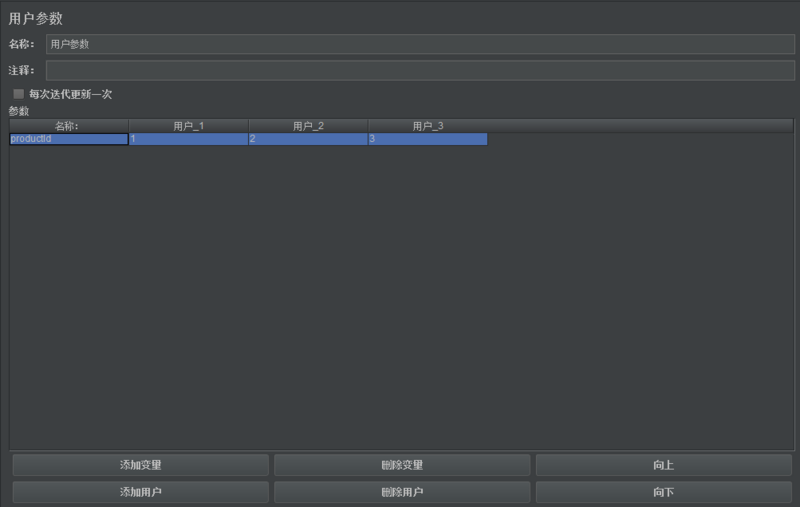
2.配置项
1)定义参数名称和参数值
2)每次迭代更新一次:选中该选项,则参数的值在每个迭代中保持不变,在新的迭代开始时取下一个可用值; 如果取消取中该选项,则参数的值在每个其作用域内的Sampler发出请求时取下一个可用值。
3.使用方法
在需要使用参数位置使用${prductid}替代
三.CSV数据文件设置
1.添加CSV数据文件设置
添加-配置元件-CSV数据文件设置
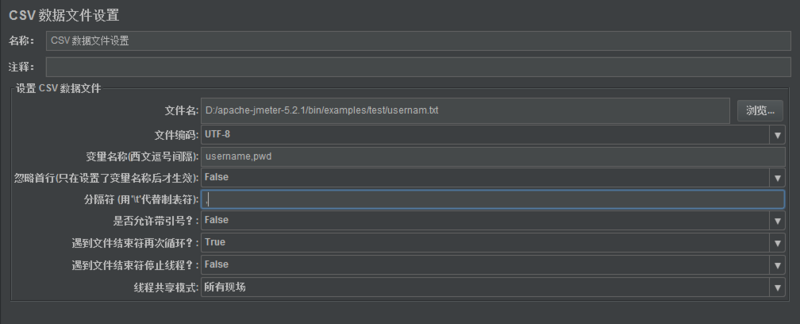
2.配置项
1) 文件名:参数文件路径。
2) 文件编码:视项目接收文件编码,一般是UTF-8,可与开发确认。
3) 变量名称(使用逗号间隔):文件中的每列参数名称,多个使用逗号分隔。
4) 忽略首行(只在设置了变量名称后才生效):如果文件中第一行为参数名称,选择True,如果文件第一行便是参数值,选择False。
5) 分隔符(用’\t’代替制表符):文件中每个参数值之间使用什么间隔,这里就填什么。
6) 是否允许带引号?:如果选择True,csv文件中有引号,则变量引用后也带引号;如果选择False,csv文件中有引号,但是变量实际引用后会自动去掉引号。
7) 遇到文件结束符再次循环?:如果选择True,文件结束后继续从头开始循环取用数据。一般选择True。
8) 遇到文件结束符停止线程?:如果选择False,第一次取文件结束后不停止线程。一般选择False。
线程共享模式:“所有线程”表示作用于全局;“当前线程组”表示只作用于该线程组;“当前线程”表示只作用于该线程。
3.使用方法
在请求体中引用变量,格式:${变量名}
四.函数助手
1.添加函数助手对话框
选项-函数助手对话框

2.配置项
1)选择一个功能:__CSVRead
2)函数参数名称
CSV file to get values from | *alias:参数文件路径
