






了解您的查询计划
自从Spark 2.x以来,由于SQL和声明性DataFrame API,在Spark中查询数据已成为一种奢侈。 仅使用几行高级代码就可以表达非常复杂的逻辑并执行复杂的转换。 API的最大好处是用户无需考虑执行问题,而可以让优化器找出执行查询的最有效方法。 有效的查询执行通常是一个要求,不仅因为资源可能变得昂贵,而且还通过减少最终用户等待计算结果的时间,使最终用户的工作更加舒适。
Spark SQL优化器确实已经相当成熟,尤其是在即将发布的3.0版本中,它将引入一些新的内部优化功能,例如动态分区修剪和自适应查询执行。 优化器在内部使用查询计划,通常可以简化查询并通过各种规则进行优化。 例如,它可以更改某些转换的顺序,或者如果最终输出不需要它们,则可以完全删除它们。 尽管进行了所有聪明的优化,但是在某些情况下,人脑仍可以做得更好。 在本文中,我们将研究其中一种情况,并了解如何通过简单的技巧使Spark朝着更有效的执行方向发展。
该代码在当前版本为2.4.5的Spark中进行了测试(编写于2020年6月),并针对Spark 3.0.0-preview2进行了检查,以查看即将到来的Spark 3.0的可能更改。
型号范例
现在让我首先介绍一个简单的例子,我们将尝试实现有效的执行。 假设我们有json格式的数据,其结构如下:
{"id": 1, "user_id": 100, "price": 50}{"id": 2, "user_id": 100, "price": 200}{"id": 3, "user_id": 101, "price": 120}{"id": 4, "price": 120}每个记录都像一个事务,因此user_id列可能包含很多重复的值(可能包括空值),除了这三列之外,还可以有许多其他字段来描述事务。 现在,我们的查询将基于两个相似聚合的并集,其中每个聚合在某些情况下会有所不同。 在第一个聚合中,我们要选择价格总和小于50的用户,在第二个聚合中,我们要选择价格总和大于100的用户。此外,在第二个聚合中,我们只考虑 记录user_id不为null的地方。 这个模型示例只是实践中可能发生的更复杂情况的简化版本,为简单起见,我们将在本文中使用它。 这是一种使用PySpark的DataFrame API表示这种查询的基本方式(非常相似,我们也可以使用Scala API编写该查询):
df = spark.read.json(data_path)df_small = ( df .groupBy("user_id") .agg(sum("price").alias("price")) .filter(col("price") < 50))df_big = ( df .filter(col("user_id").isNotNull()) .groupBy("user_id") .agg(sum("price").alias("price")) .filter(col("price") > 100) )result = df_small.union(df_big)解释计划
为查询实现良好性能的关键是能够理解和解释查询计划。 可以通过调用Spark DataFrame上的explain函数来显示计划本身,或者如果查询已经在运行(或已完成),我们还可以转到Spark UI并在SQL选项卡中找到计划。
SQL选项卡包含集群中已完成和正在运行的查询的列表,因此通过选择查询,我们将看到物理计划的图形表示(此处,我删除了指标信息以使图变小):
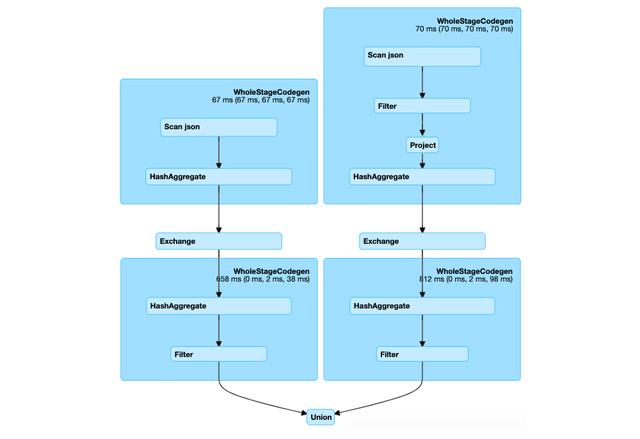