Column number of CSV file | next | *alias:需要获取的数据在文件的第几列,从0开始。
3)点击【生成】按钮,生成函数字符串
3.使用方法
将函数字符串复制后,粘贴到请求体中,例如
${__CSVRead(D:apache-jmeter-5.2.1binexamplesuser&pwd.txt,0)}
4.其余实例
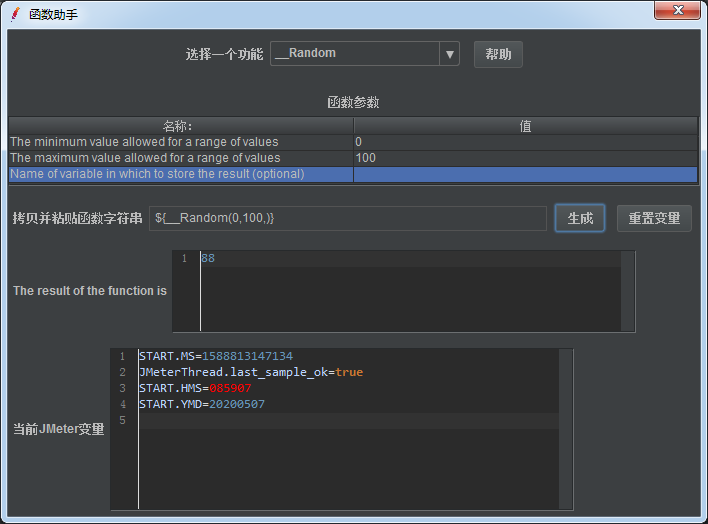
1)函数助手对话框选择一个功能:__Random
作用:生成一个区间的随机数,如图
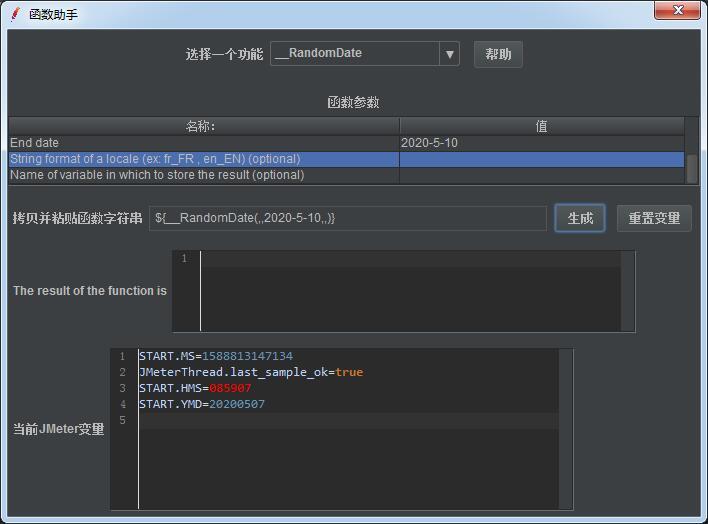
2)函数助手对话框选择一个功能:__RandomDate
作用:随机生成一个范围内的时间日期
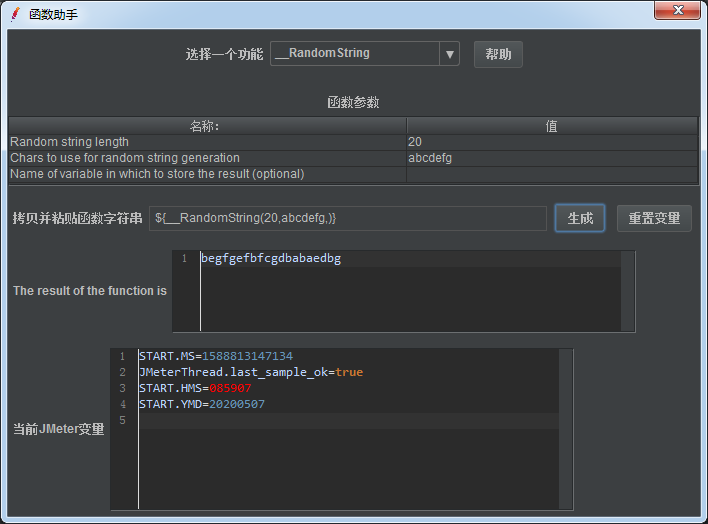
3)函数助手对话框选择一个功能:__RandomString
作用:随机生成一个字符串
五.从数据库中获取数据
1.下载jar包
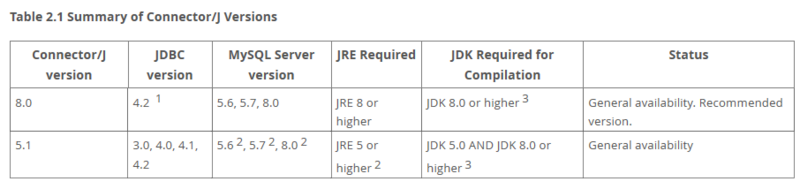
1)查看mysql版本
下载mysql jar包,在数据库客户端执行以下sql查询
SELECT version();
2)查看jar包支持的mysql版本:http://dev.mysql.com/doc/connector-j/en/connector-j-versions.html
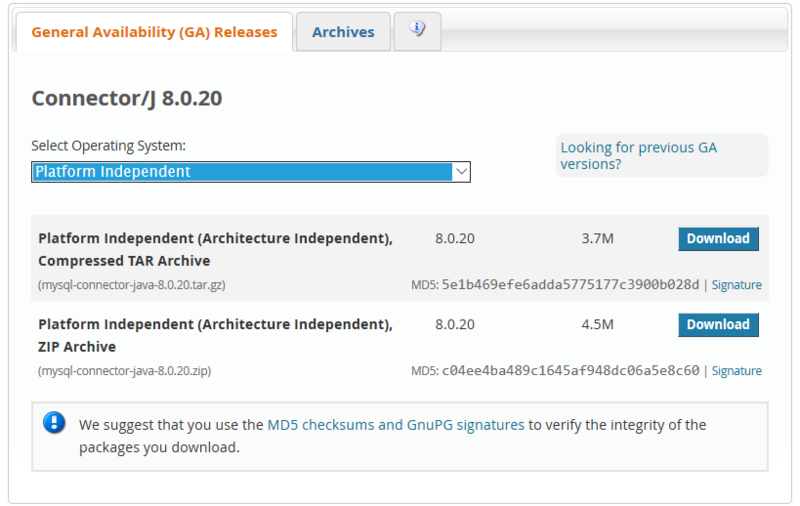
3)官网下载地址:
https://dev.mysql.com/downloa...
选择“Platform independent”
4)将jar包放在jmeter安装目录的lib目录下
2.添加JDBC Connection Configuration
添加-配置元件-JDBC Connection Configuration
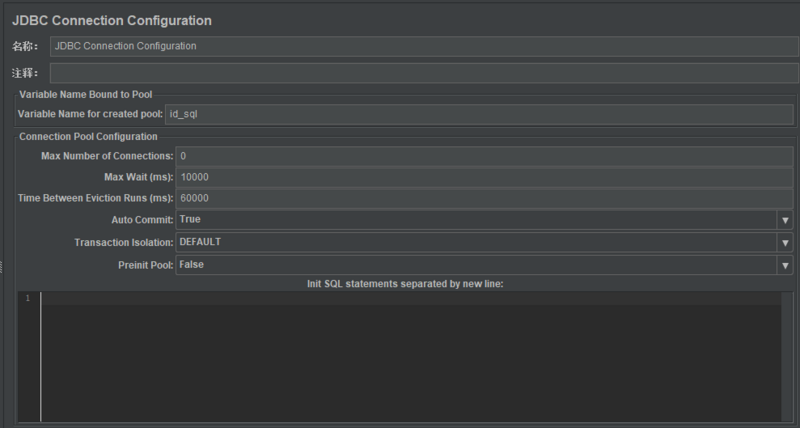
3.配置项JDBC Connection Configuration
1)名称:自定义
2)Variable Name Bound to Pool
* Variable Name for created pool:填入一个变量名,需要和JDBC request、JDBC PreProcessor、JDBC PostProcessor中的变量名一致。
3)Connection Pool Configuration:数据库连接池的配置,一般默认即可
* Max Number of Connections:数据库最大连接数
* Max Wait(ms):数据库连接最长等待时长
* Time between Eviction Runs(ms):当前连接池中某个连接在该设置空闲时间后没有被使用,将被物理关闭
* Auto Commit:自动提交。有三个选项,true、false、编辑(自己通过jmeter提供的函数设置)
* Transaction Isolation:事务间隔级别设置,主要有以下几个选项:
* TRANSACTION_NODE 事务节点
* TRANSACTION_READ_UNCOMMITTED 事务未提交读
* TRANSACTION_READ_COMMITTED 事务已提交读
* TRANSACTION_SERIALIZABLE 事务序列化
* DEFAULT 默认
* TRANSACTION_REPEATABLE_READ 事务重复读
* 编辑
* Preinit Pool:
4)Init SQL Statemnets separated by new line
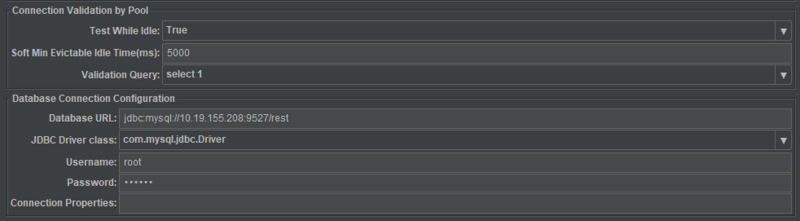
5)Connection Validation by pool
* Test While Idle:当空闲时测试连接是否断开