该计划具有树形结构,其中每个节点代表一些运算符,这些运算符包含一些有关执行的信息。 我们可以看到在示例中,有两个分支,其根在底部,叶在顶部,开始执行。 叶子Scan json表示从源中读取数据,然后有一对HashAggregate运算符负责聚合,在它们之间存在代表随机播放的Exchange。 过滤器运算符携带有关过滤条件的信息。
该计划具有典型的联合操作形状,联合中的每个DataFrame都有一个新分支,并且由于在我们的示例中,两个DataFrame都基于相同的数据源,因此这意味着该数据源将被扫描两次。 现在我们可以看到仍有改进的空间。 仅对数据源进行一次扫描可以带来很好的优化效果,尤其是在I / O昂贵的情况下。
从概念上讲,我们要在这里实现的是重用一些计算-扫描数据并计算聚合,因为这些操作在两个DataFrame中都是相同的,并且原则上只计算一次就足够了。
快取
如何在Spark中重用计算的一种典型方法是使用缓存。 可以在DataFrame上调用函数缓存:
df.cache()这是一个懒惰的转换,这意味着在我们调用某些操作后,数据将被放入缓存层。 缓存是Spark中使用的非常普遍的技术,但是它有其局限性,尤其是在缓存的数据很大且群集上的资源有限的情况下。 还需要注意的是,将数据存储在缓存层(内存或磁盘)中会带来一些额外的开销,并且操作本身并非免费的。 从整个DataFrame df调用缓存也不是最佳选择,原因是它会尝试将所有列都放入内存,而这可能是不必要的。 更谨慎的方法是选择将在以下查询中使用的所有列的超集,然后在此选择之后调用缓存函数。
交换重用
除了缓存之外,还有另一种文献中没有很好描述的技术,该技术基于重用Exchange。 Exchange运算符表示随机播放,它是群集上的物理数据移动。当必须重新组织(重新分区)数据时通常会发生这种情况,而聚合,联接和其他一些转换通常需要这些数据。随机播放的重要之处在于,当对数据进行重新分区时,Spark始终会在进行随机播放写入时将其保存在磁盘上(这是内部行为,不受最终用户的控制)。并且由于它已保存在磁盘上,因此以后可以根据需要重新使用。如果发现机会,Spark确实会重用数据。每当Spark检测到从叶节点到Exchange的同一分支在计划中的某处重复时,就会发生这种情况。如果存在这种情况,则意味着这些重复的分支表示相同的计算,因此仅计算一次然后重用它就足够了。我们可以从计划中识别出Spark是否找到了这种情况,因为这些分支将像这样合并在一起:
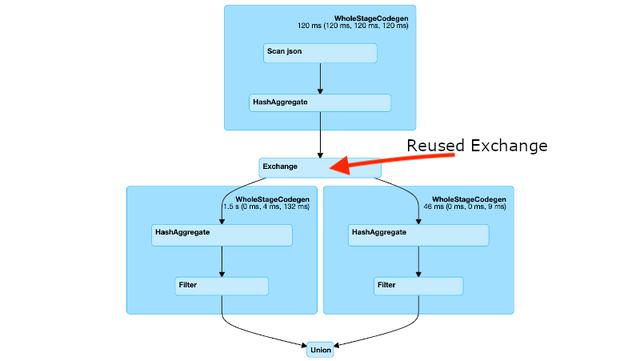
在我们的示例中,Spark没有重用Exchange,但是通过一个简单的技巧,我们可以促使他这样做。 不能在我们的查询中重用Exchange的原因是右分支中的过滤器与过滤条件user_id不为null。 过滤器确实是我们两个数据帧中唯一的区别,因此,如果我们可以消除这种区别并使两个分支相同,Spark将负责其余部分并重用Exchange。
调整计划
我们如何使分支相同? 好吧,如果唯一的区别是过滤器,那么我们当然可以切换转换的顺序,并在聚合之后调用过滤器,因为这不会影响所产生结果的正确性。 但是有一个陷阱! 如果我们这样移动过滤器:
df_big = ( df.groupBy("user_id") .agg(sum("price").alias("price")) .filter(col("price") > 100) .filter(col("price").isNotNull()))并检查最终查询计划,我们将发现该计划根本没有改变! 解释很简单-优化器将过滤器移回了。
从概念上讲,最好了解查询计划有两种主要类型:逻辑计划和物理计划。 逻辑计划在变成物理计划(即将要执行的最终计划)之前经历优化阶段。 当我们更改某些转换时,它会反映在逻辑计划中,但随后我们将失去对后续步骤的控制。 优化器将应用一组优化规则,这些规则主要基于某些启发式算法。 与我们的示例相关的规则称为PushDownPredicate,该规则可确保尽快应用过滤器并将其推向源头。 基于这样的思想,首先过滤数据,然后对精简后的数据集进行计算,效率更高。 该规则在大多数情况下确实非常有用,但是在这种情况下,它正在与我们作战。