* Soft Min Evictable Idle Time(ms):至少在池中保持连接的时长
* Validation Query:一般选择select 1
6)database Connection Configuration
* Database URL:jdbc:mysql://mysql\_host\_ip:mysql\_port/mysql\_db\_name
* JDBC Driver class:com.mysql.jdbc.Driver
* Username:数据库用户名
* Password:数据库密码
* Connection Properties:
注释:
MySQL
com.mysql.jdbc.Driver
jdbc:mysql://host:port/{dbname}
PostgreSQL
org.postgresql.Driver
jdbc:postgresql:{dbname}
Oracle
oracle.jdbc.OracleDriver
jdbc:oracle:thin:user/pass@//host:port/service
Ingres (2006)
com.ingres.jdbc.IngresDriver
jdbc:ingres://host:port/db[;attr=value]
MSSQL
com.microsoft.sqlserver.jdbc.SQLServerDriver
jdbc:sqlserver://IP:1433;databaseName=DBname
或者
net.sourceforge.jtds.jdbc.Driver
jdbc:jtds:sqlserver://localhost:1433/"+"library"
4.添加JDBC Request
添加-取样器-JDBC Request
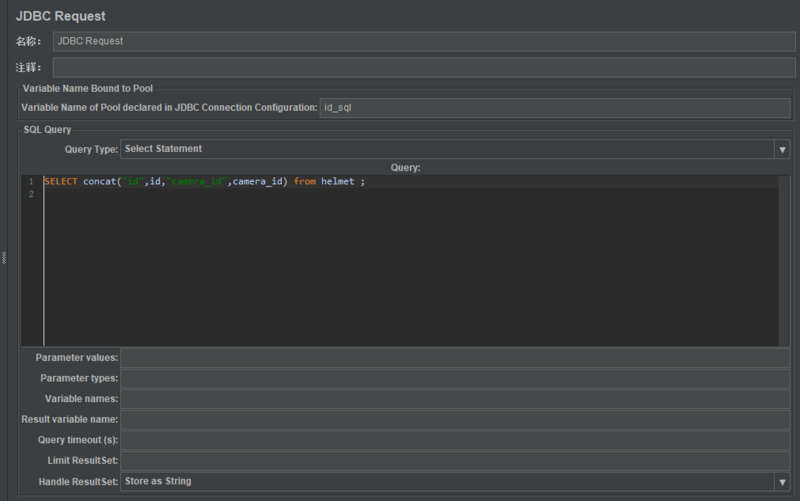
5.配置JDBC Request
1)Variable Name Bound to Pool
Variable Name of Pool declared in JDBC Connection Configuration:数据库连接池的名称,设置与JDBC Connection Configuration的Variable Name for created pool一致
2)SQL Query
Query Type:Select Statement
Query:填写的sql语句
Parameter values:参数值
Parameter types:参数类型
Variable names:保存sql语句返回结果的变量名
Result variable name:创建一个对象变量,保存所有返回的结果
Query timeout(s):查询超时时间
Limit ResultSet:
Handle ResultSet:定义如何处理由callable statements语句返回的结果
6.添加正则表达式
添加-后置处理器-正则表达式提取器
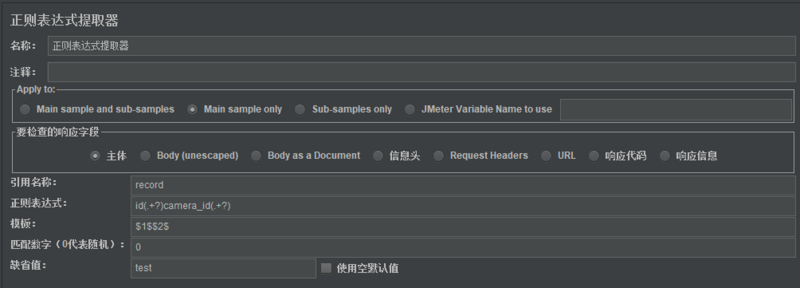
从接口返回体中获取返回值,用于下一个接口的请求参数
7.配置正则表达式
1)引用名称:在HTTP等请求中,引用此数据,需要用到的名称。
2)正则表达式:用于将需要的数据提取出来,()里面的内容是需要提取的,.表示匹配任何字符串,+表示匹配一次或多次,?表示在找到第一个匹配项后停止。
3)模板:表示使用提取到的第几个值,$-1$:表示取所有值,$0$:表示随机取值,$1$:表示取第1个,$2$:表示取第二个,以此类推:$n$:表示取第n个。
4)匹配数字(0代表随机):0 代表随机取值,1 代表全部取值。
5)缺省值:如果正则表达式没有搜找到值,则使用此缺省值,null表示为空。
8.正则表达式使用方法
&{name_gN}表示第N括号中的内容
9.添加http请求
添加-取样器-HTTP请求