要在计划中实现过滤器的自定义位置,我们必须限制优化器。 自Spark 2.4起,这是可能的,因为存在一个配置设置,该设置使我们可以列出要从优化器中排除的所有优化规则:
spark.conf.set("spark.sql.optimizer.excludedRules", "org.apache.spark.sql.catalyst.optimizer.PushDownPredicate")设置此配置并再次运行查询后,我们将看到过滤器现在保持在所需的位置。 这两个分支实际上是相同的,Spark现在将重用Exchange! 现在,仅对数据集进行一次扫描,并且对聚合进行同样的处理。
在Spark 3.0中,情况有所改变,优化规则现在有了一个不同的名称-PushDownPredicates,并且还有一个附加规则还负责推送过滤器PushPredicateThroughNonJoin,因此我们实际上需要同时将它们都排除在外 目标。
最后的想法
我们可以看到,通过这种技术,Spark开发人员使我们能够控制优化器。 但是权力也伴随着责任。 让我们列出使用此技术时要牢记的几点:
· 当我们停止PushDownPredicate时,我们将负责查询中的所有过滤器,而不仅仅是我们要重新定位的过滤器。 可能还有其他重要的过滤器要尽快进行,例如分区过滤器,因此我们需要确保它们的位置正确。
· 限制优化器并维护过滤器是用户方面的一些额外工作,因此值得这样做。 在我们的模型示例中,可能会在I / O开销很大的情况下加快查询速度,因为我们将实现仅对数据进行一次扫描。 如果数据集具有很多列,则对于非列格式的文件格式(例如json或csv)可能就是这种情况。
· 同样,如果数据集很小,则可能不值得花更多的精力来控制优化器,因为简单的缓存就可以完成工作。 但是,当数据集很大时,将数据存储在缓存层中的开销将变得显而易见。 另一方面,重用的Exchange将不会带来任何额外的开销,因为无论如何计算的混洗都将存储在磁盘上。
· 该技术基于Spark的内部行为,该行为没有官方文档,如果此功能发生更改,则可能很难找到它。 在我们的示例中,我们可以看到Spark 3.0中实际上有一个更改,其中一个规则被重命名,而另一个规则被添加。
结论
我们已经看到,要获得最佳性能可能需要了解查询计划。 通过使用一组启发式规则优化我们的查询,Spark优化器可以很好地完成工作。 但是,在某些情况下,这些规则会错过最佳配置。 有时重写查询就足够了,但有时却不能,因为通过重写查询,我们将获得不同的逻辑计划,但是我们无法直接控制将要执行的物理计划。 从Spark 2.4开始,我们可以使用排除规则的配置设置,该设置允许我们限制优化器,从而将Spark导航到更自定义的物理计划。
在许多情况下,依靠优化器将导致制定具有相当高效执行力的可靠计划,但是,在大多数情况下,关键性能工作负载尤为重要,因此有必要检查最终计划并看看我们是否可以通过采用该计划来改进它。 控制优化器。
(本文翻译自David Vrba的文章《Be in charge of Query Execution in Spark SQL》,参考:https://towardsdatascience.com/be-in-charge-of-query-execution-in-spark-sql-c83d1e16b9b8)















 7232
7232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