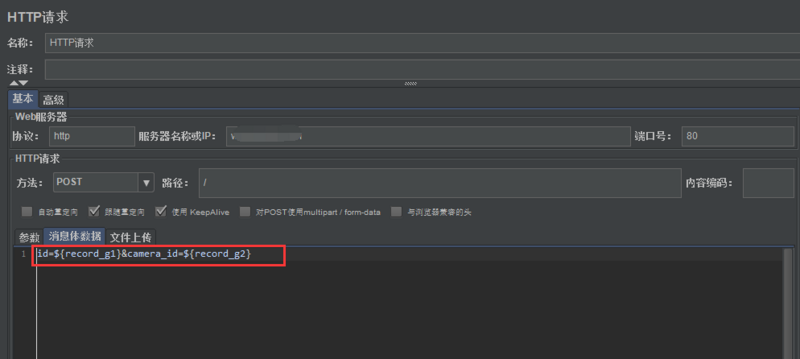
9.添加查看结果树
添加-监听器-查看结果树
执行后结果如下:
六.计数器
1.添加计数器
添加-配置元件-计数器
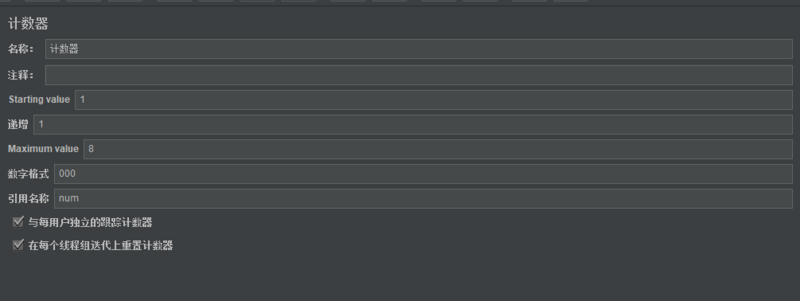
2.配置项
1)名称:自定义
2)Starting value:起始值
3)递增:每次迭代增加的值
4)Maximum value:最大值,达到最大值后,重新设置为初始值,默认的最大值为Long.MAX_VALUE,2^63-1(如果持续压测,建议最好不要设置最大值)
5)数字格式:可选格式,比如000,格式化为001,002;默认格式为Long.toString(),但是默认格式下,还是可以当作数字使用。
6)引用名称:用于控制在其它元素中引用该值,形式:$(reference_name}
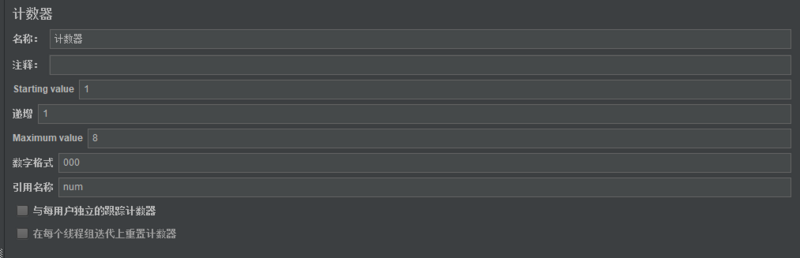
7)与每用户独立的跟踪计数器:全局的计数器,如果不勾选,即全局的,所有用户统一按照计数器循环;如果勾选,即独立的,则每个用户按照计数器循环。
8)每次迭代复原计数器:可选,仅勾选与每用户独立的跟踪计数器时可用;如果勾选,则每次线程组迭代,都会重置计数器的值。
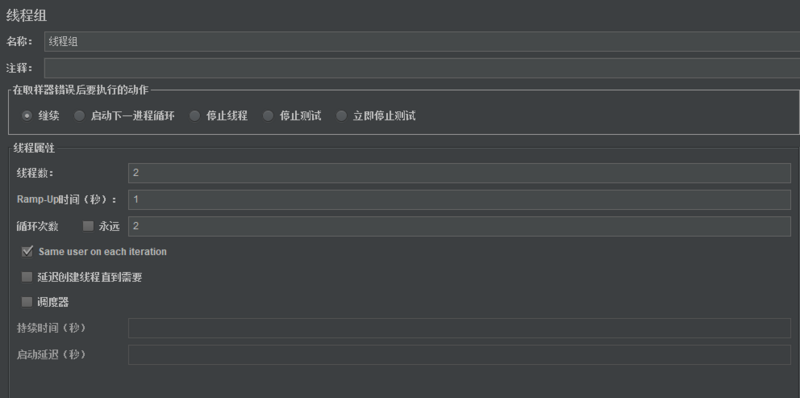
3.实例
1)场景设置
2)结果
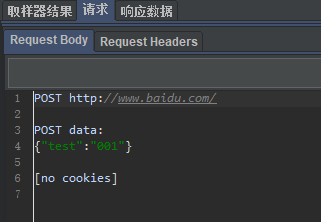
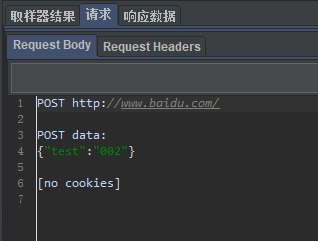
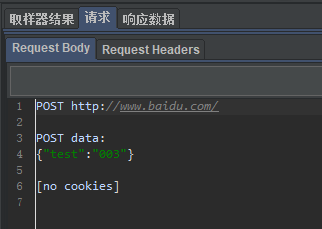
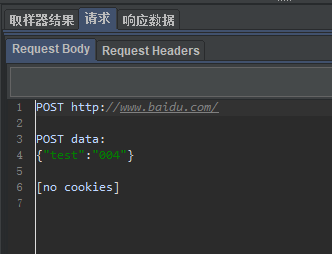














 1593
1593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









